1 引言
在当今的科技时代,机器学习已成为各个领域不可或缺的工具,推动了许多行业的变革与发展。数据在机器学习模型的训练中扮演着核心角色,其重要性不容忽视。模型的性能和预测准确性在很大程度上依赖于所使用的数据集的质量和特征。因此,理解数据的重要性及其对模型性能的影响,对于提升机器学习的可解释性和可用性具有重要意义。
近年来的研究表明,个别数据样本对模型的影响是异质的,某些数据样本在提升模型效用和整体效果方面表现出更高的贡献。这种数据重要性的差异不仅影响模型的性能,还可能影响模型的安全性。尤其是高重要性数据样本,因其在模型训练中的关键作用,是否更容易受到攻击成为一个亟待探讨的问题。
在医疗诊断等领域,某些患者记录可能包含稀有但高度指示性的症状,这些记录被视为高重要性样本。评估这些记录是否更容易受到攻击至关重要,因为数据泄露可能导致歧视、保险费用上升或其他严重后果。因此,理解数据重要性与机器学习攻击之间的关系,不仅具有理论意义,也具有重要的实际应用价值。
本研究旨在深入探讨数据重要性与机器学习攻击之间的关系,重点分析高重要性数据样本是否面临更高的攻击风险。通过对五种不同类型的攻击进行分析,研究将揭示高重要性样本在不同攻击场景下的脆弱性,为未来的防御机制提供理论依据和实践指导。
2 背景
在机器学习领域,模型的构建和训练依赖于大量的数据。数据的重要性不仅影响模型的性能,还对模型的安全性产生深远的影响。本节将介绍机器学习模型的基本概念,并详细探讨数据重要性的定义及其评估方法。
2.1 机器学习模型
机器学习算法的目标是构建能够有效预测输出的模型。这些模型通常由一个参数化函数表示,记作 ( f_{\Theta}:\mathcal{X}\rightarrow\mathcal{Y} ),其中 ( \mathcal{X} ) 表示输入空间,( \mathcal{Y} ) 表示输出空间,涵盖所有可能的预测。确定最优参数值 ( \Theta ) 的过程涉及通过梯度下降最小化目标函数。具体而言,目标是最小化分类损失:
其中 ( (x,y)\in\mathcal{X}\times\mathcal{Y} ) 表示用于训练目标模型的训练数据集中的样本。这个优化过程通过迭代调整参数,引导模型实现最佳性能。
2.2 数据重要性
在机器学习中,评估单个训练样本的重要性是一个基本而复杂的问题,具有广泛的影响,尤其是在数据估值方面。理解单个训练样本在学习任务中的重要性,对数据评估、资源分配和机器学习模型的质量都有深远的影响。
留一法(Leave-one-out, LOO)长期以来被视为评估数据样本重要性的直观方法。形式上,设 ( D ) 和 ( D_{\mathrm{val}} ) 分别表示训练集和验证集,( \mathcal{A} ) 表示学习算法。( U_{\mathcal{A},D_{\mathrm{val}}} ) 表示在 ( D ) 上训练的模型在验证集上的准确性。目标样本 ( z ) 的重要性可以通过将目标样本纳入训练集前后的效用差异来量化,表达为:
然而,评估训练集中所有 ( N ) 个样本的重要性需要重新训练模型 ( N ) 次,导致计算负担沉重。为了解决这一限制,Koh 和 Liang 提出了影响函数作为一种近似方法,显著降低了计算成本,从 ( O(N p{2}+p{3}) ) 降至 ( O(N p) ),其中 ( p ) 表示模型参数的数量。
尽管 LOO 方法有效,Ghorbani 和 Zou 提出了对其能力的担忧,认为其无法捕捉数据子集之间的复杂交互。他们认为,Shapley 值提供了一个更全面的框架来衡量数据的重要性。Shapley 值最初由 Shapley 提出,为训练集中的每个样本 ( z ) 分配一个重要性值,使用以下公式:
为了简化对每个样本分配的 Shapley 值的解释,可以将其视为在典型场景中的准确性贡献。例如,在一个假设场景中,100 个样本的模型实现了 90% 的准确性,一个有价值的样本可能贡献 2% 的准确性,而一个不太重要的样本可能仅贡献 0.1%。因此,分配给有价值样本的重要性值为 0.02,而不太重要样本的重要性值为 0.001。重要性为 0 的样本表示对模型准确性没有贡献,而小于 0 的值则表明可能由于标签错误或样本超出分布而产生的负面影响。
Shapley 值考虑了训练集中所有可能子集的贡献,提供了对数据重要性的更全面评估。然而,基于定义公式准确计算 Shapley 值需要训练 ( O(2^{N}) ) 个机器学习模型,这使得在复杂数据集上变得不切实际。因此,现有方法采用近似算法来估计 Shapley 值。例如,Ghorbani 和 Zou 提出了两种基于蒙特卡洛的方法来近似 Shapley 值。为了加快评估时间并使大数据集的分析成为可能,Jia 等人利用 ( K )-最近邻(KNN)算法来近似目标学习算法,将时间复杂度降低到 ( \mathcal{O}(N\log N) )。
通过以上讨论,可以看出数据的重要性在机器学习模型的训练和评估中扮演着至关重要的角色。理解数据的重要性不仅有助于提升模型性能,还能为数据隐私和安全性提供新的视角。
3 评估设置
在本研究中,作者采用了KNN-Shapley方法来评估样本的重要性。选择这一方法的原因主要基于两个方面:效用和可扩展性。
首先,从效用的角度来看,传统的数据归因方法在处理数据子集之间的复杂交互时存在一定的局限性。以往的研究表明,留一法(Leave-One-Out, LOO)虽然直观,但在捕捉数据样本之间的复杂关系时效果不佳。因此,作者选择了Shapley值作为一种更为全面的评估框架,以便更准确地量化数据的重要性。Shapley值考虑了所有可能的训练集子集的贡献,提供了对数据重要性的更全面评估。
其次,从可扩展性的角度来看,许多测量方法在计算效率上表现不佳。例如,使用留一法计算CIFAR10数据集的样本重要性需要超过80小时的计算时间,而Shapley值方法通常更为耗时。相较之下,KNN-Shapley方法在计算效率上表现优越,能够在较短的时间内处理大规模数据集。根据Jia等人的研究,KNN-Shapley方法的运行时间复杂度为(O(N \log N)),使其成为进行实验的唯一可行方法。
在数据集的选择上,作者使用了三个广泛使用的基准数据集:CIFAR10、CelebA和Tiny Image Net。CIFAR10包含60,000张彩色图像,均匀分布在十个类别中,代表日常生活中常见的物体。CelebA是一个大规模的人脸数据集,包含超过40个标注的二元属性。为了确保分析的平衡性,作者遵循了先前的研究,选择了三个最平衡的属性(Heavy Makeup、Mouth Slightly Open和Smiling)来创建一个8类分类任务。此外,Tiny Image Net是ImageNet数据集的一个子集,包含200个不同的物体类别,每个类别有500张训练图像。
通过对样本重要性的评估,作者能够深入理解高重要性和低重要性数据之间的学习特征差异。这一评估为后续的机器学习攻击实验提供了基础,确保了研究结果的可靠性和有效性。
4 会员推断攻击
会员推断攻击(Membership Inference Attack, MIA)是一种常见的隐私攻击,旨在确定特定数据样本是否属于训练数据集。该攻击因其简单性和广泛适用性而被广泛应用于评估训练数据的隐私性。在攻击场景中,攻击者获得对目标模型的访问权限,并试图判断给定数据样本的会员状态。
攻击流程
会员推断攻击的流程可以被视为一个安全游戏,具体步骤如下:
- 挑战者从数据分布中抽取训练数据集 (D) 并训练模型 (f_{\Theta} \gets \mathcal{T}(D))。
- 挑战者随机选择一个比特 (b),如果 (b=0),则从分布中抽取一个新样本 ((x,y) \gets \mathbb{D})(确保 ((x,y) \notin D));否则,从训练集中选择一个样本 ((x,y) \stackrel{\mathfrak{S}}{\leftarrow} D)。
- 挑战者将样本 ((x,y)) 发送给攻击者。
- 攻击者获得对分布 (\mathbb{D}) 和模型 (f_{\Theta}) 的查询访问权限,并输出一个比特 (\hat{b} \gets \mathcal{A}^{\mathbb{D},f}(x,y))。
- 输出 1 如果 (\hat{b}=b),否则输出 0。
攻击者通常会利用辅助信息来提高攻击的成功率。攻击的准确性可以通过以下公式定义:
高重要性样本的脆弱性
在本研究中,作者探讨了高重要性样本在会员推断攻击中的脆弱性。通过对 CIFAR10 和 CelebA 数据集的实验,发现高重要性样本在低假阳性率区域表现出更高的脆弱性。例如,在 CIFAR10 数据集中,当假阳性率(FPR)为 1% 时,高重要性样本的真实阳性率(TPR)是低重要性样本的 10.2 倍。这一发现表明,高重要性样本在会员推断攻击中面临显著的隐私风险。
隐私洋葱效应
隐私洋葱效应(Privacy Onion Effect)是指在移除最脆弱的样本后,新的脆弱样本会暴露出来。研究表明,当高重要性样本被移除时,原本被认为不重要的样本会获得更高的重要性。这一现象在本研究中得到了验证,移除高重要性样本后,剩余样本的重要性分布发生了显著变化。
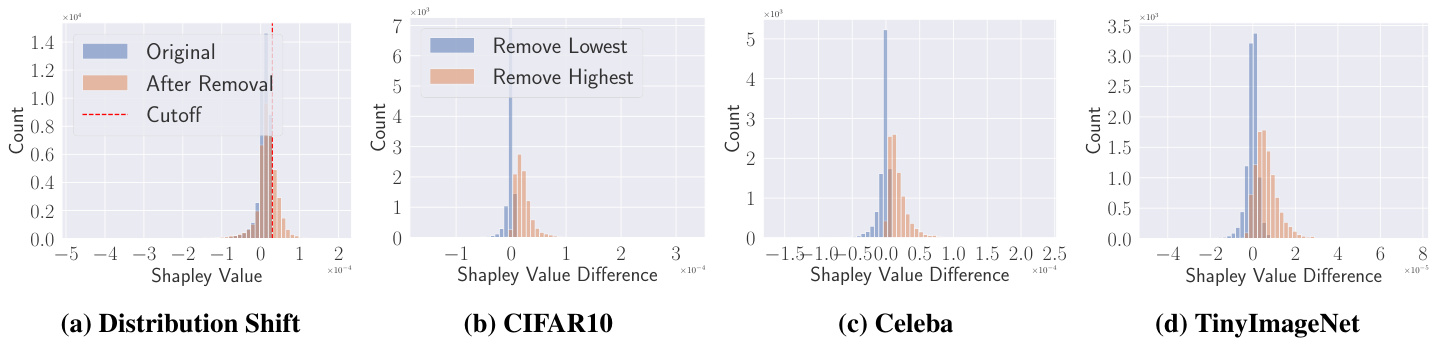
改进攻击性能的方法
为了提高会员推断攻击的效率,作者提出了一种基于样本特定标准的方法。通过引入与样本特征相关的阈值,攻击者可以更有效地进行攻击。具体而言,作者提出了以下公式来重新校准会员推断指标:
其中,(\mathtt{O r i M e m}(x)) 是传统的会员指标,(\mathtt{S h a p l e y}(x)) 是特定样本的 Shapley 值。通过调整超参数 (k),实验结果表明,结合重要性校准显著提高了攻击的效率。

结论
本节的研究结果表明,高重要性样本在会员推断攻击中表现出显著的脆弱性,尤其是在低假阳性率区域。隐私洋葱效应的存在进一步强调了高重要性样本的隐私风险。通过引入样本特定标准,攻击者可以有效提升攻击性能。这些发现为未来的隐私审计和防御机制提供了重要的参考。
5 模型窃取
模型窃取攻击是一种旨在获取目标模型机密性的攻击方式,其主要目标是创建一个能够模拟目标模型功能的替代模型。与会员推断攻击不同,模型窃取攻击并不直接利用训练样本的隐私信息,而是通过查询目标模型的输出,试图重建一个与目标模型相似的模型。这种攻击可以被恶意行为者用于多种目的,包括经济利益或作为后续攻击的前奏。
5.1 相同分布查询
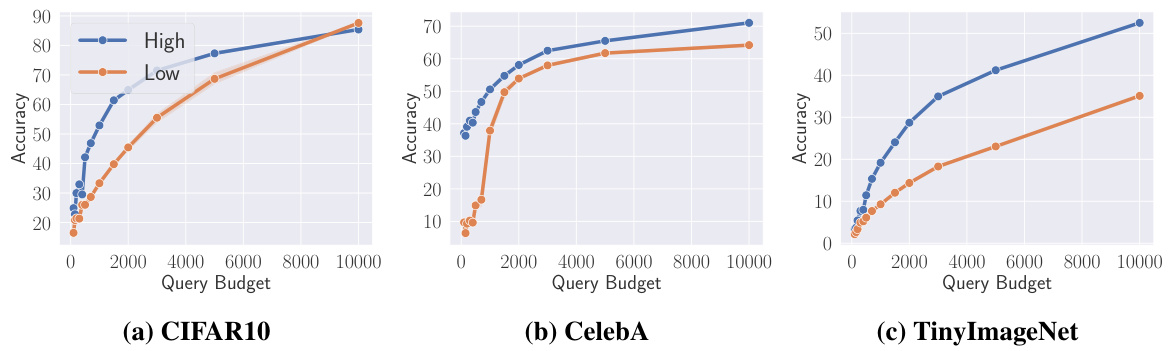
在本研究中,作者首先探讨了在相同分布下进行模型窃取攻击的效率。为此,研究者训练了三个目标模型,分别在CIFAR10、CelebA和Tiny Image Net数据集上进行训练,测试准确率分别为95.15%、79.05%和65.01%。在攻击过程中,研究者设定了从100到10,000的查询预算,并优先收集高重要性数据,直到预算耗尽。
攻击结果如图11所示,显示高重要性样本在模型窃取过程中的效率显著高于低重要性样本。例如,当查询预算设定为1000时,高重要性数据能够以53.77%的准确率窃取CIFAR10模型,而低重要性数据仅能达到33.29%的准确率。这一趋势在其他两个数据集上也得到了验证,尤其是在Tiny Image Net数据集中,高重要性数据的窃取准确率为19.25%,而低重要性数据仅为9.25%,显示出2.1倍的差异。
这一差异的一个可能解释是,高重要性样本在查询集中的类平衡性较好。尽管研究者对高和低重要性样本的分布进行了分析,发现两者在类分布上并无显著差异,但高重要性样本的选择可能更能代表目标模型的特征,从而提高了窃取效率。
5.2 不同分布查询
接下来,研究者探讨了在不同分布下进行模型窃取攻击的效果。具体而言,研究者使用CIFAR10模型作为目标模型,并用CelebA和Tiny Image Net数据集进行查询。结果如图12所示,研究者发现高重要性样本在跨任务场景中的优势消失。在相同的查询预算下,高和低重要性样本的窃取准确率相近,这表明样本在一个任务中被认为重要的特征并不能有效转移到其他任务中。
小结
本节的研究结果表明,高重要性样本在相同分布查询中展现出更高的模型窃取效率,且这种效率并非仅仅由于分布偏差所致。研究者指出,当攻击者了解目标任务时,可以利用高重要性样本来优化攻击性能,从而减少查询预算。然而,这一结论在目标任务与查询分布不一致的情况下并不成立,表明在不同任务中选择高重要性样本作为“通用”查询集并不可行。
6 后门攻击
后门攻击是一种训练时攻击,旨在通过干扰训练过程来操控模型的行为。其主要目标是使模型在正常输入下表现得像一个良性模型,但在检测到特定触发器时,故意将输入错误分类为预定类别。这种攻击可能导致模型的完整性和可靠性受到严重威胁,从而引发潜在的安全漏洞、数据操控或未经授权访问敏感信息。
在后门攻击的背景下,毒化率(poison rate)扮演着关键角色,因为它直接影响攻击的有效性和隐蔽性。较高的毒化率可能导致攻击成功率的增加,但也会提高被检测的风险,因为需要修改大量样本。相反,较低的毒化率可能提供更好的隐蔽性,但可能无法实现最佳的攻击性能。此外,在某些情况下,攻击者可能只能控制少量样本,这使得在有限的样本数量下进行有效的毒化成为一个有趣且具有挑战性的问题。
本节将通过实证研究探讨不同重要性水平样本的毒化对攻击性能的影响。我们采用两个指标来评估攻击性能:
-
准确性:该指标评估后门模型与干净模型之间的偏差。我们测量后门模型在干净数据集上的表现,成功的攻击应使得模型的准确性接近干净模型,从而难以被检测。
-
攻击成功率(ASR):该指标评估后门模型的功能性,并在触发数据集上进行测量。理想的后门模型应在所有触发样本中表现出高ASR,表明其能够将所有触发样本错误分类为目标标签。
通过分析这些指标,我们旨在深入了解数据重要性对攻击性能的影响,并进一步理解后门攻击中攻击有效性与隐蔽性之间的权衡。
在本部分中,我们采用与BadNets相同的方法对模型进行后门攻击,具体的超参数细节见附录G。此外,我们还验证了我们的结论在其他五种后门攻击中的普遍性,这些攻击使用不同的触发模式或针对不同的学习范式,详细讨论见附录I。
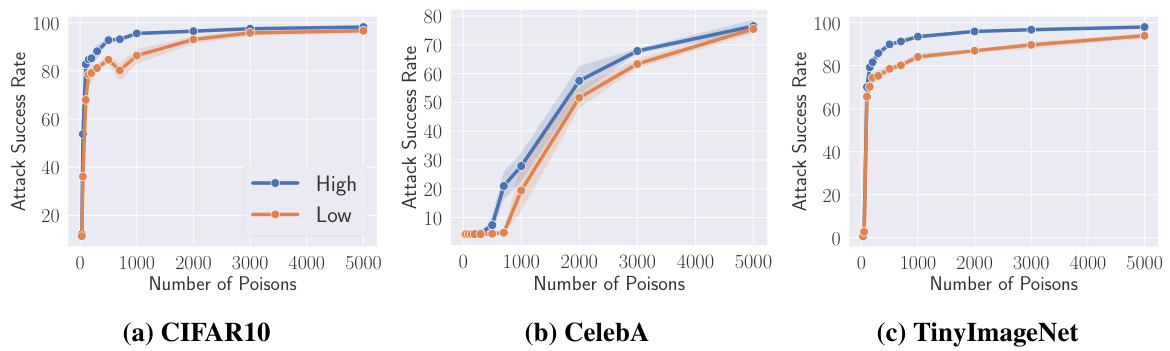
我们在图13中展示了攻击成功率的可视化结果。图中显示,随着毒化样本数量的增加,攻击成功率显著提高。同时,我们观察到高重要性样本与低重要性样本之间的显著差异。具体而言,毒化相同数量的高重要性样本在提高攻击成功率方面比毒化低重要性样本更为有效。这种现象在毒化率较小时尤为明显。例如,在CIFAR10数据集中,当毒化样本数量为50时,毒化高重要性数据的模型ASR为54.42%,而毒化低重要性数据的模型ASR仅为37.74%,显示出1.44倍的优势。类似的趋势也在其他两个数据集中得到了验证。
然而,当毒化率较高时,差异并不显著。我们认为这是由于重要性优势与攻击上限之间的权衡。随着毒化样本数量的增加,使用高重要性数据的优势变得更加明显。然而,实现后门攻击的最佳ASR并不需要大量数据。通常,毒化约10%的数据集就足够。因此,随着毒化样本数量的增加,高重要性和低重要性样本之间的差距会缩小。然而,仍然观察到毒化高重要性样本需要毒化更少的样本以实现其最佳ASR。
在攻击者对数据的访问有限的情况下,确定样本的真实重要性可能具有挑战性,这影响了选择性毒化高重要性样本的可行性。在这种情况下,我们实证证明,仅使用训练集的一小部分计算重要性值可以很好地近似真实重要性。例如,仅使用2%的CIFAR10数据,计算出的重要性值与整个数据集的相关性系数为0.811±0.016。随着数据量的增加,这些近似的准确性也在提高:使用5%的数据时,相关性系数上升至0.899±0.006,而使用20%的数据时,超过0.96。这些结果表明,即使在数据访问有限的情况下,近似样本的重要性也是可行的,从而为在现实约束下有效的攻击规划提供了便利。
此外,我们对清洁准确性的影响进行了调查,未发现样本重要性水平对清洁准确性有显著影响。在这两种情况下,重要性样本的毒化对清洁准确性的影响均保持在2%以下,表明后门攻击的隐蔽性。
综上所述,我们的实验证明,毒化高重要性样本能够提高毒化过程的效率,尤其是在毒化率较低的情况下。这一发现为在有限数据访问情况下开发攻击策略提供了宝贵的指导。除了优化有效注入的触发模式外,优先毒化高重要性样本也成为一种有前景的方法。
7 属性推断攻击
属性推断攻击是一种隐私攻击,旨在推断与机器学习模型原始任务无直接关系的敏感属性。例如,一个训练用于预测年龄的模型可能无意中学习到预测种族的能力。这种攻击对隐私和公平性具有重要影响,因为敏感属性的意外泄露可能导致隐私权的侵犯、潜在的歧视以及对机器学习系统的信任破坏。
在本研究中,研究者关注于一个常见的攻击场景,其中攻击者利用从目标模型获得的目标样本嵌入来预测其敏感属性。攻击者假设对训练数据集有辅助信息,并从相似分布中收集一个影子数据集。他们训练一个影子模型以模仿目标模型的行为,并使用嵌入和敏感属性来训练攻击分类器。
为评估攻击性能,研究者使用相对准确度作为指标,比较准确度与随机猜测基线的差异,后者因CelebA数据集的分布不均而有所不同。实验结果显示,数据重要性与属性推断攻击的成功率之间没有显著关联。例如,“弓形眉毛”属性在高重要性样本中容易被推断,而“高颧骨”属性仅能在低重要性样本中推断。此外,“嘴巴微微张开”属性在中等重要性样本中表现出最明显的推断脆弱性。这些结果表明,数据重要性与属性推断攻击之间并不存在显著的相关性。
一个可能的解释是,数据样本的重要性值可能因预测任务而异。换句话说,某些特征或属性的重要性在不同的预测任务中可能有所不同。例如,虽然胡须可能是预测性别的重要特征,但在预测收入时可能重要性较低。研究者通过在附录F中可视化不同属性的重要性值之间的相关性进一步验证了这一推测,结果表明,样本在一个属性上的高重要性可能与其在另一个属性上的重要性不一致。
综上所述,研究者的发现表明,数据样本的重要性与攻击性能之间并没有简单的相关性,这与他们最初的假设一致。这一结果强调了在进行属性推断攻击时,考虑数据样本的重要性及其在特定任务中的变化是至关重要的。未来的研究可以进一步探讨如何在不同任务中评估和利用数据样本的重要性,以提高攻击的有效性和针对性。
8 个人评价
在这项研究中,作者深入探讨了数据重要性与机器学习攻击之间的关系,揭示了高重要性数据样本在多种攻击场景下的脆弱性。通过对五种不同类型的攻击进行分析,研究表明,高重要性样本在会员推断攻击和模型窃取攻击中表现出显著的脆弱性。这一发现不仅为理解数据在机器学习模型中的作用提供了新的视角,也为未来的安全防护措施提出了重要的启示。
主要贡献
-
数据重要性与攻击脆弱性的关联:研究通过实证分析,确认了高重要性样本在会员推断攻击中的高脆弱性,尤其是在低假阳性率区域。具体而言,在CIFAR10数据集中,高重要性样本的真实阳性率(TPR)在1%的假阳性率(FPR)下比低重要性样本高出10.2倍。这一结果强调了在设计安全防护机制时,必须考虑数据样本的重要性。
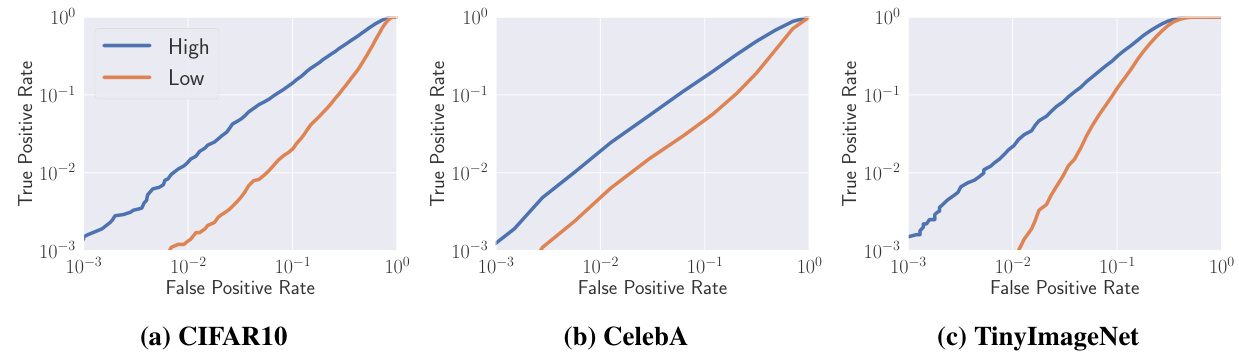
-
隐私洋葱效应的扩展:研究进一步扩展了隐私洋葱效应的概念,表明当高重要性样本被移除时,低重要性样本的相对重要性会增加。这一发现提示研究者在进行隐私审计时,需考虑样本的重要性分布。
-
模型窃取攻击的效率:在模型窃取攻击中,研究发现高重要性样本在相同分布查询中的效率显著高于低重要性样本。这一结果表明,攻击者在选择查询样本时,应优先考虑高重要性样本,以提高攻击的成功率。
-
后门攻击的影响:研究还探讨了后门攻击中高重要性样本的影响,发现对高重要性样本的污染能够显著提高攻击成功率。这一发现为设计更有效的攻击策略提供了理论基础。
-
属性推断攻击的复杂性:在属性推断攻击中,研究表明数据重要性与攻击成功率之间并没有显著的相关性。这一结果强调了在不同任务下,样本重要性的变化可能会影响攻击的效果。
未来研究方向
基于本研究的发现,未来的研究可以集中在以下几个方面:
- 防御机制的开发:针对高重要性样本的脆弱性,研究者应探索创新的防御机制,以平衡模型的效用与数据的安全性。
- 样本重要性动态调整:研究如何动态调整样本的重要性,以提高模型的鲁棒性和安全性。
- 跨任务攻击的研究:进一步探讨在不同任务之间,样本重要性如何影响攻击效果,以便为设计更有效的攻击和防御策略提供指导。
总之,本研究为理解数据重要性在机器学习攻击中的作用提供了重要的理论基础,并为未来的研究指明了方向。