动机
随着人们对语音情感标注(Speech Emotion Captioning, SEC)研究的逐步深入,识别和描述语音情感的能力在提高沟通效率和理解说话者意图方面显得至关重要。传统的情感识别方法多将情绪分类为固定类别,如悲伤、愤怒和快乐,而这种单一分类的方式往往无法精准捕捉复杂的情感信息,因为一段话中可能同时包含多种情绪。此外,情感标注的主观性也使得不同标注者对同一语音的情感结果可能存在较大差异,这导致了标注模糊性问题。
为了更好地描述语音中的情感,研究者们开始尝试使用自然语言代替情感类别标签,从而更准确地表示情感。先前的工作如SECap首次提出了以自然语言描述语音情感的框架,结合音频编码器和语言模型生成情感描述。然而,现有的SEC方法在处理未见语音时往往会出现幻觉,产生与真实情感不符的描述,且对语音输入的生成缺乏泛化能力。
为了解决以上问题,AlignCap被提出作为一种新的SEC框架,旨在生成丰富且连贯的情感描述,同时确保与语音情感的一致性。AlignCap主要通过两个关键属性实现:一是通过知识蒸馏优化实现语音文本对齐,降低语音和文本输入的响应预测分布之间的差异;二是通过偏好优化正则化消除模型生成的事实性和可信度幻觉。此外,该方法提取情感线索作为提示,以丰富细粒度信息,从而提升在零样本任务下的表现。
总之,AlignCap的创新之处在于首次通过人类偏好对SEC模型进行对齐,克服了传统SEC方法的局限性,提升了情感描述的质量和一致性,并在实验中显示出优于其他最先进方法的性能。

方法
AlignCap的方法由两部分组成:KD-Regularization(知识蒸馏正则化)和PO-Regularization(偏好优化正则化),旨在实现语音文本对齐和人类偏好的对齐。
KD-Regularization
在KD-Regularization中,AlignCap通过设计一个学生LLM(大语言模型)来实现语音Token到文本生成。具体做法是将教师LLM的响应用于指导学生LLM的下一Token生成。选择了LLaMA-7B作为教师LLM,其参数保持不变。学生LLM通过LoRA(低秩适应)进行微调。
声学提示
模型首先构建一个情感线索的词汇表,识别声调、语调、音高、节奏和音量等情感线索。设计了一种情感语法解析器,通过过滤这些线索生成声学提示 ,提示模板为 <Feeling $e_{1},e_{2},\ldots$, $e_{n}$>。
其中,是一系列的标题,是第个标题。通过将情感线索插入模板中的索引位置,生成声学提示。
文本Token生成
将语音-标题对中的标题称为语义提示,然后将和连接作为前缀提示,提供给LLM,以条件化其后续生成的语音情感标题。生成下一个Token的概率计算如下:
此过程迭代进行,直到LLM生成包含句号的Token。接着,选择下一个Token:
PO-Regularization
PO-Regularization旨在提升输出的情感描述质量,确保其一致性和合理性。为了解决LLM响应不一致(即事实幻觉和信实幻觉)的问题,AlignCap构建了一个偏好对数据集,通过GPT-3.5评分提示 ,利用LLM的束搜索解码输出生成偏好对:
偏好优化通过直接优化LLM的策略模型,最大化偏好反馈。
知识蒸馏
在知识蒸馏中,给定一组语音-标题对,使用KL散度作为度量,定义教师分布和学生分布之间的关系:
通过最小化这个损失,AlignCap学习到用于语音输入的学生LLM,使其生成行为与文本输入相似。
模态对齐
AlignCap使用模态适配器将语音编码器的特征压缩到共享的编码空间。通过对输入语音Token和文本Token进行填充和遮罩,以确保模型专注于有效的Token,仅在相应的Token序列之间建立对齐。
框架图
AlignCap的整体框架如图所示:

AlignCap通过以上设计有效解决了语音情感标注中的对齐问题,提供了一种新型的情感描述生成方法。
实验
在本研究中,作者提出了一种新的框架AlignCap,以实现语音情感标注(SEC)任务的评估,以及该框架在零样本情况下的表现。实验分为几个部分,包括数据集、设置、主要结果和消融实验等。
数据集
作者选择了大规模视频情感推理数据集MER2023中的语音-字幕配对样本,形成MER23SEC数据集。同时,使用了中文交互多模态情感语料库NNIME,以评估模型在其他数据集上的迁移能力。由于缺乏公开可用的高质量SEC任务数据集,作者还提出了一个新的数据集EMOSEC,该数据集包含约41小时的中英文语音情感标注,涵盖45039个句子。
设置
在评估指标方面,研究者使用GPT-3.5评估生成的情感线索与摘要状态的重叠程度,以此来评价生成字幕的质量。自动评估指标包括BLEU、METEOR、ROUGE-L、CIDEr和SPICE等,具体用于评估情感一致性和生成的情感描述的质量。
作者将AlignCap与多种基线系统进行比较,基线系统包括HTSAT-BART、NoAudioCap和SECap。这些比较经过多次实验,验证了AlignCap在不同指标上的性能表现。
主要结果
在零样本场景下,AlignCap展示了在NNIME和EMOSEC数据集上的性能显著优于其他基线模型。表中的数据表明,AlignCap-KD-PO在所有度量上均优于其他模型,尤其是在情感线索的准确性和描述的丰富性方面。
表格1显示了不同SEC方法在NNIME和EMOSEC中的零样本评估结果:
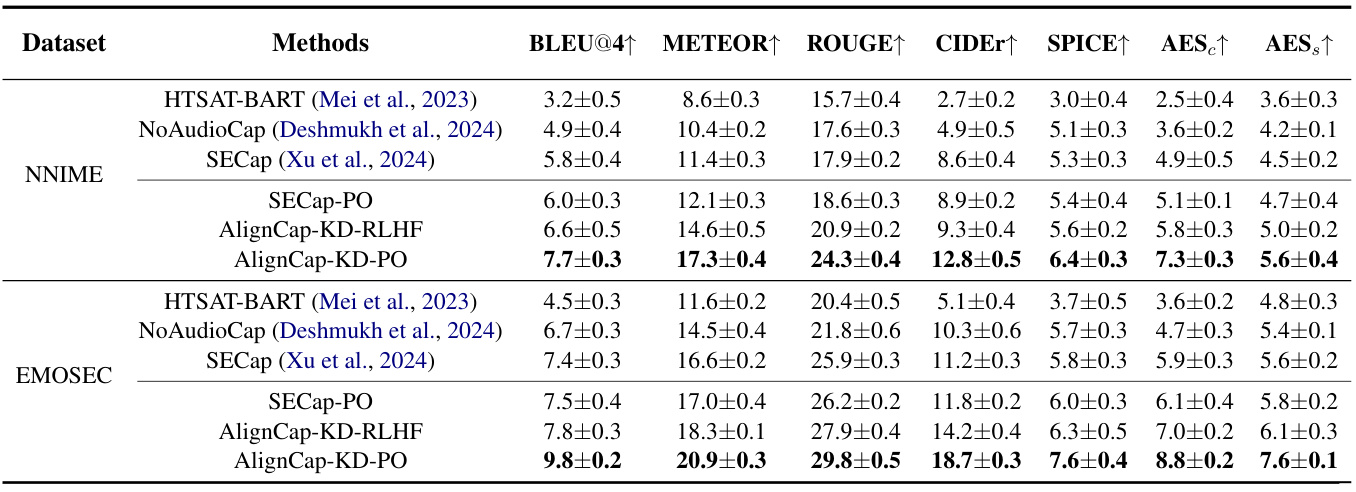
定量评估结果表明,AlignCap的偏好优化(PO-Regularization)能有效消除模型生成中的虚假信息。这表明AlignCap通过引入偏好优化,能够生成更加符合人类偏好的情感描述。
消融实验
在消融实验部分,作者逐步移除AlignCap中的特定组件,以评估这些组件对消除幻觉和丰富细腻信息的影响。表格2展示了不同组件的效果对比:
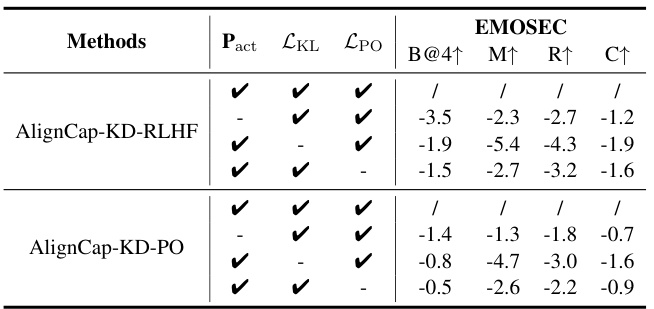
各个指标的显著下降,表明情感线索提取(P_{act})、KD-Regularization(\mathcal{L}{KL})和PO-Regularization(\mathcal{L}{PO})在生成过程中至关重要。
此外,作者还探讨了不同的语音-文本对齐方法对下游SEC任务的影响。这些实验表明,AlignCap在各个指标上都优于其他对齐方法,强调了其在生成过程中处理信息的能力。
迁移能力分析
作者进一步在跨领域场景中评估AlignCap,使用EMOSEC的训练集对其他数据集进行测试,表3展示了相关结果。
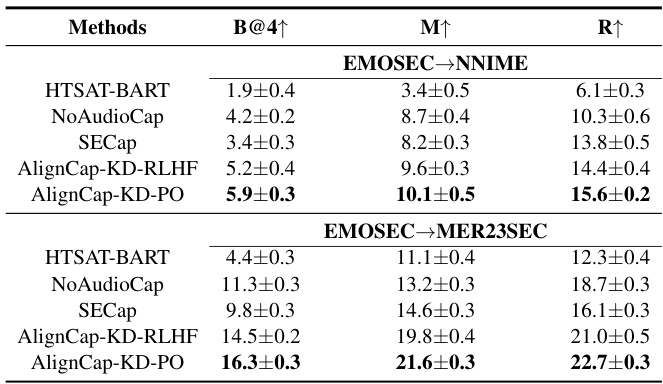
实验结果表明,AlignCap在跨领域任务中的表现优于所有基线模型,显示了其强大的迁移能力和在不同数据集间的适应性。
结果总结
实验部分显示了AlignCap在各种测试条件下的优越性,包括零样本和跨领域测试。这些结果加强了AlignCap在情感标注的实用性和有效性。
结论
AlignCap框架通过实现语音与文本的对齐以及人类偏好的对齐,展示了其在生成语音情感描述方面的优势。为最小化LLM对语音输入与其对应的文本输入的响应分布之间的差异,研究者们设计了KD-Regularization,从而实现了语音-文本对齐。此外,AlignCap通过PO-Regularization将情感描述与人类偏好相对齐,有效消除了在未见语音上产生的事实与忠诚度幻觉。实验证明,在零样本及跨领域场景下,AlignCap的表现优于其他方法,并且显示了其良好的泛化能力。这一成果标志着在情感描述生成的研究中,AlignCap可以成为一个有效的框架,为进一步的研究和应用奠定基础。