动机
在机器学习领域,尤其是大型语言模型(LMs)的开发中,如何有效地收集和利用人类反馈以实现人类偏好的对齐是一项重要的研究方向。目前,基于人类反馈的强化学习(RLHF)被广泛应用于大规模语言模型的训练,以此提升模型的输出质量。然而,直接收集人类的偏好数据通常是一项代价高昂且耗时的任务,且其结果的方差可能较大。这使得仅依靠人类注释在效率和成本方面存在一定的局限性。
为了解决这一问题,研究者们开始关注从语言模型生成的偏好注释作为合成标注的替代方案。这种方法的优点在于具有较低的成本和可扩展性。然而,基于语言模型的偏好注释往往存在偏见和错误,从而影响其质量。因此,如何在人工和自动生成的偏好之间找到合适的平衡成为了一个亟待解决的挑战。
本文中,研究者提出了一种新的路由框架,该框架通过组合人类和LM的输入,旨在提高偏好注释的质量,并减少人工注释的总体成本。该方法的核心在于识别那些能从人类注释中受益的偏好实例,从而优化注释的选择过程。这一研究不仅为更高效的偏好数据收集提供了新的思路,也为提升LM在不同上下文中的表现奠定了基础。
如同下图所示,该研究的框架展示了性能预测模型(PPM)与基于该模型的路由策略的融合。通过这一方法,研究者希望能够实现更优的模型性能,同时降低数据收集的复杂度和成本。
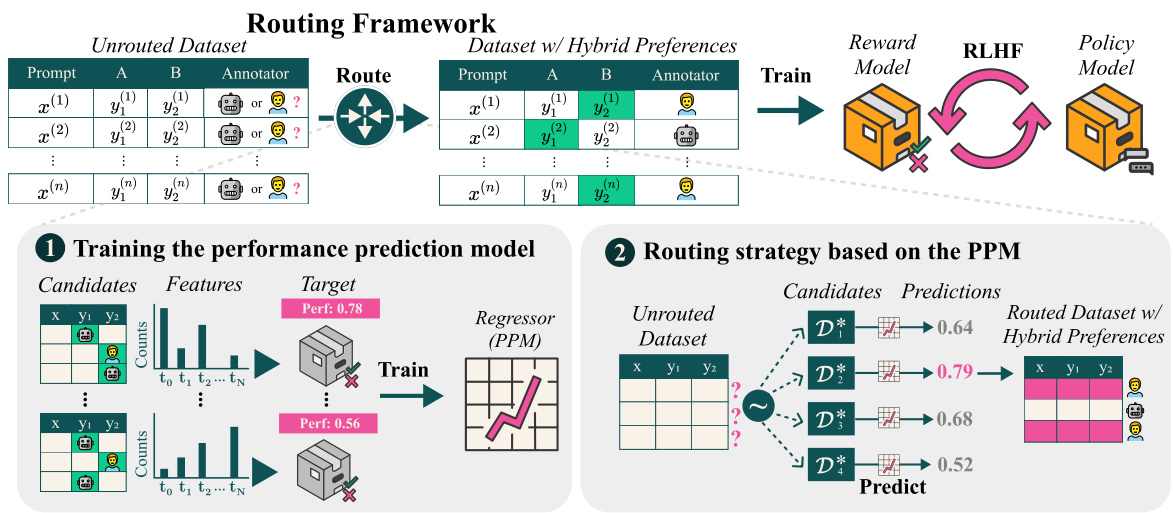
方法
问题表述
在本研究中,作者提出了一种路由框架,用于在人工标注和语言模型(LM)生成的标注之间分配偏好实例。该方法旨在识别能够从人工标注中受益的特定实例,同时将其余实例路由至LM。具体来说,研究将这一决策建立在基于奖励模型(Reward Model,RM)训练得到的性能上,以便最大化偏好数据集的性能指标。
路由问题的优化模型
设定现有的未标注偏好实例数据集为 (\mathcal{D}={\langle x{(i)},y_{1}{(i)},y_{2}{(i)}\rangle}_{i=1}{n}),其中每个实例可以从两个来源获得标注:一个是人工评注,另一个是LM生成。定义二进制决策变量 (z_{i}\in{0,1}),当(z_{i}=0)时选择人工标注,当(z_{i}=1)时选择LM生成的标注。目标是优化选择 (z_{i}) 的配置,以最大化性能指标,如下所示:
其中 (\mathrm{PERF}) 是 RM 在数据集 (\mathcal{D}(z)) 上的性能。这个优化问题并没有闭合的解析解,因此采用了模拟候选数据集的方法,利用收集到的性能数据来训练性能预测模型(PPM)。
性能预测模型(PPM)
PPM 作为回归模型,旨在为任意候选偏好数据集提供性能评估。PPM 接受作为输入的特征向量,以上面提到的路由配置统计信息构建。模型评估通过生成具有不同路由配置的候选数据集 ({\hat{\mathcal{D}}_{i}})并训练 RM 来进行性能评估。
特征空间的构建基于文本信息和描述信息的标签。文本标签主要包括响应之间的余弦相似度、提示的长度和响应的长度差等。描述标签包含与提示相关的元数据,比如所需的专业知识和用户的意图复杂度等。这些标签以实例级别提取,形成PPM的特征向量。
路由策略基于PPM
路由的目标是寻找最佳的路由配置 (z^{}={z_{1},z_{2},\ldots,z_{n}}),从而最大化奖励模型性能 (\mathrm{PERF}(\hat{\mathcal{D}}(z^{})))。使用模拟候选数据集生成大量样本后,通过PPM预测各个模拟候选的性能,从中选择性能最高的配置进行最终的路由。
实验数据集:M ULTI P REF
M ULTI P REF 数据集由10461个例子构成,包含人工和GPT-4注释。该数据集用于训练PPM,并可应用于后续的路由实验。数据集的收集来自多个开放资源,并经过专门设计的标注流程以保证数据质量,确保每个实例至少由四位评注员进行标注,采用多数表决的方式对标注结果进行整合。
路由框架概述
路由框架的整体布局如图所示:
框架包括性能预测模型(PPM)和基于该模型的路由策略。PPM 通过模拟和评估不同数据集的性能来为特定的路由配置提供性能预测,最终选择出预期表现最佳的配置。
实验
本研究的实验部分分为多个阶段,包括对性能预测模型(PPM)的评估、不同行为数据集的泛化能力测试以及如何通过路由框架改进现有的偏好学习。
PPM性能评估
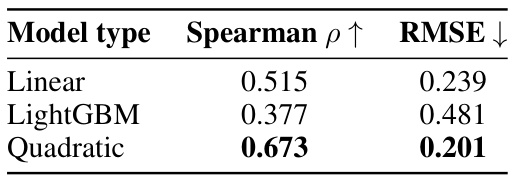
为验证PPM的拟合优度,研究者从M ULTI P REF生成了200个候选数据集,并使用Tülu 2 13B作为基础模型进行奖励模型的训练。接着,通过生成16个持出数据集来比较PPM的预测性能与奖励模型在Reward Bench上的性能。预测性能与实际性能的比较结果通过均方根误差(RMSE)和斯皮尔曼相关系数()进行评估。
图1 显示了不同回归模型的拟合效果,结果表明,二次模型的拟合优度最佳,因此后续实验中采用该模型作为PPM。
泛化到未见偏好数据集
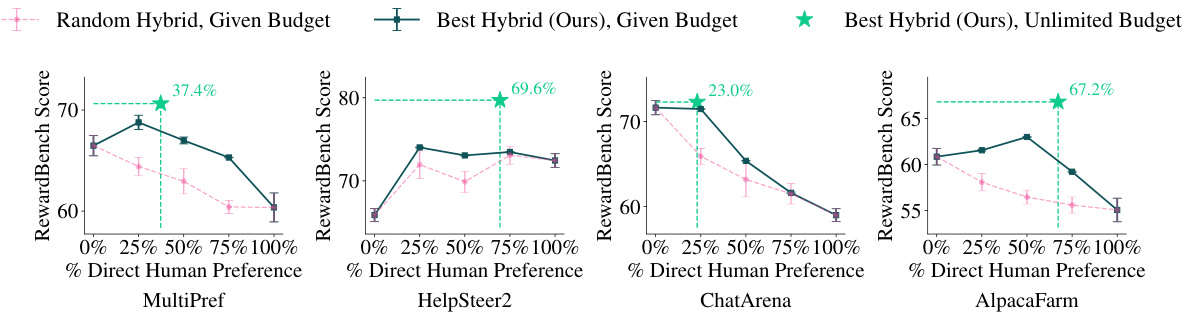
接下来,研究团队测试了基于M ULTI P REF训练的回归模型是否可以泛化到未见的偏好数据集。评估的偏好数据集包括Helpsteer2、ChatArena Conversations和AlpacaFarm Human Preferences,这些数据集均由人类标注,并添加了来自GPT-4的合成注释。
评估中,研究人员将每个未路由数据集的实例生成候选数据集,然后利用PPM选择能获得最佳性能的路由配置。最终,路由框架生成的混合注释在多个指标上均表现优于单一来源的注释。
最佳响应生成评价
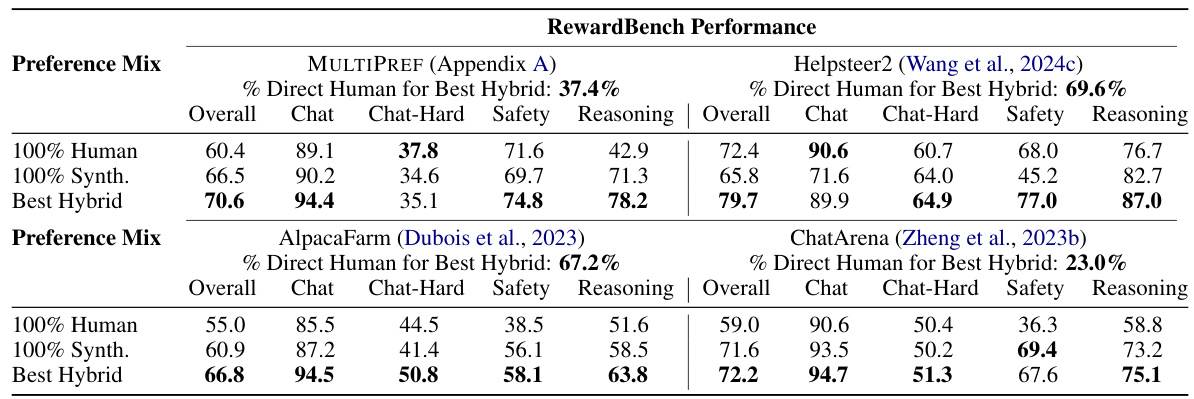
所有的评估都围绕使用“最佳-N”重排序格式,将多个生成样本通过模型评分来找出最优输出。实验使用了多个广泛应用的基准数据集,包括GSM8K(数学推理)、BIG-Bench Hard(理由推理)、IFEval(精确指令跟随)、Codex HumanEval(编程)和AlpacaEval(常规聊天能力)。表1展示了使用最佳混合偏好集的实验结果,该混合在大多数情况下均优于使用纯人类或纯合成注释的结果。
PPM分析:人类注释的有效性
为了评估人类注释的收益,研究者分析了PPM所学到的特征,以识别哪些实例更适合直接进行人类标注。通过计算对不同标签的平均收益,发现当响应之间的语义相似性处于适中水平时,实例更可能从人类注释中获益。尤其是涉及专家领域知识的实例,更倾向于从人类注释中得到更高的评分平均值。
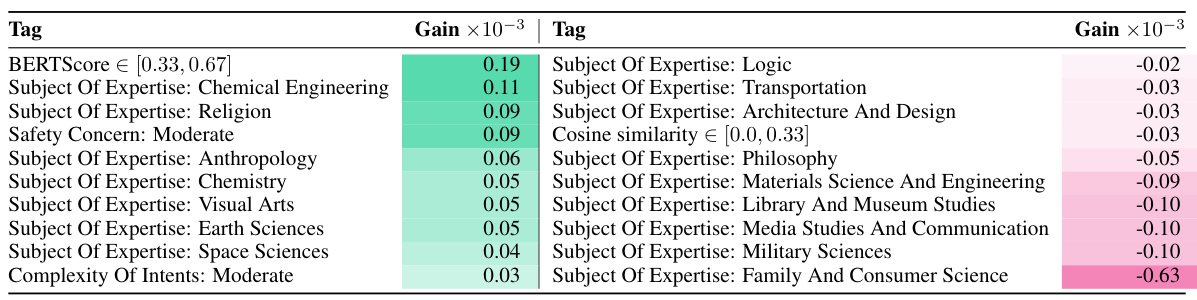
人类与AI标注者的一致性
研究还分析了人类标注者与GPT-4之间的一致性,发现对于路由到人类的实例,标注者之间的一致性得分为61.5%,而GPT-4的得分为57.8%。研究者指出,造成这种差异的原因主要包括用户指令的主观性、开放性请求中的标注差异、以及AI在某些情况下出现的偏差。
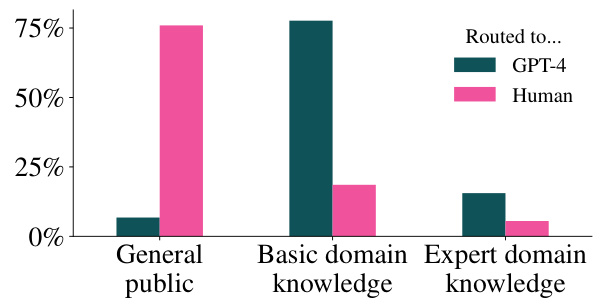
路由框架的效果评估
研究团队还利用相同的PPM训练模型,评估其在Helpsteer2-Preferences数据集上的泛化能力,发现最佳混合偏好集要求67.6%的实例路由到人类标注者。与其他数据集相比,这个数据集在100%人类注释情况下表现优越。
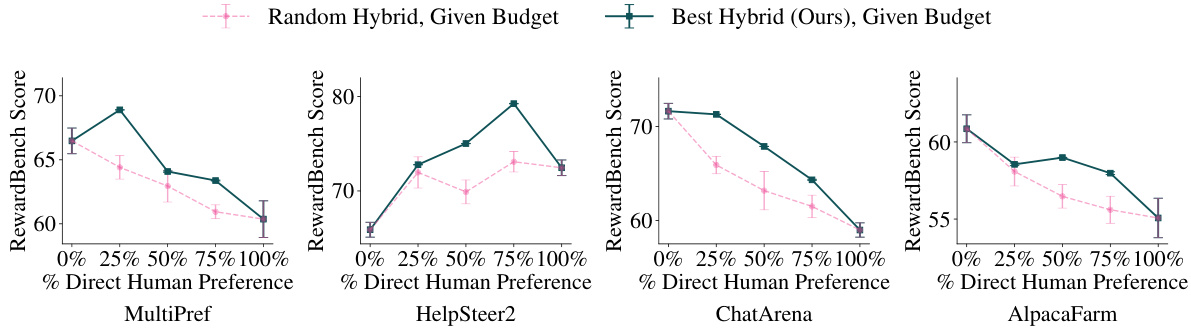
结论
本研究提出了一种用于偏好学习的路由框架,旨在将实例分配给人类注释者或语言模型(LM),通过识别出能够从人类注释中受益的子集,优化偏好注释的质量。研究结果表明,从该框架生成的混合注释在Reward Bench上的表现优于100%的人类注释和100%来自LM的注释,并且在通过最佳-N重排名的方式在常见的语言模型基准测试中也表现良好。这种路由框架能够在给定的人类注释预算中超越随机抽样的效果,证明了选择性地收集人类偏好注释的有效性。
此外,研究还揭示了影响特定实例受益于人类注释的关键特征,这些特征包括响应之间的高度相似性、需要人类专业知识的提示以及恰当地涉及的主题领域。研究结果不仅为如何有效地结合人类和LM的注释提供了新的见解,也为偏好学习提供了数据驱动的策略,展示了优化注释源使用的潜力。通过这一框架,研究人员希望为未来的偏好数据收集提供更高效的方法,最终推动人类价值和目标与大型语言模型的对齐。