动机
随着深度学习和自然语言处理技术的迅速发展,大型语言模型已成为各种应用创新的驱动力。这些模型在机器翻译、语音识别和文本生成等领域取得了显著成功。然而,训练这些大型模型通常需要巨大的计算资源和海量数据,这不仅对单一云平台的资源要求很高,还可能导致计算瓶颈、延迟问题和成本压力。在这种背景下,跨云联邦训练应运而生,提供了一种有效的解决方案。它充分利用多个云平台的计算资源,使得数据集的分布式处理和模型参数的同步更新成为可能,从而加速训练过程。
跨云联邦训练的实施面临多项关键技术挑战,包括如何高效分配和管理云平台的计算资源、优化云间的数据通信,以及如何确保训练过程中的数据隐私和安全。此外,由于不同云平台可能拥有不同的硬件架构和计算能力,实现异构环境中的兼容性也是一个重大挑战。为了解决这些问题,该研究旨在探索大型语言模型跨云联邦训练的关键技术,分析现有技术框架,提出适应大型模型的解决方案,并通过实验验证其可行性和性能。
在研究中,作者不仅提供了跨云联邦训练的技术支持,还在数据隐私保护、通信优化和模型聚合方面提出了改进方案,力图为高效训练大型语言模型提供创新性和实用性的技术思路。这些研究成果展示了跨云联邦训练的广泛应用前景。
方法
在跨云联合训练中,数据分区和分布策略是确保训练过程高效顺畅的基础。为了应对单一云平台的资源瓶颈,研究团队提出了一系列关键技术,包括数据分区、通信优化、模型聚合算法以及异构云平台的兼容性。
数据分区和分配策略
数据必须根据特定策略进行分区和分布,以优化计算资源的使用。首先,研究人员动态调整数据分区的粒度,参考模型的复杂度以及各云平台的计算能力。研究表明,较大的数据分区可以减少云平台之间的通信频率,从而提高整体计算效率,但可能会增加单个平台的计算负担。相对而言,较小的数据分区会降低单个平台的计算负担,却会增加云间通信的开销。因此,找到合适的分区大小至关重要。
在数据分布策略中,研究强调负载均衡的重要性,以防止某些平台过载。动态分配策略能够根据各平台的实时计算能力、网络带宽和当前负载进行调整,确保所有平台以最优能力运行。此外,确保数据安全是跨云联合训练中的一个关键环节。数据在分发前必须加密,采用同态加密和差分隐私技术至关重要。
以下是数据分区和分布周期的框架图,展示了这一过程的关键步骤和核心要素:
来训练一种预训练的大规模语言模型,训练数据集为 WikiText-103,并在不同的云平台上进行了分发。
在实验中,团队采用了联邦平均算法(FedAvg)、动态加权聚合算法以及梯度聚合算法来训练模型,并全面评估了每种算法的通信开销、模型收敛速度和训练准确性。实验过程详见表1。

表1:实验设置
在实验过程中,研究小组首先根据数据分区策略对训练数据集进行分区,将其分发到各个云平台。每个平台使用本地数据训练其本地子模型,然后根据选定的聚合算法更新全局模型。研究团队记录了每种算法在不同训练轮次中的通信开销、模型准确性和收敛时间,并将结果归纳在下表中。
通信开销和训练时间的不同聚合算法
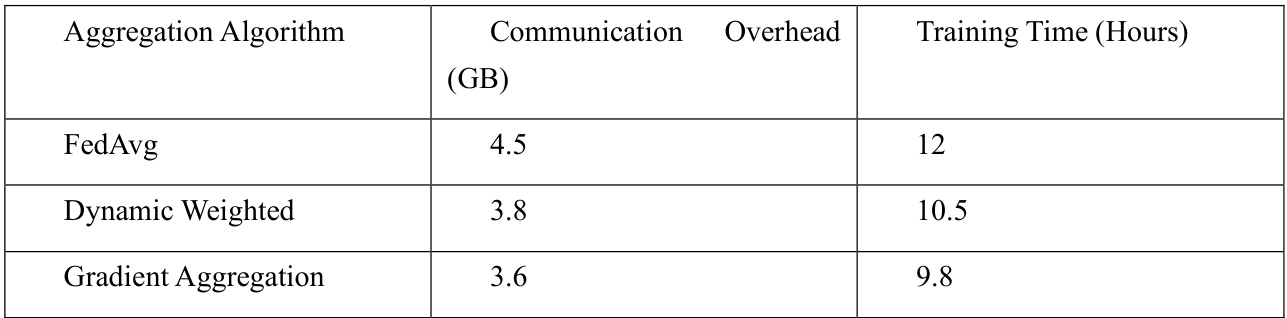
表2:不同聚合算法的通信开销和训练时间
模型收敛准确性和损失的不同聚合算法
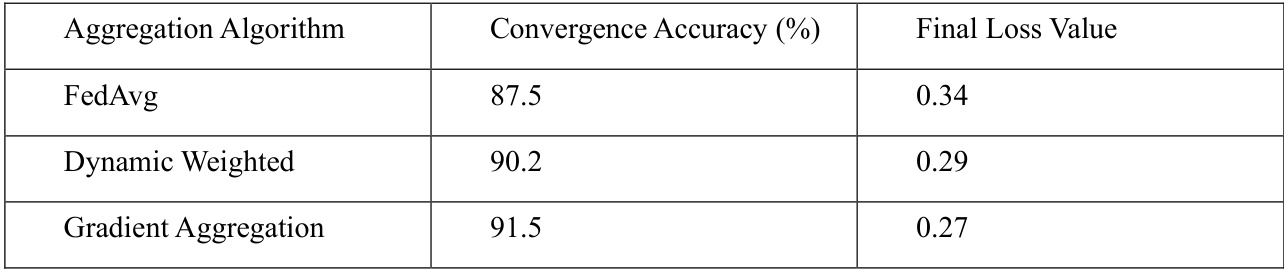
表3:不同聚合算法的模型收敛准确性和损失
实验结果表明,使用动态加权聚合算法的全局模型在经过50轮训练后收敛速度快于 FedAvg 算法,而在处理异构数据时,梯度聚合算法表现出更高的准确性。具体实验结果详见表2和表3。
通过分析表2可以看出,动态加权和梯度聚合算法在通信开销方面均优于 FedAvg,梯度聚合由于在聚合过程中数据量较小,因此表现出最少的数据传输,显著降低了通信开销和训练时间。
在表3中,梯度聚合算法展示了最高的收敛准确性和最低的损失值,表明其在处理异构数据时具有强大的适应性。动态加权聚合算法在通信开销和训练效率之间取得了良好的平衡,特别适合数据分布不均的跨云联邦训练场景。
结论
跨云联合训练大规模语言模型提供了一种有效解决单一云资源限制的方案,但也带来了计算资源、通信优化、数据隐私以及适应异构环境等多重挑战。
研究通过引入动态加权聚合、梯度聚合和异步更新等优化技术,显著提高了训练效率,减少了通信开销,并增强了全局模型的收敛准确性和性能。该研究表明,跨云联合训练不仅具有广阔的应用潜力,还为大规模语言模型的高效训练奠定了坚实的技术基础。未来,进一步优化这些关键技术将推动大规模语言模型在更广泛实际场景中的应用和发展。