动机
随着大型语言模型(LLMs)在自然语言生成领域的快速发展,它们在多项任务上展现出显著能力。然而,这些模型经常出现“幻觉”现象,即生成的内容缺乏现实基础或对事实的误表达。这种幻觉的产生威胁到其在临床决策或法律推理等高风险领域的可靠性。因此,了解LLMs幻觉的潜在机制极为重要。
研究表明,在Transformer架构中存在特定的注意力头,称为“检索头”,它们负责从给定上下文中提取相关信息。然而,尽管识别出这些机制是理解LLMs的关键,但目前为止鲜少有研究探讨如何有效地利用这些发现来减轻幻觉现象。这一研究缺口正是本文的出发点。作者提出了一种新颖的解码方法:通过对比检索头进行解码(DeCoRe),该方法基于以下假设:掩盖检索头可以引发幻觉,从而削弱模型从上下文中提取相关信息的能力。
DeCoRe通过动态对比原始LLM与掩盖检索头的变体的输出,利用条件熵作为指导,以此来减少潜在的幻觉生成。研究结果显示,DeCoRe在需要高度上下文真实性的任务中显著提升了模型表现,比如摘要生成、指令遵循和开放书籍问答等。
这一创新方法为减轻LLMs的幻觉现象提供了新的视角,创造性地将检索头的掩盖与对比解码机制结合,对于提升模型的上下文真实感和准确性具有重要意义。
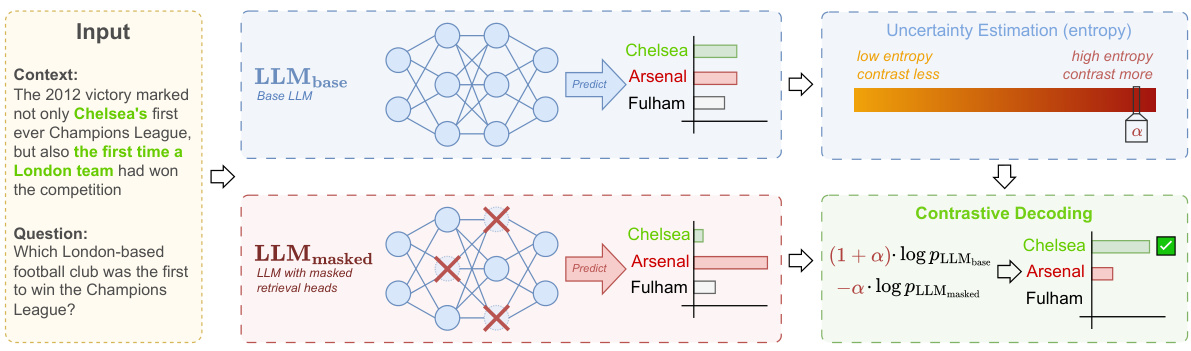
方法
DeCoRe(解码通过对比检索头)是一个新颖的解码策略,其目标是减少大语言模型(LLM)中的幻想(hallucinations),尤其是在信度和事实性方面。该方法基于假设,通过屏蔽检索头可以诱发模型幻想,并利用对比机制来增强基于输入上下文生成的响应的准确性。具体操作包括以下几个步骤:
屏蔽检索头
首先,通过屏蔽特定的检索头,DeCoRe 诱发模型产生幻想。这些检索头被定义为能够从给定上下文中提取相关信息的注意力头。研究显示,这些检索头在不同层之间起着重要作用,其作用机制可以通过分析注意力模式来识别。具体步骤包括:
- 通过分析注意力头的检索得分来选择要屏蔽的检索头。
- 设定一个掩码 ( m_{h}^{(l)} ),针对每一个头进行标识,以决定该头是否被有效使用。
掩码的定义如下:
在掩码应用后,经过屏蔽的多头注意力输出变为:
对比基础模型与屏蔽模型
为了提升生成输出的可信度,DeCoRe 采用了基础模型和屏蔽模型的对比机制。在每个步骤中,通过对基础模型与屏蔽模型的输出进行对比,来提高正确性,同时减少高度不确定性输出的可能性。对比的下一步分布可以用以下公式表示:
其中,( \alpha ) 是控制基础模型输出和屏蔽模型输出权重的超参数。
动态对比解码
DeCoRe引入了一种动态调整超参数 ( \alpha ) 的机制,使用条件熵(Conditional Entropy)作为调整依据。条件熵定义为:
高条件熵表示模型对预测结果的不确定性,DeCoRe 通过动态设置 ( \alpha = H(x_{t}) ) 来调整对比机制,确保在不确定性增加时,可能诱导幻想的生成选项不易被选择。
流程概述图
以下是 DeCoRe 工作流程的概述图:
通过这种综合方法,DeCoRe 能有效对抗 LLM 中的幻觉现象,并提升模型在需要高上下文可信度的任务中的表现。
实验
实验部分阐述了如何评估DeCoRe在减少LLM的幻觉现象方面的有效性。具体来说,实验分为两类:信实性评价和事实准确性评价,此外,还探讨了DeCoRe与链式思维(CoT)结合时的表现。
数据集和评价指标
信实性方面的评价采用了XSum、MemoTrap和开放域自然问题(NQ)等数据集。XSum是一个基于BBC文章的摘要生成数据集,MemoTrap用于测试模型是否遵循指令。开放域NQ则允许模型在处理问题时参考一个支持文档。
事实准确性评价则使用了TruthfulQA、TriviaQA、PopQA和NQ-Open数据集。TruthfulQA旨在评估模型是否能回避常见的错误,TriviaQA和PopQA则用于测试模型对琐事问题的回答能力。
模型
实验选择了Llama3家族中的Llama3-8B-Instruct和Llama3-70B-Instruct模型进行对比分析。除了这两个模型,附录中还提供了其他模型系列的结果。
基线
DeCoRe与六个基线方法进行比较,包括传统的贪心解码、对比解码(CD)、上下文感知解码(CAD)、对比层解码(DoLa)、激活解码(AD)以及训练好的推理时间干预(ITI)。其中,ITI需依赖训练标记数据,而DeCoRe及其他基线方法则为无训练方式。
DeCoRe变体
DeCoRe的三种变体被测试:DeCoRe静态(使用静态的对比因子)、DeCoRe熵(动态调整对比因子)和DeCoRe熵简化版(使用较小的LLM但相同的词汇空间)。
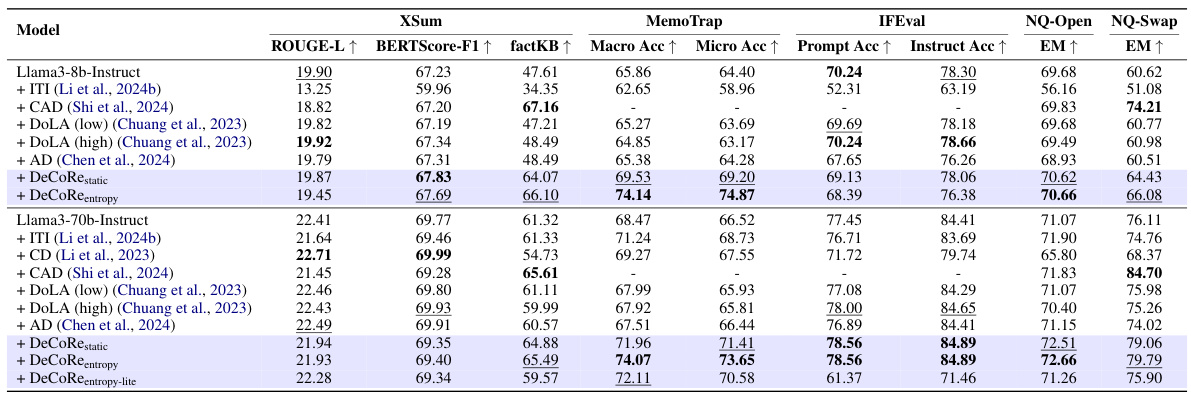
信实性评估任务
在信实性评估中,DeCoRe明显改善了基础模型在各种任务中的表现。例如,在MemoTrap测试中,DeCoRe熵取得了74.14%的宏观准确率,远超所有基线。
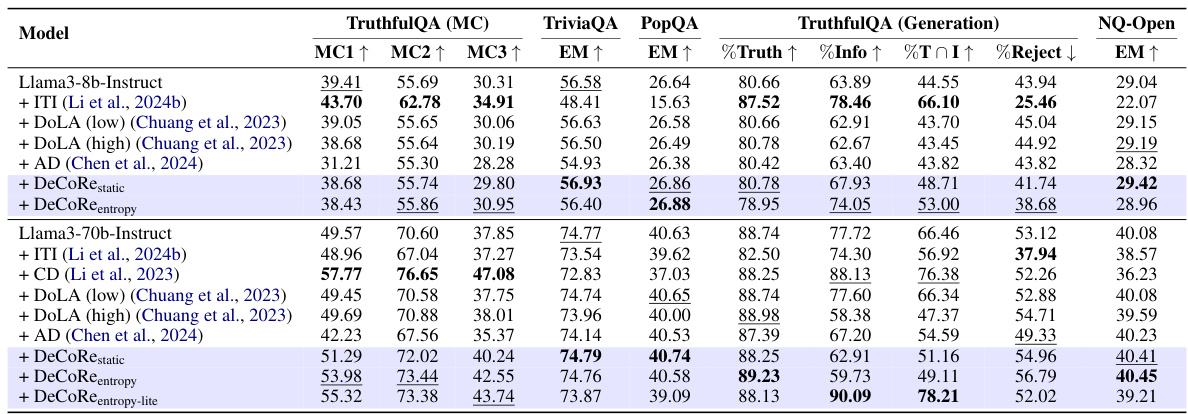
事实准确性评估任务
在事实准确性任务中,DeCoRe也显著改善了模型性能。以Llama3-8B-Instruct模型为例,DeCoRe熵在TriviaQA数据集上取得了56.93%的准确率。
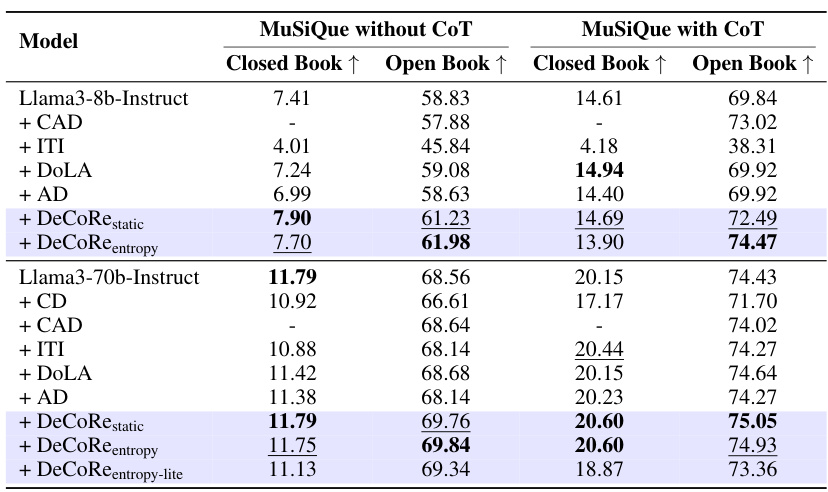
链式思维推理评估任务
在MuSiQue的数据集上进行的链式思维推理任务中,DeCoRe不同变体在闭书和开书设置下的表现都得到了有效的提高。尤其在有CoT提示时,Llama3-8B-Instruct模型的准确率显著提升。
掩蔽头影响研究
研究还分析了掩蔽检索头数量与任务表现之间的关系。通过掩蔽不同数量的检索头,结果表明性能与掩蔽头数量呈现出较强的相关性。例如,在XSum和MemoTrap中,掩蔽检索头数量与模型信实性的表现有正相关。而在开放书的NQ-Open和NQ-Swap中,掩蔽数量也同样显示出负相关。

通过这些实验结果,DeCoRe展现了在多个任务中减少幻觉的能力,尤其是在信实性和事实准确性相关的任务中表现卓越。这些实验为理解如何有效利用检索头来抑制LLM的幻觉现象提供了重要依据。
结论
DeCoRe(通过对比检索头解码)是一种新颖的解码策略,旨在减少大型语言模型(LLMs)中的信实性和事实性幻觉。DeCoRe基于以下假设:通过掩蔽检索头,可以诱发幻觉,限制模型从给定上下文中检索相关信息的能力。具体而言,DeCoRe利用检索头的掩蔽技术,创建出更可能生成幻觉的模型版本,并通过对比解码方案将其与原始模型结合。
此外,研究人员提出了一种简单的方法,通过使用模型下一个生成令牌分布的条件熵来控制对比解码强度。实验结果显示,DeCoRe显著提高了模型在需要上下文信实性和一些事实回忆及推理任务中的准确性。
尽管DeCoRe在大多数任务中提高了模型性能,但作者也指出,现有基线模型在某些特定任务中可能依然产生更准确的结果(例如,在TruthfulQA任务中使用ITI或在NQ-Swap中使用CAD)。此外,DeCoRe在事实回忆任务中的提升有限,这表明检索头在事实回忆中的主要作用可能是信息传递。
最后,尽管作者采用模型的下一个令牌分布的条件熵控制对比解码方案,但在将来的研究中可考虑采用更具“语义性”的不确定性量化方法。