动机
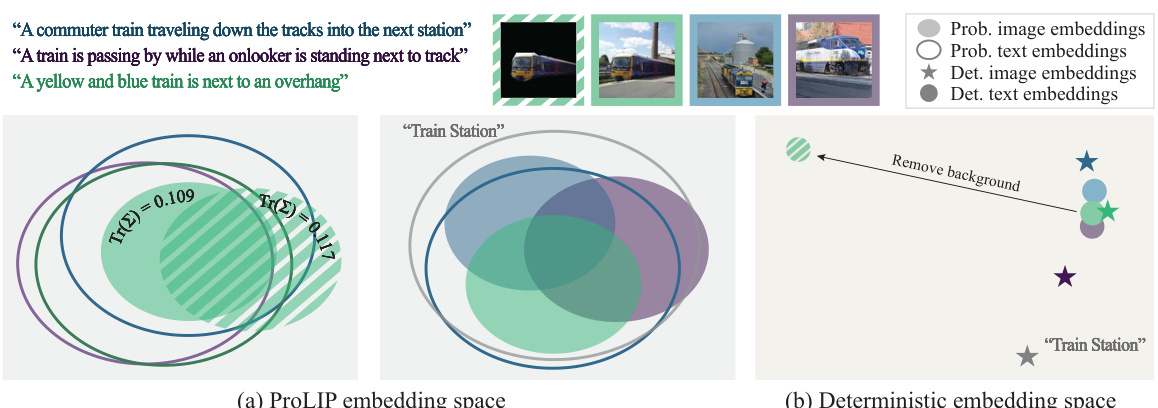
在引言部分,研究者们讨论了视觉语言模型(VLMs)的重要性,这些模型通过对齐的图像-文本对将其嵌入到一个联合空间中,成为机器学习领域的重要基础。然而,当前大多数VLMs依赖于确定性的嵌入,假设图像和文本之间存在一一对应的关系,这种简化的假设无法准确描述现实世界中更复杂的多对多关系。在实际应用中,多个文本标题能够描述同一图像,而一个文本标题也可能与多个图像匹配。
为了应对这一局限性,研究者们提出了概率语言-图像预训练(ProLIP),这是首个在十亿级图像-文本数据集上仅使用概率目标进行预训练的PrVLM。ProLIP通过引入“uncertainty token”来高效估计不确定性,而无需额外的参数。此模型的另一个创新在于引入了一种新的包含损失,强制实施图像-文本对之间以及原始和掩蔽输入之间的分布关系,从而使得嵌入的可解释性增强。
实验结果表明,利用不确定性估计,ProLIP在下游任务中表现出显著的优势,并且与直观的不确定性概念相一致,例如短文本通常具有更高的不确定性,而通用的输入则包括更多特定的输入。在少样本设置下,利用文本不确定性,ProLIP将ImageNet准确率从74.6%提升至75.8%,进一步支持了这一概率方法在实践中的优势。
通过以上创新,ProLIP不仅在零-shot任务中显示出强大的能力,还通过概率模型的引入,为理解输入数据的不确定性提供了更深层的视角。这项研究强调了在视觉语言应用中不确定性建模的潜力。
方法
架构
ProLIP模型通过将输入建模为具有对角协方差的高斯随机变量,来实现概率表示。模型包括分开用于视觉和文本输入的编码器,其中视觉编码器采用Vision Transformer(ViT),而文本编码器则采用Transformer结构。
为了有效地估计不确定性,ProLIP引入了一个新的不确定性Token([UNC]),而无需其他额外参数。视觉编码器在输入序列的开头接受[CLS]和[UNC],而文本编码器则在输入序列的末尾接受[UNC]和[CLS]。通过将[CLS]的输出作为均值,而[UNC]的输出作为对数方差,模型能够在最终嵌入空间中对输入的不确定性进行有效建模。
概率对比损失
为了训练ProLIP,主要使用概率对比损失(PPCL)作为目标函数。PPCL在构建过程中类似于先前的概率匹配损失,但为了稳定训练,采用了对数sigmoid损失。PPCL的公式如下:
其中a和b为可学习的标量,而为匹配与否的标签。
包含损失
为了确保模型学习到的随机变量在另一个随机变量中包含,ProLIP引入了一种新的包含损失。这一损失的计算基于两个概率分布的高重叠区域:
如果包含在中,的值会是正数,反之为负数。ProLIP使用包含损失来强化图像和文本之间的关系,使得文本分布通常包括图像分布。
训练目标
ProLIP的学习目标函数整合了上述PPCL和包含损失,具体形式如下:
其中均为控制每种损失函数影响的超参数。
使用不确定性估计进行提示调优
ProLIP通过对每个类别使用多个提示的方式进行zero-shot分类(ZSC)。可以通过过滤不确定性高的提示来选择最具信息量的文本提示,通过Bayesian Prompt Re-Weighting (BPRW)算法找到每个类别各种提示的最优权重。这一算法基于Dirichlet分布进行推断,结合不确定性估计对新的文本嵌入进行优化。
该算法的核心流程如下:
- 初始化参数和选择观察样本。
- 使用期待最大化(EM)算法分别进行E步骤和M步骤,计算每个样本由每个提示生成的责任度,更新提示权重。
该方法通过合理调整与视觉信息的结合,显著提升了模型在ImageNet上的ZSC准确度。
重要公式与图示
图示部分可参考原文的相关图片。在此不再重复。
实验
在本章节中,文章详细介绍了Probabilistic Language-Image Pre-training(ProLIP)的实验设置、实现细节以及实验结果。
实现细节和实验协议
ProLIP的模型使用了Vision Transformer(ViT-B/16)作为图像编码器,文本编码器采用了12层768宽的Transformer。设置嵌入维度为768,上下文长度为64个Token,遵循SigLIP ViT-B/16的设置。ProLIP基于开源的OpenCLIP实现,同时使用了DataComp-1B数据集进行训练。
在优化过程中,作者使用了AdamW优化器,学习率设置为0.0005,并进行了余弦学习率调度。在训练的mini-batch中,随机选择12.5%的图像-文本对并遮挡75%的信息以计算损失。评估过程中,作者在38个任务的数据集上测试了模型的表现,包括ImageNet及其变体、VTAB任务和检索任务等。
主结果
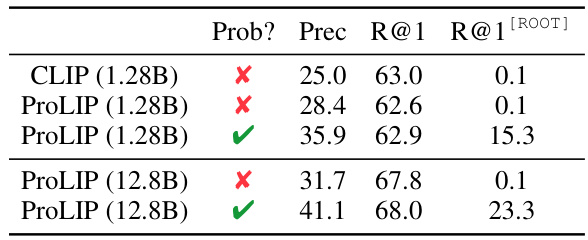
表1展示了ProLIP的零-shot分类结果。通过多个提示,ProLIP在所有指标上均超越了CLIP,尤其是在使用12.8亿数据进行训练时,表现更加优越。

了解学习到的不确定性
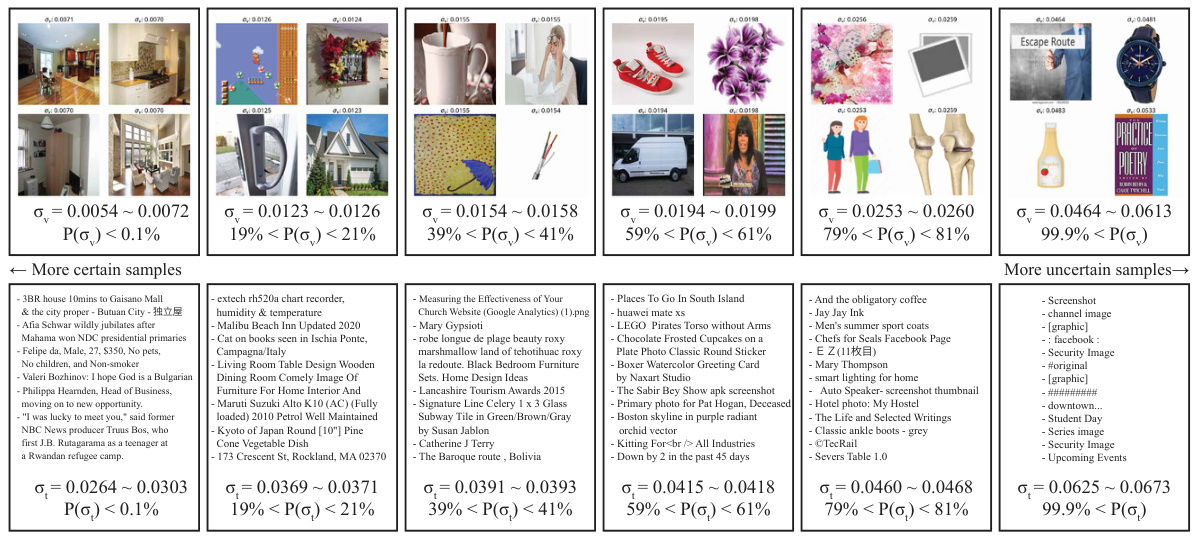
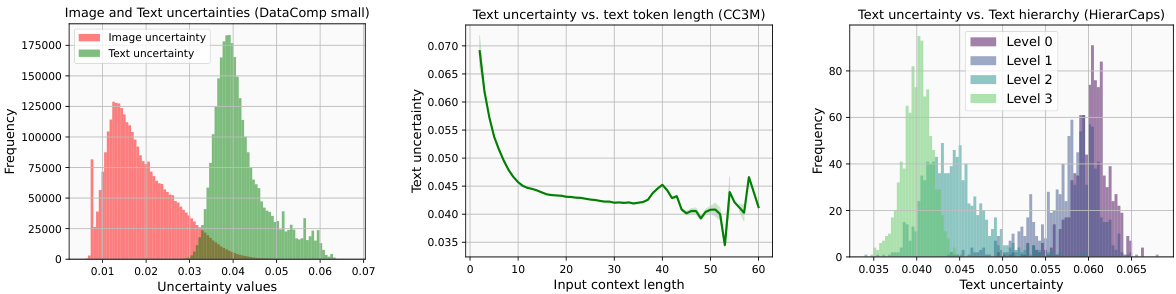
作者通过可视化不确定性样本来探索模型的性能。在研究中,作者定义了给定输入的不确定性,即计算的值。结果显示,意向更广泛的文本具有更高的不确定性,例如“截图”或“图形”,而特定的长文本则描述了独特的上下文。此外,文章还考察了不确定性和文本上下文长度之间的关系。图4显示了不同不确定性文本的样本。
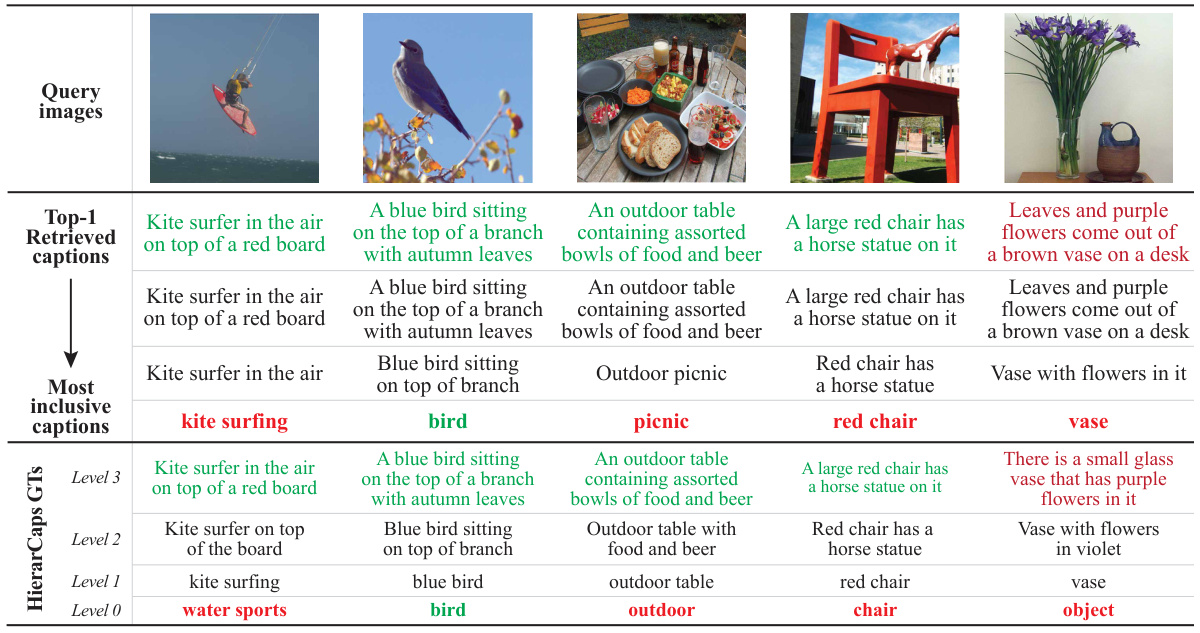
图像层次结构
作者构建了新的HierarImgs数据集,以展现视觉层次结构。在进行分析时,作者检验了每幅图像是否包含其下层图像,并计算了不确定性数值。结果显示,大多数图像满足包含假设,表明ProLIP在捕获图像层级方面表现良好。
应用不确定性的实验
在图像遍历实验中,作者设定了[ROOT]嵌入,检索给定图像的最近标题,并进行插值,寻找最具包容性的标题。实验结果表明,ProLIP的概率图像遍历在准确性和召回率上均优于使用空文本作为[ROOT]的确定性遍历。
进一步的,ProLIP通过贝叶斯提示重加权(BPRW)在不确定性上下文中调整提示的权重,在使用少量标注图像的情况下,观察到显著的性能提升。实验显示,BPRW的方法在处理不同类图像时能够有效提升模型的准确性。
结论
在这项研究中,研究者们引入了概率语言-图像预训练(ProLIP)模型,这是首个完全基于概率的方法,旨在解决传统确定性嵌入的局限性。ProLIP通过捕捉图像和文本关系中的固有多重性,将输入映射到随机变量,成功地用“不确定性 Token”([UNC])来高效估计不确定性,而无需额外的参数。
此外,研究者们提出了一种新的包含损失(inclusion loss),通过强化图像-文本对之间以及原始输入和掩码输入之间的分布包含关系,进一步提高了模型的可解释性。实验结果表明,使用ProLIP不仅在零-shot 分类任务中表现优越,还通过捕捉输入数据的不确定性提供了更深入的理解。这一方法显示了在视觉语言应用中,不确定性建模的潜力,表明其在未来的研究和实践中值得进一步探索和应用。