动机
随着大型语言模型(LLMs)的迅速发展,处理超长上下文(甚至超过100M tokens)已成为近年来LLMs的基本能力。这种能力进一步解锁了LLMs在代码分析等新任务和应用中的潜力,同时消除了解决上下文长度限制所需的复杂工具链和繁琐工作流程。
然而,近期研究表明,尽管长上下文模型(LCMs)在处理长上下文任务上有所进展,它们的表现仍然不尽如人意。这些模型可能会产生不对齐的结果,例如指令不遵循和幻觉现象。为了应对这一问题,开源社区做出了显著努力,主要集中在构建高质量的长指令数据和扩展数据规模上。虽然取得了一些有意义的改进,但现有方法在效果或效率方面仍显不足。
为了解决这一问题,论文提出了LOGO(Long cOntext aliGnment via efficient preference Optimization)作为一种新的训练策略。LOGO的创新之处在于引入了以优选优化为基础的训练目标,以指导LCMs在生成输出时进行偏好预测和非偏好预测之间的区分。此方法不仅提高了模型在长上下文任务中的生成能力,也保持了模型在短上下文任务中的原有能力。
综上所述,LOGO代表了一种新的研究方向,通过效率和精确性来优化长上下文模型的生成能力,充分发挥了模型的潜力。

(图1: 长上下文任务的性能表现)
方法
在本部分,研究者提出了一种名为LOGO(长上下文对齐高效偏好优化)的训练策略,以提高长上下文模型(LCMs)的生成能力。LOGO策略的核心在于两个关键组件:偏好优化训练目标和数据构建管道。具体来说,LOGO解决了传统训练方法导致的生成能力不足问题,包括幻觉生成和指令不遵循等。
LOGO训练目标
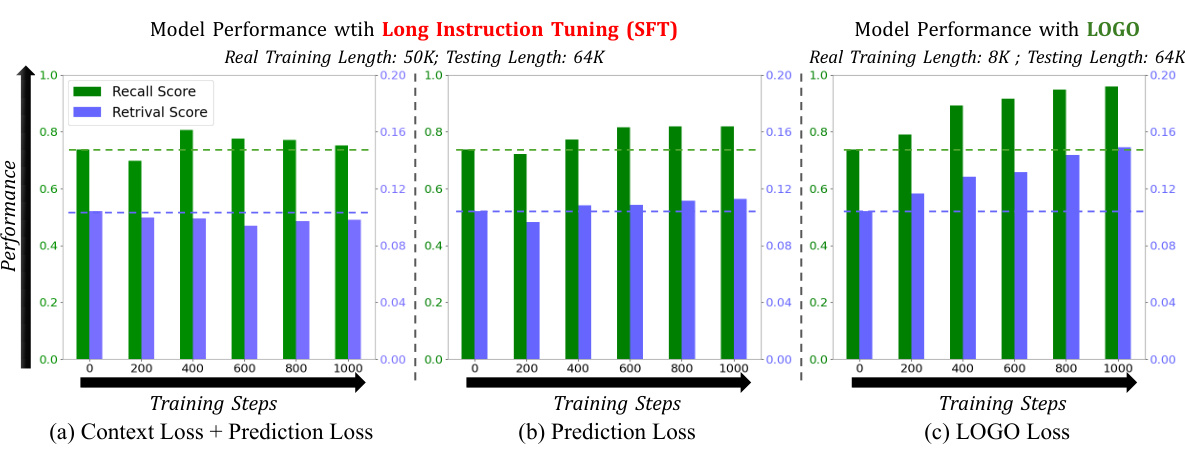
LOGO的训练目标是基于直接偏好优化(DPO)的方法,引入了一种针对长上下文场景的偏好优化目标。该目标旨在最大化偏好响应(正确输出)相对于不偏好响应(错误输出)的概率。
LOGO的损失函数定义为:
其中 表示偏好输出, 表示不偏好输出, 是不偏好实例的数量。此损失函数的设计使得模型能够区分偏好和不偏好的输出,以提高生成的准确性和一致性。此外,为了防止模型偏离其原始能力,LOGO引入了一个监督微调(SFT)正则化项,最终的损失函数为:
其中 是超参数,用于控制正则化项的影响。
数据集构建
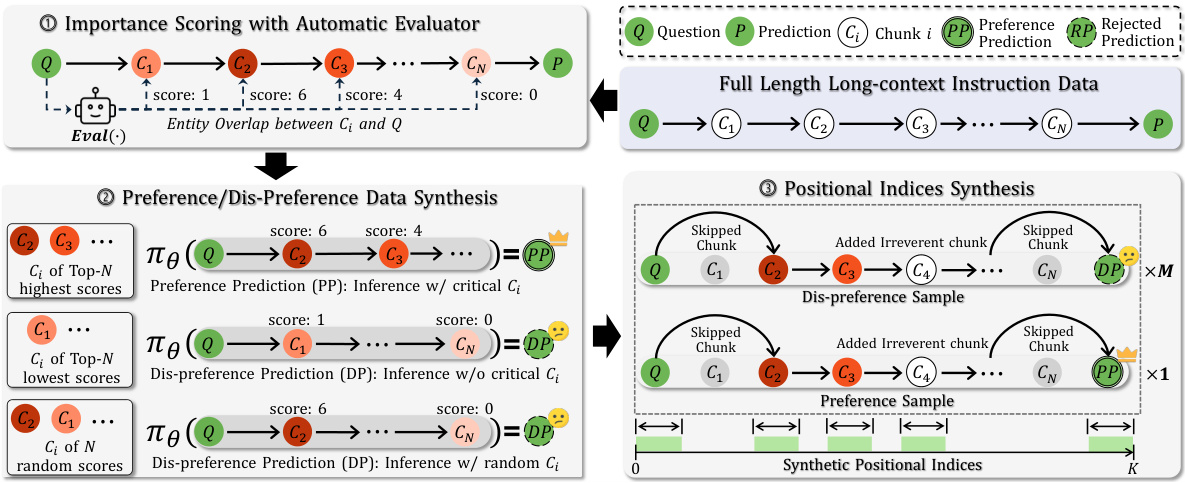
在LOGO训练中,研究者设计了一种专门的数据构建管道,以生成偏好和不偏好样本。每个长上下文样本被格式化为一个三元组 ,其中 是问题, 是参考上下文, 是模型的预测。
数据集构建过程包括以下几个步骤:
-
重要性评分:使用自动评估器计算上下文中每个块的重要性评分,从而确定哪些块对最终预测影响更大。重要性评分的计算方法是通过比较块中的实体与问题中的实体的重叠程度来完成的。
-
偏好与不偏好数据合成:根据模型的预测结果,从评分较高的上下文块中构建偏好样本,而从评分较低的上下文块中构建不偏好样本。
-
位置索引合成:为了应对训练长序列数据时的GPU内存限制,LOGO采用了位置索引合成策略,通过为每个块分配不同的合成位置索引来模拟长序列训练数据。
在每个LOGO训练样本中,由一个偏好实例和多个不偏好实例构成。这使得训练数据不仅能够高效利用GPU资源,同时保证了模型在长上下文任务中的表现得以优化。
位置索引合成
在位置索引合成中,为了确保生成的索引能够有效保持上下文的语义结构,研究者采用了两种不同的合成策略:连续块位置索引合成和稀疏块位置索引合成。
连续块位置索引合成保证了同一块内的索引连续,而稀疏块位置索引合成则使得不同块间的索引可以是不连续的,这种灵活性提高了对GPU内存的利用效益。
整体而言,LOGO方法通过优化训练目标和高效的数据构建管道,不仅提升了长上下文模型的生成能力,还确保了其对短上下文任务的性能维持。
重要公式
LOGO最终损失函数的表达为:
方法框架图
(LOGO数据集构建流程示意图)
实验
在本研究中,使用了LOGO数据集构建,通过两个数据集的结合来评估模型在不同长背景任务下的表现。
首先,从long-llm-data中抽取了4000个实例,涵盖单一细节问答、多细节问答和摘要等任务。然后,从RedPajama中抽取了2000个实例,以防止模型出现遗忘现象,并特别要求开源的LCM Qwen2-70B-Instruct生成每个实例的问题。每个实例被分割成相同长度的块,每个块包含512个Tokens。在构建偏好数据和不偏好数据时,利用命名实体识别(NER)模型为每个块分配重要性得分,以用于识别与问题相关和无关的块。
接着,研究团队进行了多种模型的训练、验证和评估,针对长背景任务、合成检索任务以及语言建模等多个方面进行了详细的评估。为了探索LOGO训练在短背景场景中的影响,也对模型在短背景任务上的表现进行了验证。
在长背景任务的评估中,使用了LongBench基准(Bai et al., 2023),该基准包括16个不同的数据集,覆盖6个任务类别。团队报告了LOGO在这些任务中的最佳表现,特别是在信息密集型任务上,例如摘要和合成任务取得了显著的性能提升。结果表明,经过LOGO训练的LCM比基准模型在真实世界长背景任务上表现更好。
对于合成检索任务,团队进行了“针在干草堆”测试,通过评估模型从上下文窗口中检索关键信息的能力。LOGO的训练对短背景模型(SCMs)的上下文窗口进行了有效扩展,并且没有影响原始长背景模型(LCMs)的能力。
此外,还进行了语言模型能力的测试,使用了Gutenberg(PG-19)测试集以计算困惑度(PPL),结果显示,使用LOGO的LCMs几乎没有损害语言建模能力。短背景模型在扩展背景长度后得到了有效提升,表现优于其他指令调优方法。
具体结果如下图所示:
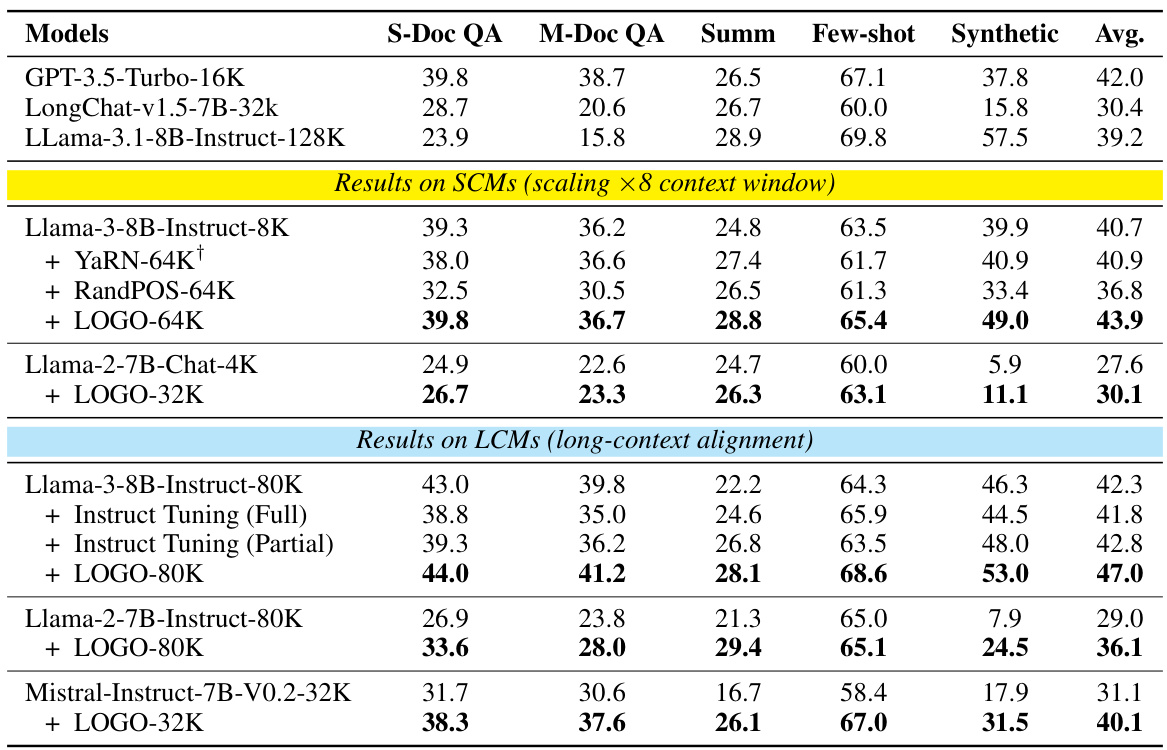
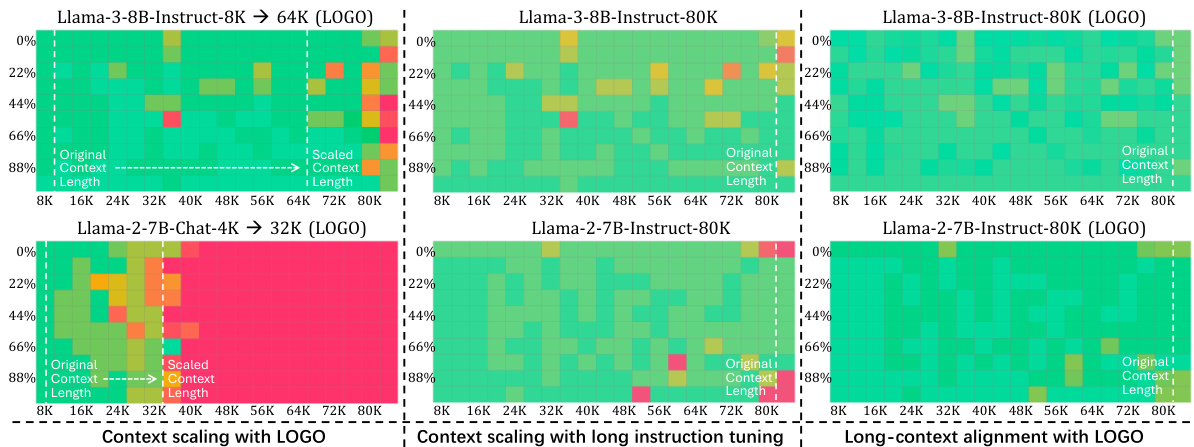
在短背景任务的评估中,团队选择了MMLU、TruthfulQA和ARC等基准进行测试,发现LOGO不仅保持了模型在短背景任务上的固有能力,而且在某些特定任务上有所提升。这表明,LOGO旨在指导模型基于上下文生成响应,而不是凭空捏造结果(例如产生幻觉),因此这种能力同样适用于短背景任务。
图表展示了不同训练设置的性能分布,验证了LOGO训练策略的有效性和对模型生成能力的影响。
结论
本文提出了一种高效的偏好优化训练策略LOGO,以应对长上下文模型(LCMs)在生成能力方面的不足,特别是避免输出错位现象,例如幻觉和指令不遵循等问题。LOGO的核心是引入了两大关键组件:第一,参考无偏好优化目标,旨在训练模型区分偏好的预测和不偏好的预测;第二,定制的数据构建流程旨在提升训练的效率和有效性。
通过在单一的 GPU机器上训练16小时,使用LOGO,LCMs在长上下文任务中获得显著提升,同时保持了其原有的能力。此外,LOGO也能够扩展短上下文模型的上下文窗口大小,并实现相较于其他常用的上下文扩展方法更好的生成性能。
整体而言,LOGO的引入不仅改善了长上下文任务中的生成能力,还为短上下文任务模型提供了性能提升,展示了在长上下文场景下高效训练的巨大潜力。未来,研究者们可以基于此方向继续探索,寻求进一步优化长上下文对齐及相关算法的机会。