动机
在近年来,大型语言模型(LLM)如ChatGPT、Claude和Llama的出现,彻底改变了深度学习领域,展现出在多种知识密集型任务上的显著效果。然而,这些模型中所学习到的知识可能存在错误、危害性或过时的信息,直接对LLM进行微调虽然可以缓解这一问题,但由于硬件和资源的限制,这并不可行。因此,模型编辑作为一种高效更新知识的替代方案应运而生。
目前的研究主要集中在模型编辑的可靠性、泛化能力和局部性等方面。现有的方法在这些标准上表现良好,但一些研究指出了模型编辑的潜在陷阱,比如知识的扭曲和冲突。然而,现有的文献尚未探讨编辑后的语言模型的一般能力。因此,本文的研究动机在于深入研究模型编辑对语言模型一般能力的影响,尤其是在进行多次编辑的情况下。
本研究的创新点包括:
-
系统评估的首次尝试:作者系统地评估了不同模型编辑方法对于语言模型的一般能力的影响,通过对多种编辑方法和语言模型的全面评估,填补了现有研究中的空白。
-
模型编辑方法的局限性:研究发现,现有的编辑技术在进行数十次编辑时能够保持模型的能力,但一旦编辑量达到一定规模,模型的内在知识结构将遭到严重破坏。
-
指令调优的优势:指令调优模型展现出对编辑的更强耐受性,性能降幅较小。
-
规模效应:大型模型相比小型模型在编辑时表现出更强的抗干扰能力。
通过这些研究发现,本文为未来更实用和可靠的模型编辑方法的研究提供了基础。
方法
本文的研究围绕语言模型的编辑方法展开,特别关注不同编辑方法对模型能力的影响。研究中使用了多种大型语言模型(LLMs)以及多种编辑技术,以便综合评估编辑对模型能力的影响。
模型编辑
模型编辑旨在精确调整语言模型在特定事实上的行为,而不影响不相关的样本。当前的方法主要集中于编辑知识元组。编辑过程通过插入新元组来替代当前元组,以实现对特定知识的更新。例如,编辑操作通过将(主体,关系,原始对象)替换为(主体,关系,目标对象)来完成。编辑的形式简化为编辑操作的集合。
编辑的评估通常涉及三个维度:可靠性、泛化能力和局部性。可靠性关注编辑后模型准确记忆自身编辑信息的能力;泛化能力评估模型在多种重新表述提示下回忆编辑信息的适应性;局部性则验证不相关输入在编辑后模型输出的稳定性。
语言模型
实验定量评估了不同语言模型的编辑效果,使用的模型包括 Llama2-7B、Mistral-7B、GPT2-XL,以及 Pythia 模型家族中的六种语言模型,各自具有从160M到12B不等的参数规模。通过这些模型可以观察到,模型的规模影响着其对编辑的敏感度。
模型编辑方法
为全面评估编辑模型的潜在影响,本文比较了多种编辑方法。主要包括以下几种类型:
- 元学习方法,例如 MEND。
- 定位后编辑型方法,如 ROME、MEMIT、PMET和 KN。
- 基于检索的方法,如 SERAC。
- 基于额外参数的方法,如 GRACE。
值得注意的是,不同编辑方法的效果取决于使用的超参数设置。因此,评估仅限于支持各自编辑方法的模型。
编辑数据集
本研究使用了最广泛应用的编辑数据集 ZsRE 和 COUNTER FACT,作为所有实验中的编辑基础。
评估基准
为有效判断模型编辑对 LLMS 总体能力的影响,研究采用了五个不同任务类别的基准测试,涵盖世界知识、数学能力、常识推理、阅读理解和安全性。这些基准评估在准确性、解题率和准备性等多维度进行量化。
编辑设置
本研究主要聚焦于顺序单次编辑,以探讨编辑对语言模型的潜在影响。
实验设计
本研究基于多个研究问题设计实验,和各项实验结果在后续章节中进行讨论。研究问题涵盖了编辑次数对模型能力的影响、指令调优模型与基础模型的表现差异、不同模型规模对能力的影响、不同编辑方法对模型能力各方面的影响,以及编辑是否会损害模型的安全性。
结果分析
通过对编辑 Llama2-7B 和 Mistral-7B 的不同编辑方法进行实证分析,实验结果揭示了编辑次数对模型能力的显著影响。许多当前的编辑方法在对模型进行多次编辑后,可能导致性能明显下降,但某些方法(如 PMET)在数百次编辑后也未见性能显著降低。
实验
在本节中,研究者介绍了实验的设计与设置,具体探讨了不同编辑方法对语言模型的一般能力的影响。
实验设置
研究选择了多种大型语言模型进行实验,包括Llama2-7B、Mistral-7B、GPT2-XL及多种不同参数规模的Pythia模型。这些编辑模型旨在评估不同编辑方法对模型能力的影响。
采用的模型编辑方法包括:
- 基于元学习的方法:MEND
- 定位后编辑的方法:KN、ROME、MEMIT、PMET
- 基于检索的方法:SERAC
- 基于额外参数的方法:GRACE
在所有实验中,研究者使用了广泛采用的编辑数据集ZsRE和COUNTER FACT,评估基准涵盖五个任务类别,包括世界知识、算术、常识推理、阅读理解和安全性。
研究问题设计
为了深入理解不同模型编辑方法对模型能力的影响,研究者提出了几个关键的研究问题:
- 数量编辑对模型能力的影响
- 指令调优的模型在编辑后的表现
- 编辑模型的规模对能力的影响
- 编辑对模型不同能力方面的影响
- 编辑是否影响模型的安全性
实验结果分析
研究者呈现了各种实验结果,包括不同模型在经历一定数量的编辑后的总体能力变化。通过编辑Llama2-7B和Mistral-7B模型,发现大多数编辑方法在少于20次编辑时能够保持模型的原始能力,但当编辑次数增加时,部分方法如ROME和MEND会显著降低性能,而其他方法如PMET在数百次编辑后仍保持相对稳定的表现。
实验还探讨了所谓的“静音效应”,即在进行10,000次编辑后,模型的内在知识结构被彻底破坏,导致任何输入的输出均为空字符串或随机字符。研究表明,现有的编辑方法适用于有限的编辑次数,通常不超过几十次。
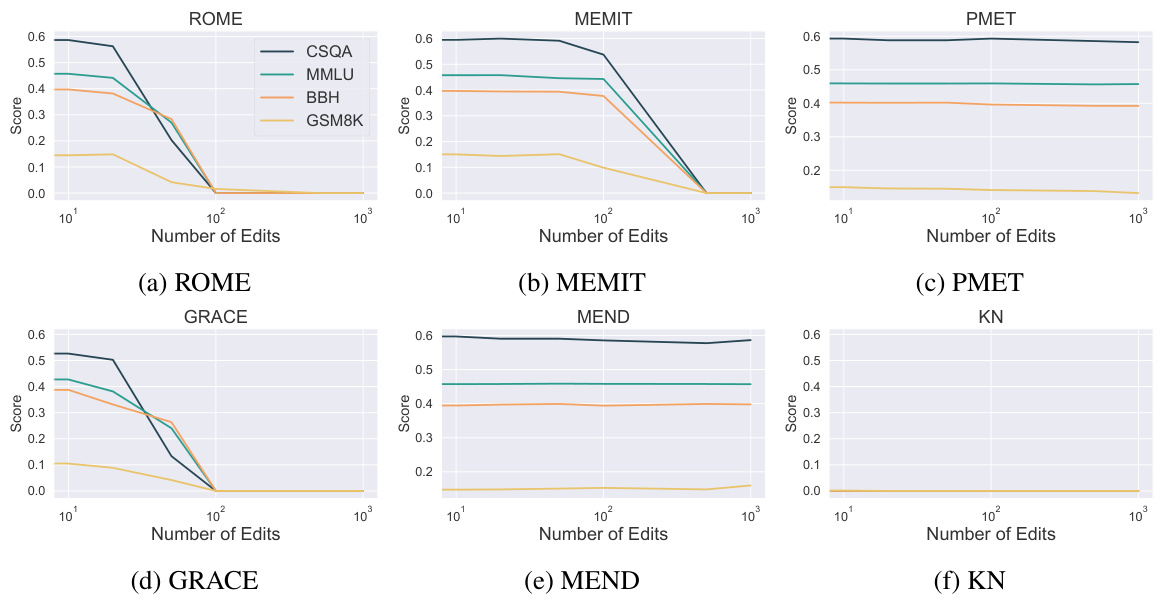
图2:使用六种编辑方法评估的Llama2-7B基模型在不同基准上的性能趋势。结果显示,PMET和MEND能够有效保持模型在所有任务上的能力,而KN在不到十次编辑后显著下降。
在对指令调优模型的影响方面,研究发现,编辑后的指令调优模型其表现降幅相对较慢,尤其是在使用MEMIT方法时。同时,研究探讨了不同模型规模下编辑的效果,结果显示,较大模型较小模型在编辑后表现更为稳定。
图4和图5展示了不同编辑方法对模型不同能力方面的均匀影响,PMET和MEND在各种任务中保持一致的表现,尤其是在经过多次编辑后。
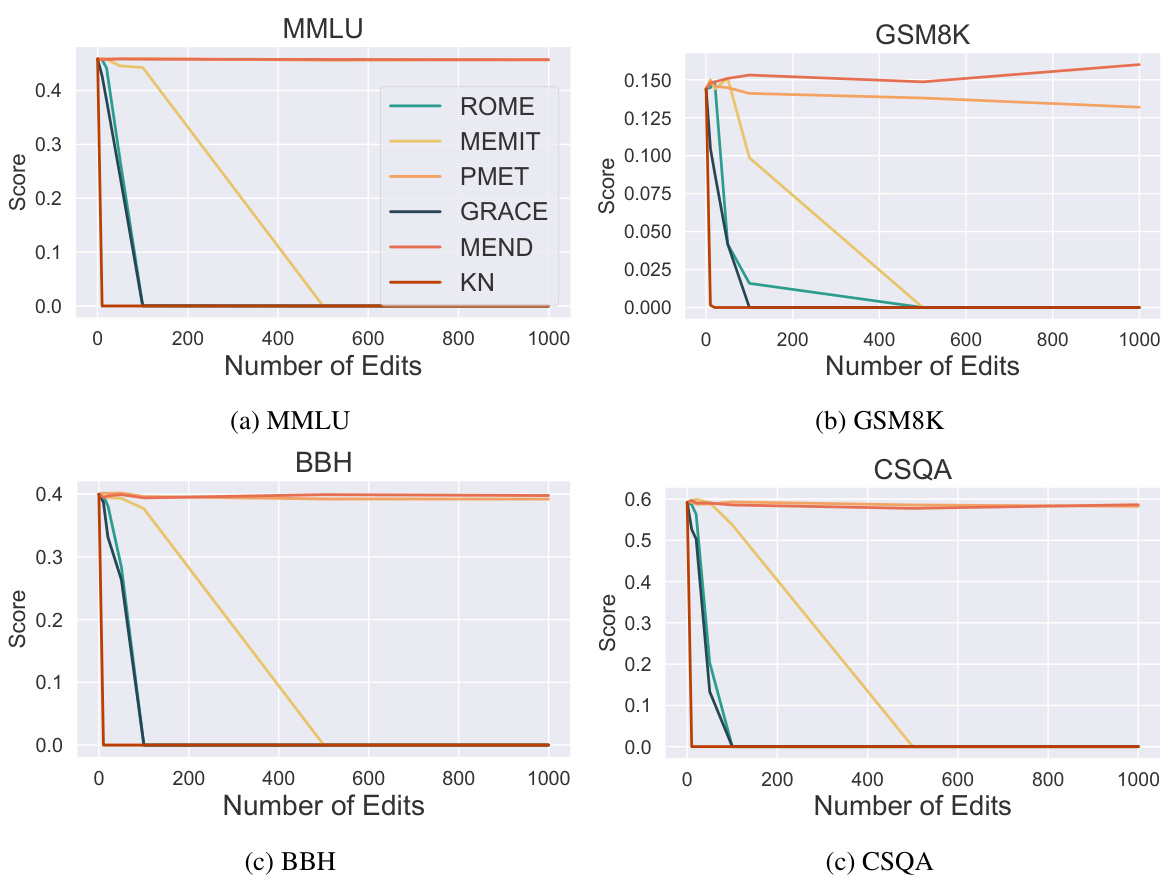
图5:评估不同编辑方法对语言模型不同能力的影响。结果显示,PMET和MEND在所有任务中能够有效保持模型的能力。
最后,研究者专注于编辑对模型安全性的影响,实验证明即使是几十次的编辑也可能损害模型的安全性,并在某些方法下出现意想不到的性能提升。
结论
在这项研究中,作者系统地探讨了模型编辑对语言模型(LLM)一般能力的潜在影响。通过在多种模型上应用不同的编辑方法,并在多个基准上进行评估,实验结果表明,现有的编辑方法能够在有限的编辑次数内保留模型的整体能力,该次数通常不超过几十次。然而,当编辑次数达到一定规模时,模型的内在知识结构可能会受到破坏,甚至完全损坏。此外,研究还考察了可能影响模型编辑后性能的各种因素及其对模型基本能力的潜在影响,结果显示,即使经过数十次编辑,模型的安全性也会受到一定程度的影响,包括那些已对齐的模型。
总体而言,现有的大多数编辑方法只适合进行不超过几个特定更新的场景。因此,作者呼吁进一步的研究,以解决现有编辑方法的缺陷,并找到更加实用和可靠的解决方案。研究的发现不仅对模型编辑领域的进一步探索具有重要意义,还为在实际应用中修改语言模型的策略提供了有价值的见解。