动机
随着生成式人工智能技术的快速进展,新一代产品应用不断涌现,例如文本生成、文本到图像生成和文本到视频生成等。这一发展要求相应的安全系统必须及时跟上,以有效防止新型危害的发生,确保系统的整体完整性。尤其是,避免生成式人工智能产品被恶意行为者用于传播虚假信息、宣扬暴力和推广不当内容,成为当前非常重要的任务。
传统的模型微调方法通常被用来解决内容审核的问题,但是在自动化内容审核方面存在诸多挑战。首先,内容审核是一项高度主观的任务,标注数据中的注释者一致性较低,尤其是在边界案例中,可能会存在多种不同的政策解读。其次,由于任务的主观性以及系统在新地域、新受众和不同使用场景下的扩展,无法强制执行一个普遍的危害分类法。
为应对这些由于主观性和扩展性而导致的挑战,研究团队提出了一种新的内容审核分类方法——基于检索增强生成(Class-RAG)的分类方法。Class-RAG结合了嵌入模型、检索库、检索模块和微调的LLM(大语言模型)分类器。当用户输入查询时,系统可以从检索库中动态检索出相似的正负例,从而为内容分类提供上下文信息,进而更准确地进行决策。
创新点在于,Class-RAG不仅能在分类性能上超越传统的微调模型,还具备灵活性和透明度。通过持续扩展检索库的规模,可以低成本地提高内容审核的效果,使得该方法在快速变化的内容生态中具备更好的适应能力。此外,Class-RAG在对抗性攻击下表现出的更强鲁棒性,也展示了其在内容审核领域的潜在应用价值。
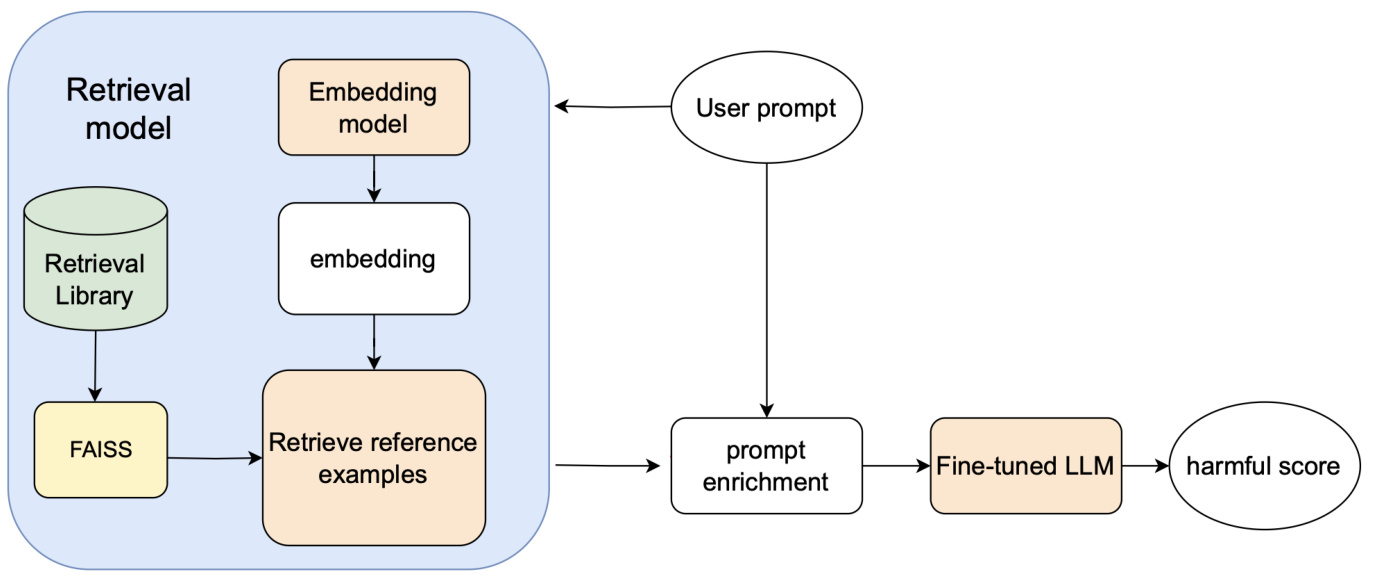
方法
Class-RAG是一种四部分组成的系统,旨在提升内容审核的效果。该系统由嵌入模型、检索库、检索模块和微调的大型语言模型(LLM)分类器构成。当用户输入提示时,系统会利用嵌入模型对该提示进行嵌入计算,并将用户输入的嵌入与检索库中映射到正例和负例的嵌入进行比较。通过Faiss库进行高效的相似性搜索,检索出与用户输入最相似的k个参考例子。然后,这些参考例子与输入提示一起被发送到微调的LLM进行分类。
嵌入模型
研究中使用了DRAGON RoBERTa作为主要的嵌入模型,该模型采用双编码器结构,将查询和文档嵌入到密集向量表示中,以便高效检索相关信息。此外,还评估了一种基于WPIE(Whole Post Integrity Embedding)的变体,该模型是在内容审核数据上预训练的4层XLM-R模型,分别生成不安全概率估计和提示嵌入表示。
检索库
检索库分为两个子库:安全库和不安全库。检索库中的每个条目由四个属性组成,包括:提示、标签、嵌入和解释。检索库的构建详细说明在数据准备部分。
检索模块
在选择嵌入后,系统使用Faiss库进行相似性搜索,快速检索出检索库中两个最接近的安全例子和两个最接近的不安全例子。具体来说,采用L2距离度量来计算输入嵌入与存储在检索库中的嵌入之间的相似性,从而识别最相关的例子。
LLM分类器
于基于LlamaGuard的方法,分类器在OSS Llama-3-8b检查点之上进行了微调,以确保模型在内容审核任务中的表现。
数据准备
在数据准备环节,研究人员利用CoPro数据集进行模型训练和评估。CoPro数据集包含生成的分布内(ID)测试集和分布外(OOD)测试集。评估模型的通用性还利用了Unsafe Diffusion和I2P++数据集。对于测试集,研究还使用了Augly库中的八种常见伪装技术,以评估模型对对抗攻击的鲁棒性。
检索库的构建
在安全库的构建过程中,研究人员使用K-Means聚类方法将安全例子按概念分为7个集群,并选择每个集群的中心例子纳入安全子库。不安全例子的构建也采用了相同的方法,最终生成了3484个安全例子和3566个不安全例子。同时,为每个例子利用Llama3-70b模型生成解释文本,增强检索库的使用效用。
检索库的外部构建
为评估模型对外部数据集的适应性,研究人员利用I2P和UD数据集构建了外部库。应用K-Means聚类的方法,成功从I2P和UD验证集收集了991个安全例子和700个不安全例子,形成外部检索库。
下图展示了Class-RAG系统的架构:
经过详细的数据准备及系统框架设计,Class-RAG在内容审核的复杂性和模糊性中提供了可扩展的解决方案,能够灵活适应安全风险的不断变化。
实验
实验部分对提出的Class-RAG模型进行了综合评估,旨在比较其与两个基线模型(WPIE和LLAMA3)的性能。实验设计包括七个关键组成部分,涵盖模型的分类性能、对外部数据的适应能力、指令遵循能力、性能可扩展性及不同嵌入模型的表现等方面。
实验设置
在训练和评估中,输入文本通过添加系统指令和参考提示进行了丰富。训练数据中特别包括了推理过程,以帮助模型从上下文和提供的解释中学习。训练配置为,在八个A100 80GB的GPU上进行训练,批量大小为1,学习率设置为2e-6,训练进行了一个epoch。
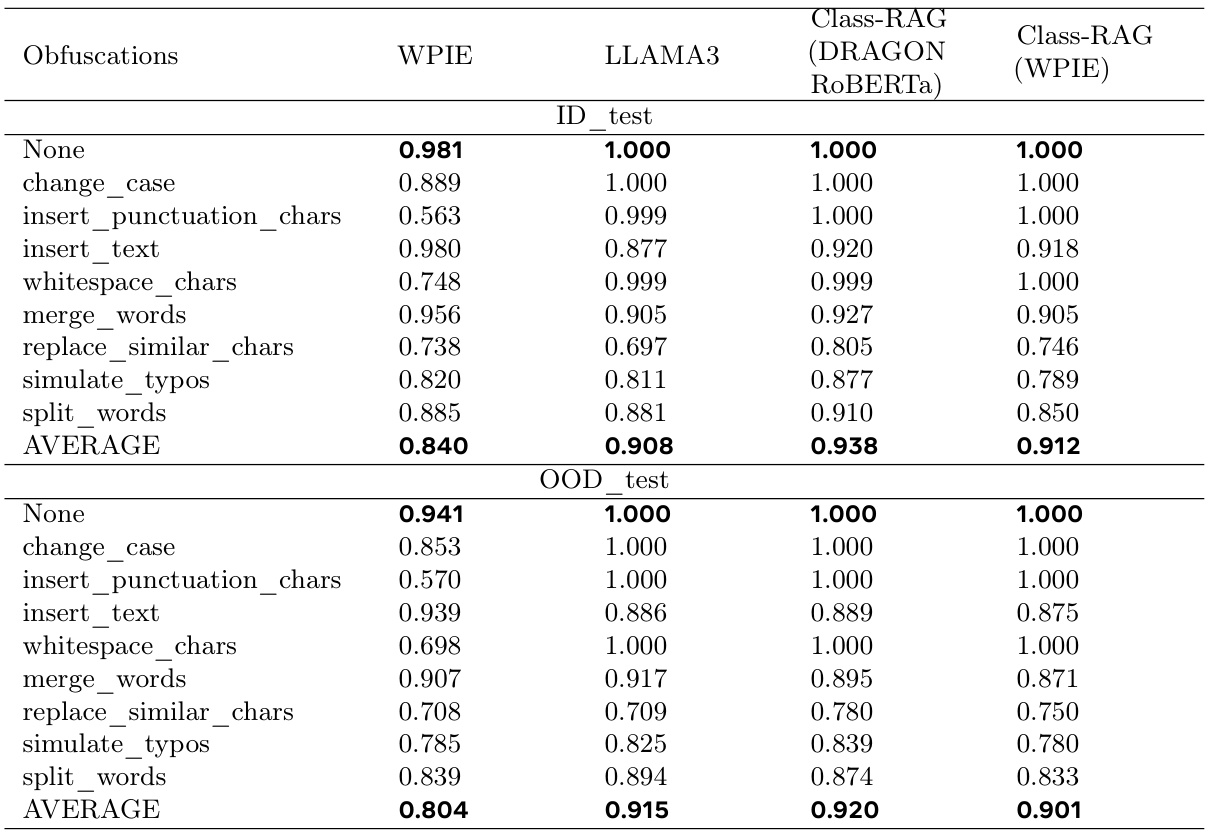
分类性能与鲁棒性
对Class-RAG进行了全面评估,与基线模型WPIE和LLAMA3的性能进行了对比。特别关注模型在CoPro的在分布(ID)测试集和外分布(OOD)测试集上的表现。为评估模型在对抗攻击下的鲁棒性,测试集还采用了八种常见的模糊技术进行增强。Class-RAG在分类性能和对抗攻击的鲁棒性上均显示出优于基线模型的结果,这表明了其在面对模糊输入时的性能稳定性。
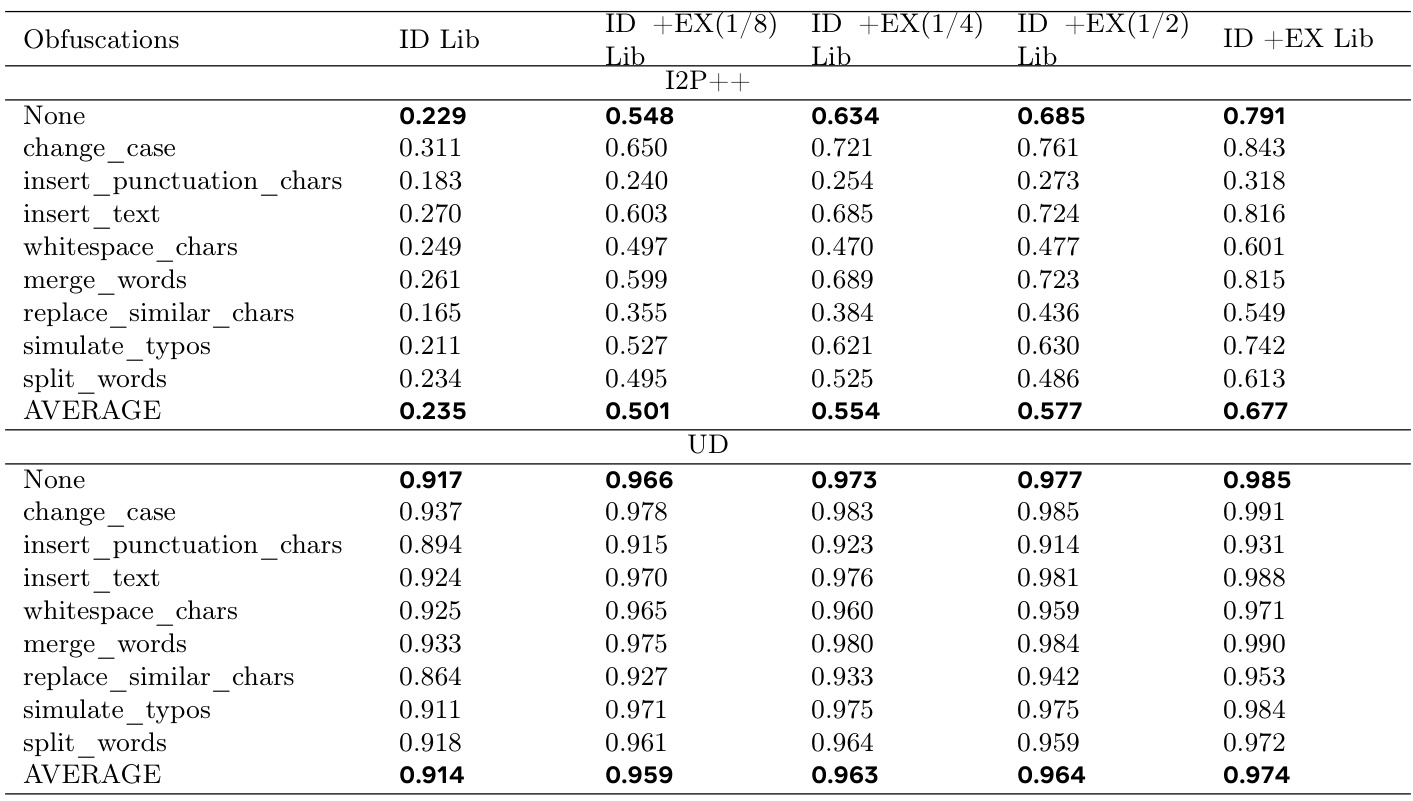
对外部数据的适应性
Class-RAG通过无需模型重训练,即可适应外部数据,这一特性是RAG框架的重要优势。模型在I2P和UD两个外部数据集上的适应性得到了评估。实验中,使用从CoPro训练集收集的在分布(ID)库以及从I2P和UD验证集中构建的外部(EX)库来评估。
指令遵循能力
Class-RAG的指令遵循能力是指其理解并根据给定指令生成准确响应的能力。在此部分,使用了ID测试集及其翻转ID库进行评估。结果显示,Class-RAG在遵循“翻转标签”的指令上表现良好,成功将绝大多数正确示例的标签从“安全”翻转为“危险”,但对不符合预期的标签如从“危险”翻转为“安全”的表现有所欠缺。
检索库大小对性能的影响
调查了检索库大小对Class-RAG性能的影响。实验显示,模型性能随着检索库大小的增加而持续提升,这一趋势在I2P++和UD数据集中均得到了验证。这表明增加检索库的规模是提高模型性能的一种有效而经济的手段。
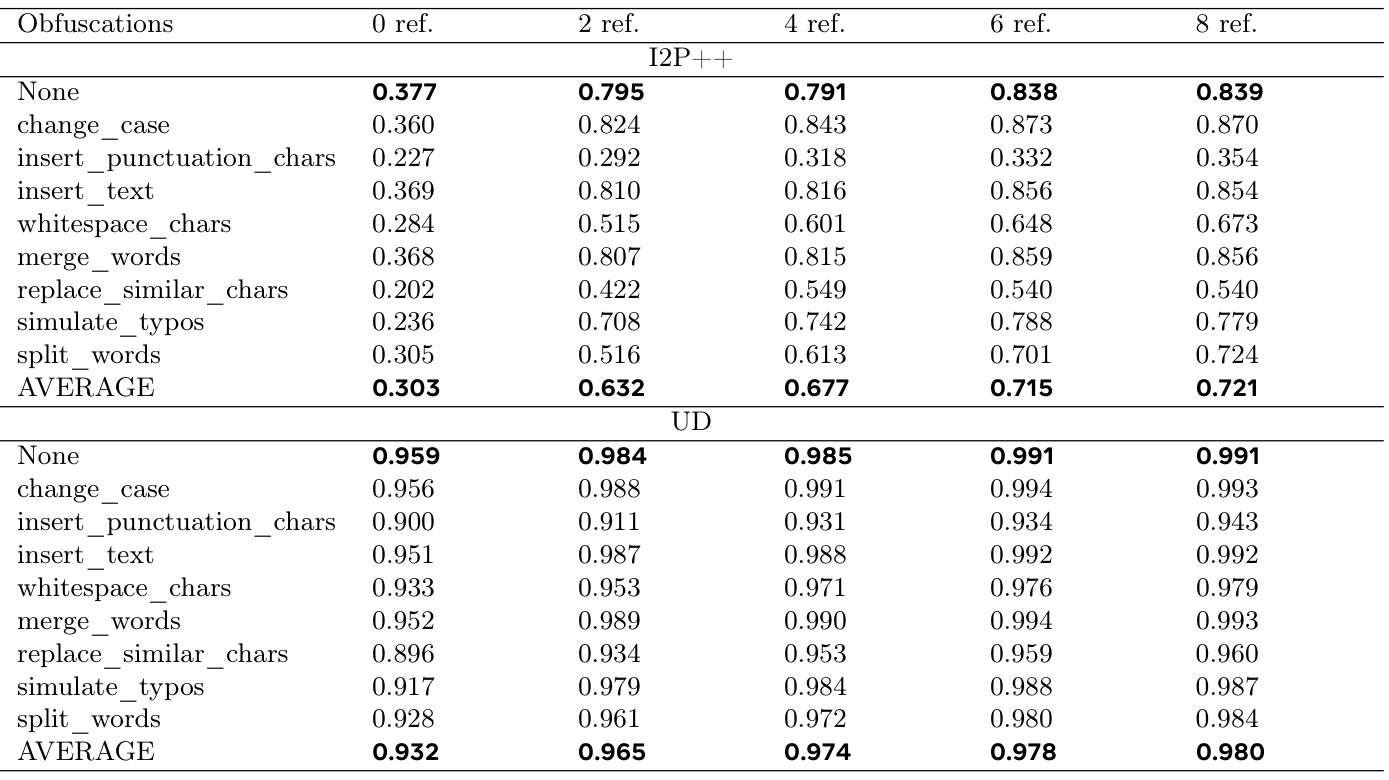
引用示例数量对性能的影响
进一步研究了引用示例的数量对Class-RAG性能的影响。实验结果显现,当引用示例数量从0逐步增加到8时,模型性能显著提升,但在约8个引用示例之后,性能提升的效果呈现饱和状态。增加引用示例的同时会增加计算成本,因此需要在性能提升和计算开销之间寻找平衡。
不同嵌入模型的表现
对两种不同的嵌入模型 — DRAGON RoBERTa 和 WPIE 的影响进行了评估。实验结果表明,DRAGON RoBERTa模型在ID测试集和OOD测试集上的平均AUPRC得分均高于WPIE,显示出更优的性能。
以下是实验结果的相关图表:
结论
在本文中,研究团队介绍了Class-RAG,这是一个结合嵌入模型、检索库、检索模块和微调的大型语言模型(LLM)的模块化框架。Class-RAG的检索库可以在生产环境中作为一种灵活的热修复手段,及时减轻潜在的危害。通过在分类提示中使用检索的示例和解释,Class-RAG在决策过程中提供了解释性,从而增强了模型预测的透明度。全面的评估显示,Class-RAG在分类任务中显著超越了基准模型,并展现出对于对抗性攻击的鲁棒性。此外,实验还表明Class-RAG能够有效地通过更新检索库来融入外部知识,便捷地适应新信息。Obdser有明显的正相关关系,比较同层的检索库大小和参考示例数量,提升了Class-RAG的性能。总的来说,研究表明,增加检索库的规模是一种新颖且具有成本效益的方法,可显著提升内容审查的能力。这一研究为在生成式AI领域检测安全风险提供了一种强大、可适应和可扩展的解决方案,有望有效缓解AI生成内容中的潜在危害。