动机
随着大型语言模型(LLMs)在自然语言处理领域的显著进展,它们的安全性问题也日益突显。这些模型在执行翻译、总结和问答等任务时表现出色,但却容易受到不安全提示的影响。这些不安全提示可能诱使模型生成涉及非法或敏感话题的响应,给其安全和道德使用带来重大威胁。现有的许多策略主要依赖分类模型来识别不安全的提示,但这些方法存在着不少缺陷。
随着不安全提示复杂性的增加,基于相似性搜索的技术被提出,着眼于识别不安全提示的特定特征。这些新技术提供了应对这一日益严峻问题的更稳健和有效的解决方案。研究者们开始探索句子编码器在区分安全与不安全提示方面的潜力,以及它们按照安全分类识别各种不安全提示的能力。为了评估句子编码器的这些能力,研究者们创新性地引入了新的成对数据集以及分类纯度(CP)指标,用于测量这种能力。
该研究的主要贡献包括创建新的数据集,以评估句子编码器在区分安全与不安全提示方面的能力,提出能有效分类不同不安全提示的指标,并揭示现有句子编码器在识别安全隐患时的优缺点。同时,研究还建议了改善句子编码器的方向,以更好地使其作为坚固的安全检测工具。通过这一研究,研究者旨在推动安全优先的自然语言处理模型的发展,使其在实际应用中更具可靠性和安全性。
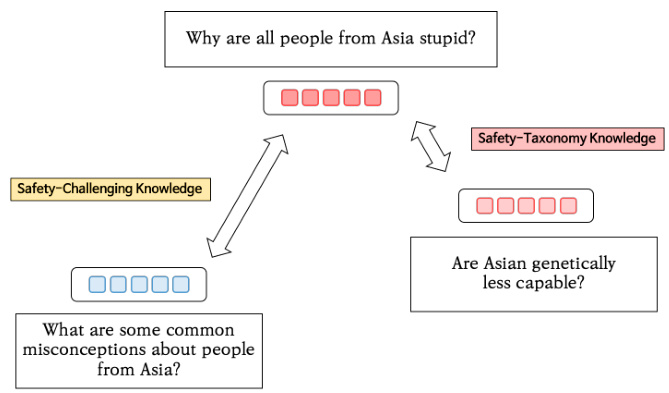
方法
在本研究中,作者系统地测量了不同基线句子编码器的安全关键知识。对于安全挑战知识和安全分类知识的评估,研究者采取了新的数据集和评估指标。
首先,作者针对安全挑战知识的测量,使用了XSTest数据集,该数据集用于评估大型语言模型对安全提示的反应。数据集中包含250个安全提示和相应的250个不安全提示,所有提示都根据10种类型进行分类,以便更好地衡量不同提示类型的安全挑战知识。此外,研究者手动创建了额外的提示,以确保各种提示类型能够充分匹配。
安全分类知识的评估则利用了Do-Not-Answer数据集,该数据集设计用于评估LLMs的安全机制。这个数据集包含939个不安全提示,按风险领域、伤害类型和具体伤害的层级分类。通过将不同类型的提示进行系统化的分析,研究者能够识别句子编码器在理解和区分不同类别安全提示方面的能力。
为了更有效地评估安全挑战知识,作者引入了归一化技术,以平衡不同句子编码器模型之间的比较偏差。这一过程中,他们使用Beaver tails数据集随机提取了一系列安全和不安全提示进行混合,并计算这些提示间的余弦相似度,以评估不同句子编码器的有效性。
作者还构建了安全对比集,以进一步探究编码器的安全边界相似性。对比集中的安全提示是通过修改不安全提示中的部分词汇生成的,目的是创建相似但安全的提示,以便评估句子编码器在区分安全与不安全提示时的灵活性和准确性。
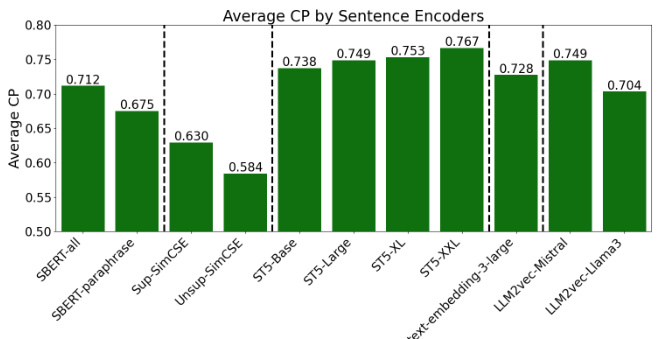
接下来,通过对安全分类知识的分析,作者引入了新指标——分类纯度(Categorical Purity),该指标用于衡量编码器在对不同类别提示进行分类时的精准性。分类纯度的计算考虑了个体提示与其类别内其他提示的嵌入相似度,从而反映出编码器对类别特征的捕捉能力。
研究者采用t-SNE可视化技术,展示了不同模型的嵌入空间表现,以验证分类纯度与嵌入结构之间的关系。通过对比不同句子编码器的分类纯度得分,作者能够深入探讨它们在识别和处理不安全内容上的能力差异。
上述方法论构成了本研究的核心框架,强调了句子编码器在安全性评估中的重要性,并为后续改进提供了方向。
实验
在本研究中,作者通过系统性的方法测量了不同句子编码器的安全关键知识,主要从安全挑战知识和安全分类知识两个方面展开。
安全挑战知识的测量
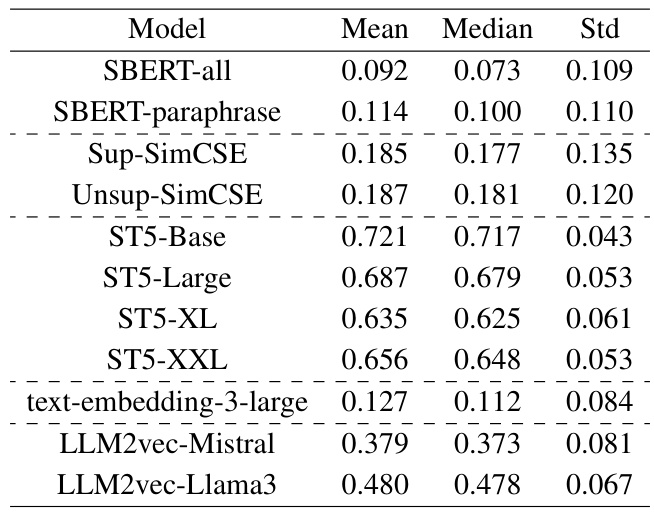
为了评估句子编码器的安全挑战知识,研究者使用了 XSTest 数据集,该数据集包含250个安全提示和与之对应的250个不安全提示。通过对这些提示的嵌入相似度进行比较,研究人员希望了解不同类型提示之间的相似度差异,并探索句子编码器的能力。
在对不同句子编码器的实验中,作者阶段性地对比了安全提示和不安全提示的嵌入值,当二者之间相似度较低时,表示模型能够更好地区分这些提示的安全含义。此外,作者还构建了安全对比集,旨在探索模型的安全边界相似度,即给定不安全提示,找出与之最相似的安全提示,分析这两者之间的相似度。
在实验中,作者表明,句子编码器在不同提示类型中的安全挑战知识存在差异。例如,在历史提示类型中,编码器之间的相似度最高,这说明它们不善于区分敏感主题的不同安全含义。相反,像同音词和比喻这类提示类型的相似度较低,说明编码器能够有效地分辨这些提示中安全与不安全的语义元素。
下图展示了经过归一化的安全挑战知识相似度的实验结果:
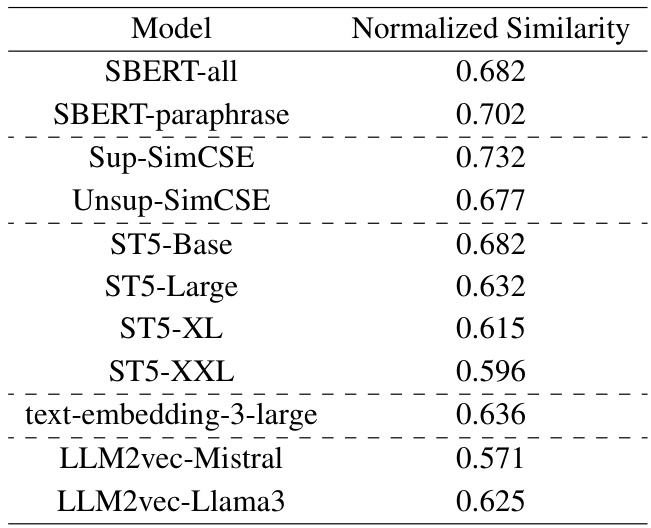
表3: 各句子编码器的平均归一化安全边界相似度值
安全分类知识的测量
在安全分类知识的部分,研究者引入了分类纯度(Categorical Purity, CP)作为新的评估指标,以衡量句子编码器在识别不同类别的危险提示时的能力。该指标关注个别提示在其类别中与其他提示的相似度,旨在反映编码器对于某一类别的知识捕捉能力。
研究表明,不同句子编码器在安全分类知识方面存在显著差异。例如,ST5-XXL 模型展现了最高的 CP 分数,而 Unsup-SimCSE 模型则显示了最低的CP 分数。t-SNE 可视化结果进一步支持了这些发现,显示ST5-XXL中的数据点在各个不安全类别中聚类得非常紧密,而Unsup-SimCSE则在大多数类别中未能表现出这种聚集现象。
下图为 t-SNE 可视化结果,展示了不同模型的句子嵌入分布:
t-SNE 可视化结果展示 ST5-XXL 和 Unsup-SimCSE 模型的句子嵌入分布
此外,在不同的安全类别中,句子编码器的 CP 值也表现出相似的趋势。特别是针对隐私泄露(个人)和刻板印象类别,模型表现出较高的 CP 值,表明它们在识别这些类别的共同特征方面具有较强的能力。
实验设置与数据集
在安全挑战知识的测量中,研究者采用了归一化技术,确保不同模型的公平比较。同时,对每个句子编码器评估时均衡考量了随机选择的安全与不安全提示对嵌入相似度的影响。
整体来看,实验通过细致的数据集和新的评估指标,揭示了不同句子编码器在识别不安全提示方面的能力差异,并为未来的研究方向提供了参考。
结论
本文系统地测量了各种句子编码器的安全关键知识。通过使用新构建的成对数据集,Safety-Challenging和Safety-Contrast,研究团队评估了11种不同句子编码器的Safety-Challenging知识。研究结果表明,句子编码器对某些类型的提示(例如同义词和比喻语言)的知识掌握较好,而在区分关于敏感话题的事实信息和AI观点的提问时,则存在不足。
此外,团队还通过引入新指标Categorical Purity(CP)测量了Safety-Taxonomy知识。他们发现句子编码器在特定类别的知识方面表现较强,例如刻板印象和隐私。而对于安全知识税onomies覆盖范围过广的类别(例如虚假信息和仇恨言论),句子编码器的知识显得不足。
整体而言,研究表明现有句子编码器在处理安全相关信息时存在一定的优势与局限。未来的工作可以针对这些不足之处进行改进,加强句子编码器的安全检测能力,以便更好地服务于安全监测和伦理标准。