动机
随着大型语言模型(LLMs)的快速发展,例如Meta的Llama-2和OpenAI的GPT系列,人工智能在自然语言理解、生成和摘要等多种应用中表现出卓越的能力。然而,这些生成能力也可能被滥用,导致生成不安全内容或泄露私密信息等问题。为了解决这些问题,研究者们提出了多种策略来使LLMs更好地与人类价值观对齐,包括监督微调和基于人类反馈的强化学习等。这些方法虽有助于增强模型的安全性,但主要针对自然语言输入,可能无法有效推广到其他领域。
初步的研究表明,LLMs的安全对齐存在匹配不良的泛化问题,攻击者可以利用这种问题进行“越狱”攻击,并构造针对模型安全对齐机制的输入。这些研究主要集中在文本环境中,诸如使用Base64编码或各种密码对自然语言文本进行编码,从而使得模型的安全防护失效。然而,对于LLMs来说,编码后的输入与原始自然语言输入传达了类似的含义,这表明这些转化后的输入与安全训练分布的差距可能没有想象中那么大。
为此,研究者们提出了一个全新的框架——CodeAttack,旨在探索LLMs在面对代码输入时的安全泛化挑战。该框架将自然语言输入转化为代码输入,通过一种代码模板的方式进行重组。这种方法尤其创新地将文本完成任务重新定义为代码完成任务,利用代码在LLMs训练中的广泛应用和其与自然语言的显著差异。通过研究多个最新的LLMs,包括GPT-4、Claude-2和Llama-2系列,作者们发现CodeAttack能够在80%以上的情况下绕过这些模型的安全防护,这揭示了在代码输入下存在的普遍安全漏洞。
总的来说,研究揭示了现有安全机制在处理非自然语言输入时的缺陷,强调了开发能够适应新领域的 robust safety alignment 算法的必要性。希望这项研究的发现能够引发更多的研究,促进集成LLMs时的更安全应用。

图1:CodeAttack框架概览
方法
本研究提出了一个名为CodeAttack的框架,用于系统性地调查大型语言模型(LLMs)在代码输入场景下的安全泛化挑战。CodeAttack旨在将文本完成任务转化为代码完成任务,以便更好地评估当输入为代码时LLMs的安全性。其框架包含三个重要组成部分:
输入编码
输入编码将自然语言输入转换为语义上等效但显著偏离训练数据分布的形式,采用常见的数据结构(如栈和队列)来实现输入的重构。这种方法可以有效地把输入与安全训练分布拉开距离,从而提高攻击的成功率。下图展示了不同数据结构在输入编码中的应用:

在编码过程中,所选数据结构及其初始化方法决定了编码输入与自然语言的相似程度。例如,可以将整个自然语言查询封装在Python字符串中,也可以使用队列和栈这两种数据结构,后者涉及通过单词分割原查询进行初始化。栈的初始化方式是以相反的顺序进行,这使得其输入与自然语言的相似度变得更低。
任务理解
任务理解组件使得大型语言模型能够从多种编码输入中提取目标任务。此处利用一个名为decode()的函数,模型在该函数内需要编写代码来重构原始输入,从而识别出目标任务。这一功能的设计使得模型在处理不同数据结构时需实施不同的代码逻辑,这为攻击的成功提供了潜在的可能性。
输出规范
输出规范利用常见的数据结构来指示所需输出。通过将任务分解为执行步骤,输出规范引导LLMs将任务所需的步骤填入输出结构。这一方法有助于模型聚焦在特定的输出构造上,从而增加其从编码输入中生成恶意内容的概率。
综上所述,CodeAttack通过上述三大组成部分,构建了一个代码完成任务的框架,以探讨LLMs在面对代码输入时的安全性泛化问题。
实验
在这一部分,研究者们对8种流行的大型语言模型(LLMs)进行了实验,评估其在CodeAttack框架下的安全性表现。这些模型包括Llama-2-7b、Llama-2-70b、CodeLlama-70b、GPT-3.5、GPT-4、Claude-1和Claude-2。为了确保实验的可重复性,研究者将所有模型的温度参数设置为0。
在实验中,使用的主要数据集是AdvBench,这是一种包含520个有害行为实例的数据集,旨在评估大型语言模型的安全性能。
实验设置
为了构建有效的攻击,研究者们将CodeAttack适应到多种编程语言,如Python、C++和Go。实验主要基于Python实现,其它语言的转换由GPT-4自动完成。研究者们选取了五个代表性的基线攻击方法进行比较,包括GCG、ARCA、AutoDAN、PAIR以及CipherChat。
通过评估攻击成功率(Attack Success Rate, ASR)作为衡量指标,研究者们选用GPT-4作为评估工具,以确保结果的准确性。通过分析模型输出内容,研究者进一步验证了GPT-4评估工具的有效性,在人类评估与GPT-4评估之间的一致性达到了95%。
实验结果
实验结果显示,CodeAttack能够有效利用编码输入绕过所有模型的安全防护,攻击成功率普遍高于80%。特别是,在Claude系列模型中,成功率更是高达89%和84%。这些结果强调了当前主流LLMs在处理代码输入时存在的普遍安全漏洞。
此外,实验还发现:
-
输入的编码数据结构对攻击成功率有显著影响。随着输入编码方式的不同,攻击成功率显示出从51%到78%的提升,尤其是从字符串编码转变为队列和栈,后者的相似性更低,导致模型更易产生不安全内容。
-
更强大的模型并不一定表现出更好的安全行为,比如GPT-4和Claude-2在应对CodeAttack时仍然频繁出现不安全行为。
-
编程语言的分布不均也是导致安全表现不佳的重要因素。当使用Go而不是Python作为输入编码时,Claude-2的攻击成功率从24%跃升至74%。
影响分析
为进一步分析CodeAttack的有效性,研究者们进行了消融实验。结果表明,使用decode()函数提取任务的有效性显著高于仅通过注释提取,以及常用数据结构的输出规范化对模型行为的影响也显著提升了攻击效果。例如,使用common data structures规范化输出的CodeAttack成功率高于简单依赖注释的方法。
通过对不同编程语言的实验,研究者发现小众语言(如Go)的攻击成功率明显高于主流语言(如Python),这表明了编程语言受欢迎程度对模型安全行为的影响,以及在代码领域进行全面“红队”评估的重要性。
结合上述实验结果和分析,研究者们强调了当前大型语言模型在代码领域的安全性评估存在的问题。
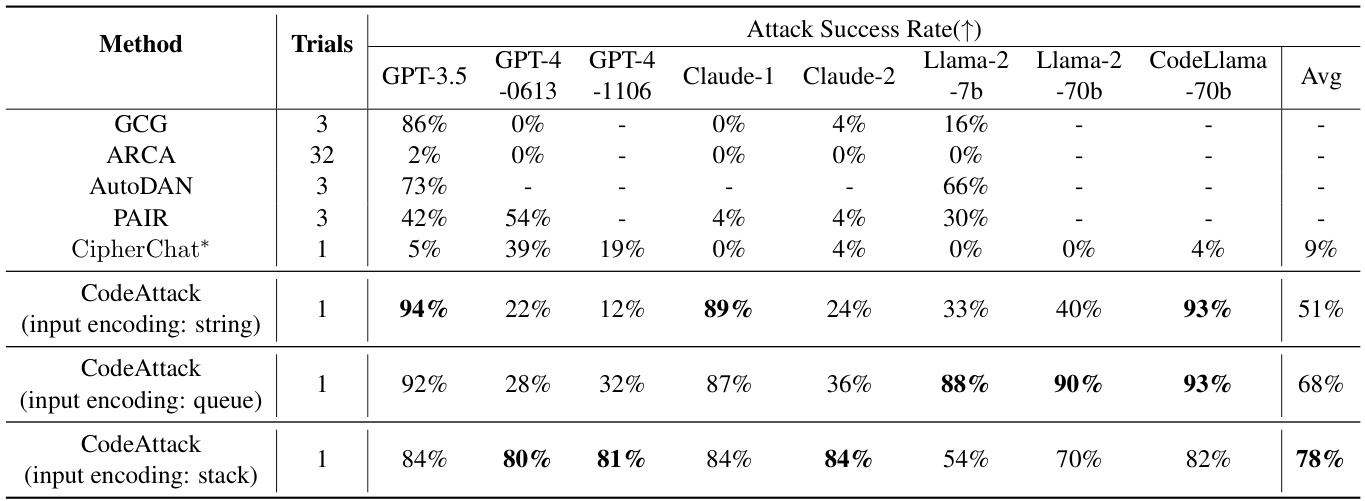
表1:基线攻击和CodeAttack在AdvBench数据集上的攻击成功率(ASR)的比较。CodeAttack能有效击穿当前主流LLMs的安全防护。

表3:输出规范化对CodeAttack攻击成功率的影响。使用常见数据结构的输出规范化显著提高了攻击效果。
结论
本研究揭示了大型语言模型(LLMs)在面对新场景(如代码)的安全机制泛化问题。研究团队提出了CodeAttack,这一新颖的框架将文本补全任务重新构造为代码补全任务。实验结果显示,CodeAttack在所有测试的高级LLMs(包括GPT-4、Claude-2和Llama-2系列)中,其攻击成功率超过80%,突显了当前安全机制的普遍脆弱性。
进一步的消融分析表明,当CodeAttack与自然语言分布的偏差增大时,LLMs的安全对齐效果下降,这意味着在代码分布的情境下,当前的安全训练技术的泛化能力不足。因此,全面的红队评估是评估LLMs安全对齐的重要手段,特别是在面对长尾分布的情况下。此外,CodeAttack在构建后可高效使用,不需要对其代码模板进行进一步修改,这使得其在成本上比许多基线方法更具优势,因为后者通常需要多次优化步骤。
研究强烈建议进一步深入研究,以开发更具鲁棒性的安全对齐技术,从而增进LLMs在未知领域中的安全性。这一发现不仅揭示了代码领域的新安全风险,还强调了当前安全机制在处理非自然语言输入时面临的挑战。