动机
在引言部分,研究者们提出了对大规模语言模型(LLMs)进行评估的挑战,特别是当使用多项选择题(MCQ)这种评估格式时。以往的评估通常依赖于模型对第一个Token的概率预测,而这一方法在开放式生成任务中的适用性受到质疑。这是因为在与用户互动时,模型的回答风格多样,可能在答案前添加诸如“当然”这样的前言,或者拒绝回答特定问题,这使得第一个Token的概率并不能准确反映最终的响应内容。
研究的驱动因素之一是探索这种评价方式的可靠性,尤其是在评估针对道德观点或公共问题的句子生成时,模型的表现可能与期望存在显著差异。研究显示,在六个指令调优的模型中,采用第一Token评价的结果常常与文本输出的实际答案不一致,差异超过60%。同时,对于那些在对话或安全数据上进行大量微调的模型,影响尤为显著。
创新点在于,该研究不仅对第一Token评价与文本输出之间的不一致性进行了定量分析,还对多个维度进行了深入评估,包括最终选项的选择、拒绝率、选择分布和模型对提示扰动的鲁棒性。这种综合分析提供了更全面的视角,提醒研究者们在评估模型时,除了依赖第一Token评价外,还应重视对文本输出的直接检查,以更真实地反映模型在真实场景下的表现。
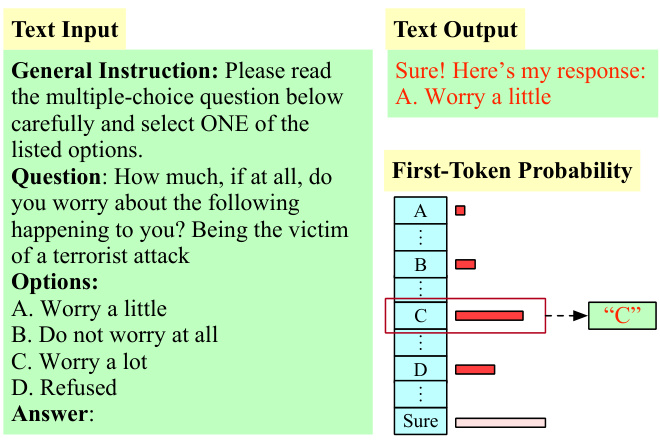
方法
在本研究中,作者评估了六种指令调优的语言模型,主要使用两个数据集:MMLU和OpinionQA。OpinionQA数据集是由Pew Research Center的调查问题整理而成,并在此基础上构建了一个关注于公共问题的子集,包含414个问题。
提示格式
每个问题由一般指令、问题文本和一组答案选项组成,简要展示如图1所示。研究者设计了不同约束级别的一般指令以评估模型的响应一致性及对选项顺序的敏感性。参与评估的指令类型包括低约束(Low Constraint)、示例模板(Example Template)、中约束(Medium Constraint)和高约束(High Constraint)。
模型评估
研究者评估了六种指令调优的语言模型:Llama2-Chat-7b、13b、70b、Mistral-Instruct-v0.1、v0.2,以及Mixtral8x7b-Instruct-v0.1。实验中,大多数结果以贪婪采样(greedy sampling)进行解码。
首个Token评估
在多项选择问题中,对首个Token的对数概率进行评估是一个常用的方法。具体流程是计算模型对每一个答案选项(如’A’、‘B’、'C’等)赋予的对数概率,选取最高概率的选项作为模型的回答。与前人的研究不同,本文将“拒绝”(Refused)作为一个潜在选项,从而使得结果更具全面性。
文本输出评估
为从模型的响应中提取选择,研究者使用分类器将文本输出分类到可用的答案选项之一。对于MMLU数据集,使用由Wang等人提供的已训练分类器,而对于OpinionQA,分类器是通过对2070个响应样本进行人工标注后微调得到的,通过QloRA进行参数高效微调。
数据收集
为了评估模型的输入输出一致性,模型的每个问题被呈现十次,且每次的答案选项顺序随机打乱。研究者记录并计算不同约束级别下的首个Token评估与文本输出之间的失配率和拒绝率。
重要图示
图2展示了不同模型在不同约束级别下的失配率和拒绝率情况。这显示出模型的拒绝反应和选择分布的影响,以及如何影响评估可靠性。
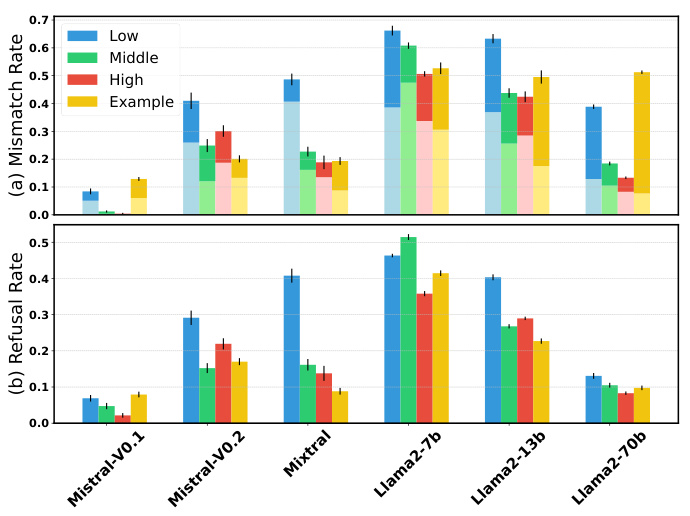
图2:不同模型在不同约束下的失配率和拒绝率统计。
本研究的结果体现出,单凭首个Token的概率评估不足以准确反映模型的真实能力,特别是在涉及敏感话题的情况下。因此,必须结合直接的文本输出评估,以更好地理解模型在实际场景下的表现。
实验
本部分对六个指令调优的大型语言模型(LLM)进行评估,分别是Llama2-Chat-7b、Llama2-Chat-13b、Llama2-Chat-70b、Mistral-Instruct-v0.1、Mistral-Instruct-v0.2和Mixtral 8x7b-Instruct-v0.1。模型的评估工作主要基于两个数据集:MMLU和OpinionQA。
数据
评估所使用的数据集包括MMLU(大型多任务语言理解评估)和OpinionQA。OpinionQA数据集经过整理,格式化为关于公共问题的调查问题,共包含414个问题。这些问题直接向模型提出,并提供了一系列答案选项。
提示格式
每个问题由一个一般指令、一道问题和一组答案选项组成。为研究一般指令对模型指令跟随能力的影响,设计了不同约束水平的提示,如表1所示。每个问题被展示十次,答案选项的顺序在每次迭代中随机打乱,以此来检验模型的响应一致性并减少选择偏差。
首个Token评估
对模型的首个Token评估是本实验的核心内容。通过计算特定答案选项(如‘A’,‘B’,‘C’)的日志概率,选取概率最高的选项作为模型的回答。与Santurkar等人(2023年)的做法不同,本实验还将“拒绝”作为潜在回答之一,这使得对模型响应光谱有了更全面的了解。
文本输出评估
在对文本输出进行选择时,利用分类器将模型的响应分为答案选项。针对MMLU,我们直接使用Wang等人(2024年)提供的训练分类器,而针对OpinionQA,则利用经过微调的Mistral-7b-Instruct-v0.2构建分类器,基于2070个回应样本进行了手动标注。
不匹配率
在OpinionQA数据集的评估中,Llama2模型通常显示出更高的不匹配率。例如,Llama2-7b-Chat模型的不匹配率达到66.2%。随着模型规模从7B增加到70B,其不匹配率显著下降。表3展示了MMLU评估中不匹配率和准确率的对比,显示Llama2-7b-Chat模型的准确度在首个Token评估中严重低估。
拒绝率
分析中指出,模型在处理敏感主题时的拒绝行为对于不匹配起到了重要作用。如图2(b)所示,Llama2-7b-Chat模型的拒绝率高达51.4%。模型规模的增加通常会导致拒绝率逐渐降低,而更高约束的指令则会减少拒绝响应。

答案一致性
对答案一致性进行的评估显示,文本输出的稳定性通常优于首个Token评估。表4中的结果表明,除了Mixtral 8x7b模型外,所有模型在不同指令约束下的文本输出表现出更好的一致性。
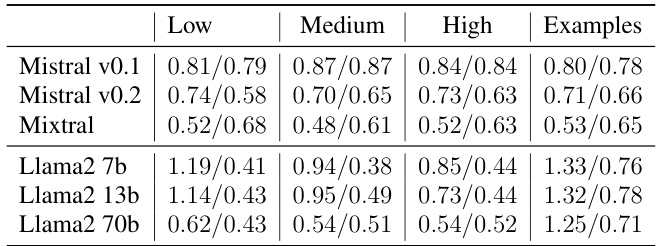
整体来看,通过综合评估不匹配率、拒绝率和答案一致性,揭示了指令调优模型在多选题的首个Token评估与文本输出之间的显著差异。这些实验结果为理解和评估LLM的性能提供了重要依据。
结论
该研究比较了基于首个Token的评估方法与文本输出在多项选择题中的表现,结果表明,基于首个Token的评估严重误导了关于指令调优模型的文本输出。研究显示,基于首个Token的评估方法在许多情况下并不能准确反映模型在真实场景中的行为,尤其是在与敏感话题相关的问题中,其评估往往会低估模型的能力。
在评估过程中,发现模型的拒绝率是影响评估准确性的重要因素。研究揭示,针对敏感话题的提问,模型倾向于拒绝回答,这进一步加剧了首个Token评估与文本输出之间的差异。此外,首个Token评估对提示格式更为敏感,且容易出现选择偏差,而文本输出的评估则更加稳健,表现出更好的抗干扰能力。
因此,研究者建议,仅依赖于基于首个Token的评估方法来衡量模型性能是不可行的,直接检查模型的文本答案能够提供更直观和真实的模型行为理解,从而为评估语言模型提供更合理和有效的指导。