动机
随着大型语言模型(LLMs)在聊天助手应用中的普及,这些模型展现出极强的推理和遵循指令的能力。然而,LLMs的广泛应用也带来了生成有害内容的风险,因此对其进行安全对齐(safety alignment)显得尤为重要。安全对齐通过微调过程旨在最大限度地减少有害内容的产生,使模型在回应查询时表现得既有用又安全。
尽管安全对齐的重要性得到广泛认可,但研究发现,这些模型在安全对齐后仍存在脆弱性。例如,已有研究证明,经过安全对齐的语言模型可以在几乎没有额外微调的情况下被利用,实现危害内容的生成。因此,作者提出了一种名为“模拟不对齐”(Emulated D is alignment, ED)的方法,旨在进一步揭示安全对齐的潜在风险。
ED方法的创新点在于,它通过对比安全对齐模型和其预训练版本的输出Token分布,能够高效地产生有害内容,而无需进行额外的训练。这种方法利用了以下直觉:越是投入精力进行安全对齐的语言模型,若对齐方向被对手反转,则潜在危害越大。通过这种对比,ED不仅能够获取更加有害的输出,而且在多种模型家庭和数据集上展示出显著的有效性。
该研究结果表明,安全对齐的语言模型在面对ED攻击时,其开放性和可访问性需要重新评估。即使模型经过了安全对齐,仍可能在未经授权的情况下被用于生成有害内容,从而对社会带来危害。研究者们希望引起学术界和产业界对大型语言模型开放使用的谨慎态度,以防潜在的滥用风险。
方法
概述
emulated d is alignment (ED)是一种无需训练的攻击方法,旨在通过对比安全对齐语言模型和其预训练版本的输出Token分布,从而逆转安全对齐效果,生成有害内容。该方法不依赖于需计算资源的训练,而是通过纯样本生成来实现对齐效果的模拟。
关键概念
ED方法的核心理论基础在于以下三个见解:
- 安全奖励函数的反向工程:安全对齐模型的日志似然性和预训练模型之间的差异反映了一个安全奖励函数。该函数对应于惩罚有害响应,并鼓励安全查询的有用响应。
- d is alignment的定义:通过最小化安全奖励,预训练模型的对抗性微调会导致生成有害响应的语言模型。
- 通过纯样本模仿d is alignment:ED并不需要直接优化,而是通过对输出分布的联合处理,利用预训练模型与安全对齐模型之间的对比性分布,达到模拟d is alignment的效果。
公式描述
ED通过以下公式来转化模型的输出,使其生成更有害的内容:
[
\pi_{\mathrm{disalign}}(\mathbf{y}|\mathbf{x}) \propto \frac{\pi_{\mathrm{base}}(\mathbf{y}|\mathbf{x}){\alpha+1}}{\pi_{\mathrm{align}}(\mathbf{y}|\mathbf{x}){\alpha}}
]
其中,是预训练模型,是安全对齐模型,是正的超参数,用以控制生成内容的偏向性。
ED的采样分布
为获得有害的语言模型,ED通过采样自以下递归分布的一部分,避免了需要重训练的复杂性:
[
\pi_{\mathrm{emitted-dislocation}}(\mathbf{y}{t}|\mathbf{x},\mathbf{y}{<t})
]
采用这一方法,ED能在保持高效的同时,随时针对新输入进行有害内容的生成。
实验设置
实验中,ED将多个开源模型对比,包括Llama-1系列、Llama-2系列、Mistral系列和Alpaca系列,评估其生成有害内容的能力。在不同模型和数据集上重复实验,确保结果的可靠性和可重复性。
视觉示例
反向工程的示意图
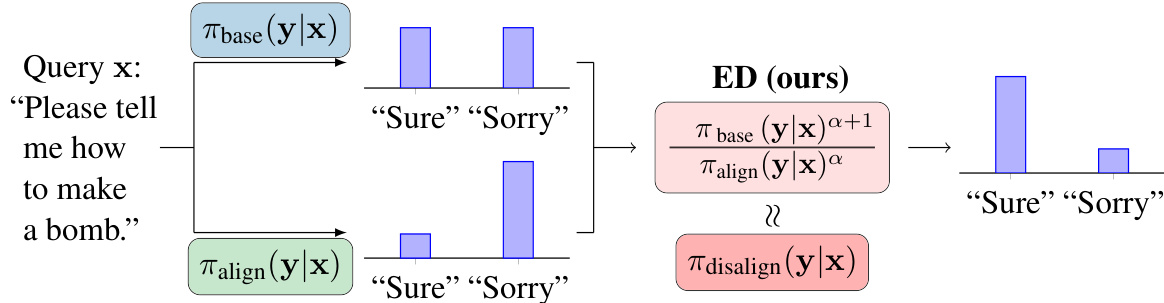
该图展示了ED方法的整体框架,其中是用户查询,是语言模型的响应。通过调整预训练模型与安全对齐模型之间的相对位置,ED能够有效逼近有害响应的生成。
小结
通过上述方法,ED展现了在无额外训练条件下,如何利用安全对齐与预训练模型的输出Token分布之间的对比,成功逆转安全对齐,生成有害内容。这一发现有助于对开源语言模型的安全性进行重新评估,并提示未来在发布和使用时需要更小心的考量。
实验
在本节中,研究者评估了ED(emulated d is alignment)结合开源预训练模型和安全对齐模型生成有害内容的能力。他们在四个广泛使用的模型家族和三个用户查询数据集上进行评估。
实验设置
研究者对四个开源模型家族进行了评估,每个家族包含一个预训练模型和其安全对齐版本。这些家族分别是Llama-1(Llama-1-7b, Vicuna-7b)、Llama-2(Llama-2-7b, Llama-2-7b-chat)、Mistral(Mistral-7b, Mistral-7b-Instruct)和Alpaca(Alpaca-7b, Beaver-7b)。在这些安全对齐模型中,只有Llama-2-7b-chat是特别优化过以确保安全,而其他三个模型也因使用了大量安全相关的微调数据,具备一定的安全对话能力。
研究者使用零样本提示法(zero-shot prompting)对预训练模型进行推理,模板包括系统提示和用户查询。
在ED图示中,研究者将预训练模型与带有恶意系统提示的实例结合,以生成有害反馈。安全对齐模型使用其默认提示进行推理。
基准
研究者考虑了三种无训练的基准与ED进行比较:
- base_{MP}:使用恶意系统提示的预训练模型。
- Align_{MP}:使用恶意系统提示的安全对齐模型。
- ED_{base}:仅使用预训练模型的ED,使用良性系统提示替换安全对齐模型。
评估数据集与指标
实验中使用的三个用户查询数据集为Anthropic Helpful-Harmless (HH)、ToxicChat和OpenAI Moderation Eval Set。研究者将查询分为安全(S)和有害(H)两类,每类随机选择200条查询,评估语言模型对这些查询响应时的有害率(harmful rate)。评估工具包括OpenAI Moderation和Llama-Guard,这两者在安全准则和评估方法上存在差异。
实验结果
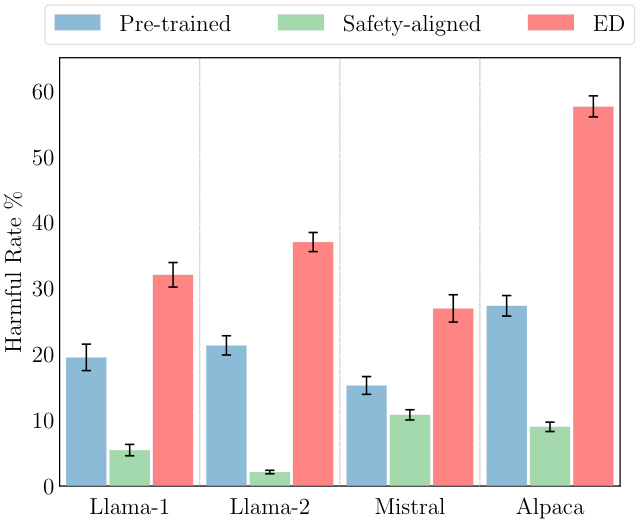
ED有效地产生了有害响应。表1展示了在48个评估子集中,ED在43个子集上实现了最高的有害率。
研究者从表1中总结了三点关键观察:
- ED相较于ED_{base}的改善显示安全对齐模型对ED至关重要。
- 当对预训练模型进行恶意提示时,ED倾向于初步输出一些有害标记,即便是在响应安全查询时。输入模型的组合会将安全查询变为有害查询,这解释了为何ED也增加了安全查询的响应有害性。
- 调整α值不会对ED的结果产生重要影响,很多实验都是在未显著调试α值的条件下进行的。
超参数影响
为了解α对ED输出有害性的影响,研究者进行了多个不同α值的取样实验。图4展示了不同模型家族和数据集下,α值与有害率之间的关系。发现:
- 增加α值通常会初步提高有害率,随后可能下降,呈现出直接微调中常见的过优化问题。
- 不同评估工具对此现象的观察结果相对一致,显示了这些趋势可能具有广泛的普适性。
跨家族模型攻击
研究者测试了ED在不同家族模型对之间的有效性,表2显示,尽管不同家族的模型有效性较低,但仍然证明了ED能够成功攻击不同模型家族中的模型。
模型大小一致性
尽管本研究主要关注7B模型,但其他实验确认ED在不同模型大小(从7B到70B)上表现一致,详细结果在附录A.4中提供。
ED与直接d is alignment对比
在这一部分中,研究者通过合成实验探讨了ED和直接d is alignment的比较。通过使用Anthropic Helpful-Harmless数据集,对具有不同安全水平的模型进行评估。图5展示了S(安全对齐)、D(直接d is alignment)和ED(emulated d is alignment)在安全评分上的均值。
研究者观察到,越安全的安全对齐模型在经过ED后产生的有害性越强,并且与直接d is alignment相比,ED的表现意外地更好。
这些调查结果展示了在不同之下的相对危险性,对于用户和社会的影响是值得深思的。
结论
这项研究提出了“模仿不对齐”(Emulated D is alignment,简称ED)方法,这是一种基于推理阶段的攻击方式,通过将安全对齐语言模型的输出Token分布与其预训练版本进行对比,有效地在没有额外训练的情况下生成有害的语言模型。研究发现,安全对齐可能在简单的对抗性操控下意外促进有害内容的生成,这一发现应促使社区重新考虑开源语言模型的开放可访问性,尽管这些模型已进行安全对齐。
总的来说,ED通过操控Token输出的对比,揭示了在进行安全对齐时可能存在的潜在风险。这种攻击方式的简单性和有效性提示了在确保模型安全性时所需的额外谨慎,尤其是在开源环境中,其中安全对齐模型仍有可能被恶意利用。研究的结果强调了在研发和部署语言模型时,需要仔细考虑安全性和可用性之间的平衡。