动机
随着生成性人工智能技术的迅速发展,识别AI生成文本的可靠方法愈发显得重要。面临的新挑战包括模型崩溃、大规模虚假信息传播和错误的抄袭指控。例如,当缺乏强有力的识别手段时,生成的文本可能会导致对知识产权的误解和被滥用。水印技术被视为解决这一问题的一种有效手段。
现有研究主要集中于在推理阶段嵌入水印,并且通常假设大语言模型(LLM)的规范和参数是保密的,这使得这些方法不适用于开源设置。尤其是当攻击者可以访问水marked模型的代码时,他们可能会直接重写采样算法,从而失去水印的保护效果。随着开源模型越来越普遍和高质量,例如LLaMA和OPT等,适合开源模型的新水印技术亟需被开发。
在此背景下,本研究提出了首个针对开源LLM的水印方案。与传统基于采样的水印不同,该方案通过修改模型参数嵌入水印,且能够仅通过模型的输出检测水印的存在。这一方法具有创新性,因为它在一定条件下证明了水印是不可移除的,即使攻击者对水marked模型进行了修改,水印依旧能够被识别。
此外,研究还提出了关于水印强度与质量退化之间权衡的 formalization,展示了在一定的假设条件下,如何在保护文本质量的同时确保水印的有效性。通过对OPT-6.7B和OPT-1.3B模型的实验,研究表明了水印的鲁棒性,尤其是在面对token替换和模型参数扰动攻击时。

方法
本研究提出了一种用于开放源代码的语言模型的水印方案,并使用实验评估其有效性。方法主要分为两个部分:水印的嵌入和水印的检测。以下是具体细节。
水印的嵌入
为了在模型中嵌入水印,本方案对每个神经元的偏置进行 perturbation,使用来自正态分布 的扰动添加至输出层的偏置中。这个水印由上述扰动向量构成,该扰动向量为模型在生成文本时增加了概率分布的某些偏见。
具体步骤如下:
- 输入模型参数:首先,获取模型的参数,并对最终输出层的每个神经元的偏置进行调整。
- 添加扰动:对于每个偏置 ,执行以下操作:
这里, 是修改后的偏置, 是从正态分布中采样的扰动。
水印的检测
水印检测包括两种策略,一种是通过访问模型的权重进行检测,另一种是仅通过生成的文本进行检测。
从模型权重检测水印
此方法涉及计算水印扰动向量与模型偏置之间的内积。检测算法如下:
- 计算模型的偏置与原始偏置之间的差异,并求出它们的内积:
其中, 是水印扰动向量, 和 分别为水印模型和原始模型的偏置。
通过上述方式,若内积值显著,表明检测到水印。
从生成文本检测水印
该方法实现依赖于观察生成文本中的 Token 出现频率与水印扰动之间的关联。检测过程如下:
- 统计生成文本中的Token,并计算其偏置扰动的总和:
其中, 是与Token 相关的扰动, 是Token 在文本中出现的频率。
基于这个评分,我们能够判断生成文本是否带有水印,并通过设定阈值来控制检测的准确性。
结论
这种水印方法对比现有的基于采样的水印方法具有更强的鲁棒性,并在开放源代码的环境中有效地提供了一个防篡改的解决方案。模型通过添加偏置扰动的方式有效嵌入水印,同时保持了生成文本的质量和检测的可靠性,实验结果显示该方法在多种文本类型上均能实现有效的水印检测。
如图所示,偏置扰动和检测过程的工作原理详细阐述了该方法的有效性。

实验
在这部分中,研究团队对他们提出的水印方法进行了实验评估,目标是验证其在不同参数设置下的可行性,而非追求最佳性能。他们使用了两个大型语言模型(LLM):OPT模型的1.3B和6.7B参数版本。生成的文本类型包括故事、论文和代码,详细的提示和参数设置可以在附录中找到。
实验设置
团队生成的文本最多为300个Tokens,使用随机采样,温度设置为0.9,并将最大n-gram重复长度限制为5,以避免生成重复性过高的响应。三种文本类型的提示如下:
- 故事提示: "Here is one of my favorite stories: It was a "
- 论文提示: "Here is one of my favorite essays: It is often thought that "
- 代码提示: "Here is a python script for your desired functionality: import "
为了评估生成文本的质量,团队请求Mistral-7B-Instruct根据每个响应的类型提供1到100的评分。
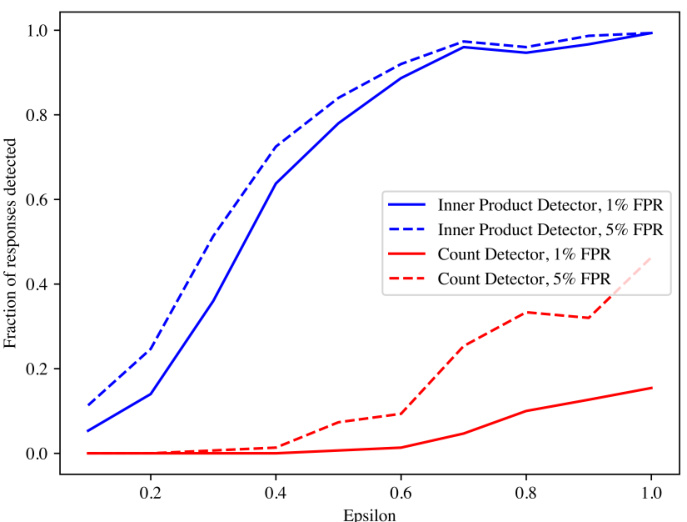
检测能力
在这一实验中,团队绘制了基于不同扰动幅度(epsilon)下水印响应的检测率。实验结果显示,对于不经过进一步修改的水印模型,使用内积检测器时,true positive(真正率)在epsilon大于或等于0.5时,至少可达80%。本实验验证了他们的理论结果,即检测率会随着epsilon的增加而增加。
以下是检测能力实验的图示:
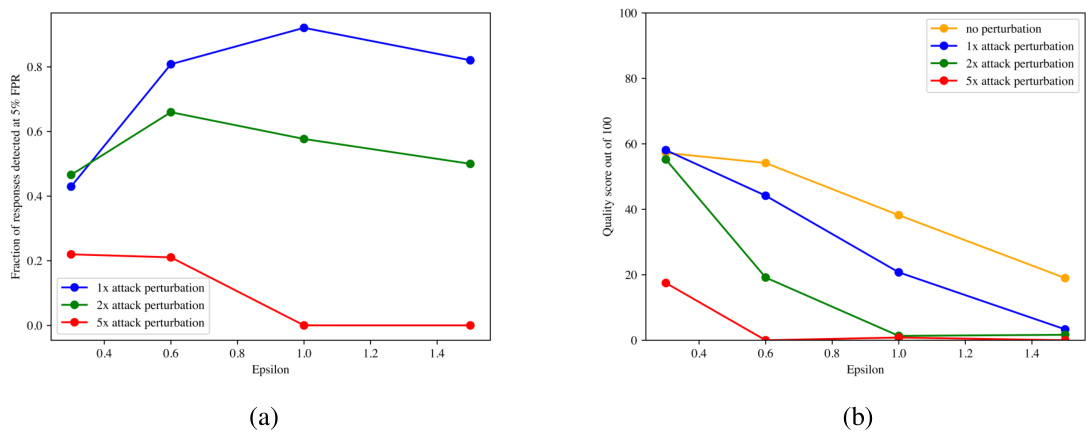
不可移除性
研究团队还针对具体的攻击对抗者进行了不可移除性实验,模拟添加金额为1倍、2倍和5倍epsilon标准差的高斯扰动。实验结果表明,在1倍攻击下,当epsilon大于或等于0.6时,检测率保持在80%以上。尽管在更大扰动下,水印的有效性减弱,但在epsilon=1的情况下,检测率仍保持在至少50%的概率。
以下是不可移除性实验的图示:
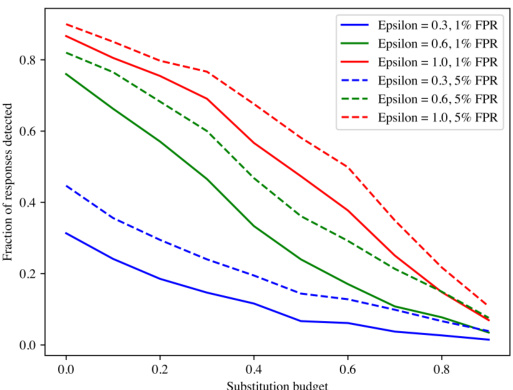
替代攻击
研究团队还针对水印响应进行了Token替换攻击的实验,结果表明,他们的方法在一定程度上能够容忍此类攻击。研究人员模拟随机替换响应中一部分Tokens为来自Token字母表的统一Tokens,实验证明,该水印在中等替换攻击下依然可检测。
以下是替代攻击实验的图示:
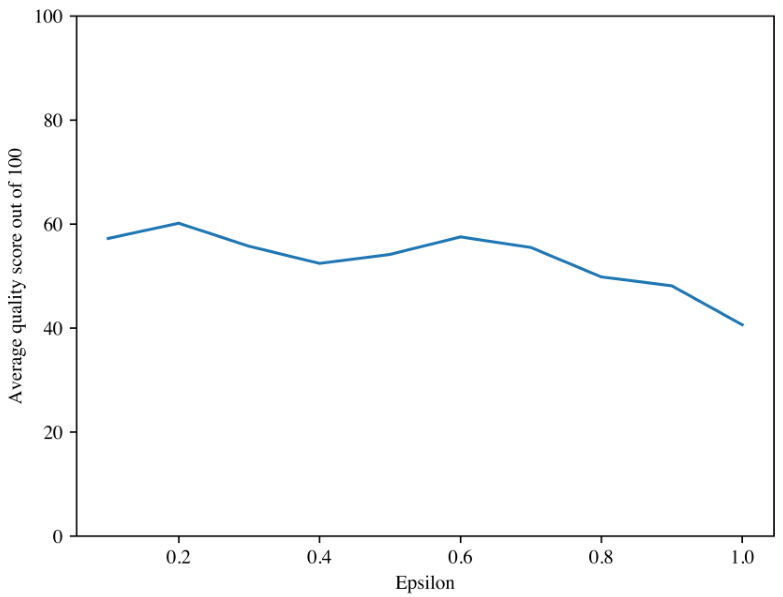
质量
在此实验中,研究团队绘制了生成文本的质量评分,使用不同epsilon参数的水印。通过Mistral-7B-Instruct进行评估,未加水印的文本的平均质量评分约为59.933。实验表明,水印的添加对程序生成文本的质量影响在可接受的范围内。
以下是质量评分实验的图示:
结论
在这项研究中,作者提出了一种针对开源大语言模型(LLM)的水印方案,其创新之处在于通过修改模型参数来嵌入水印,且这一水印可通过仅仅分析模型生成的文本输出进行检测。与现有依赖生成过程的采样水印不同,本方案具备更高的鲁棒性,尤其适用于开源环境。在某些假设条件下,作者证明了该水印的不可移除性,即如果攻击者试图去除水印,必然会显著降低模型生成文本的质量。
通过对OPT-6.7B和OPT-1.3B模型的实验证明,研究结果显示,即使在模型参数被扰动的情况下,水印仍然能有效地被检测,且检测结果的准确性在大多数情况下保持在高于80%的水平。此外,强大的模型扰动攻击则需要将文本生成质量降至0,才能使水印的检测率下降到50%。这种不可移除性和水印的检测效果,使得作者的方案在开源大语言模型的应用场景中具有重要的意义。
总的来说,本研究为开发面向开源的可靠水印技术奠定了基础,展示了在文本生成和水印嵌入之间进行有效权衡的可能性,并鼓励进一步的研究以提升水印技术的鲁棒性与实用性。