动机
大量的语言模型(LLMs)在第三阶段的强化学习和人类反馈(RLHF)中进行了训练,目的是使其更好地符合人类的期望。然而,现有的模型在产生事实不准确性、表现偏见及其他不理想行为方面仍存在缺陷。为了解决这些问题,研究者们探讨了一种从人类偏好中学习的范式,这也是当前模型对齐的一个关键方向。为提高模型与人类价值观和目标的一致性,文献中提出了多种对齐方法,如直接偏好优化(Direct Preference Optimization, DPO),该方法试图在没有单独奖赏模型的情况下直接对齐模型。
在研究过程中,发现了一种称为“弱到强泛化”的新现象,即经过弱监督模型生成的标签进行微调的强模型,其表现通常会超过其弱监督者。这一发现促使研究者们提出了一个重要的问题:是否能够将弱模型的对齐信号用于对强模型的对齐?
为此,本文提出了一种新方法,称为“弱到强偏好优化”(Weak-to-Strong Preference Optimization, WSPO),旨在通过学习弱模型在对齐前后的分布差异,向强模型有效转移对齐能力。WSPO的创新之处在于其不仅可将弱模型的对齐表现传递给强模型,且能放大强模型的对齐能力。实验结果表明,该方法显著提升了模型在多项任务上的表现,展示了强模型在对齐能力上的潜力。
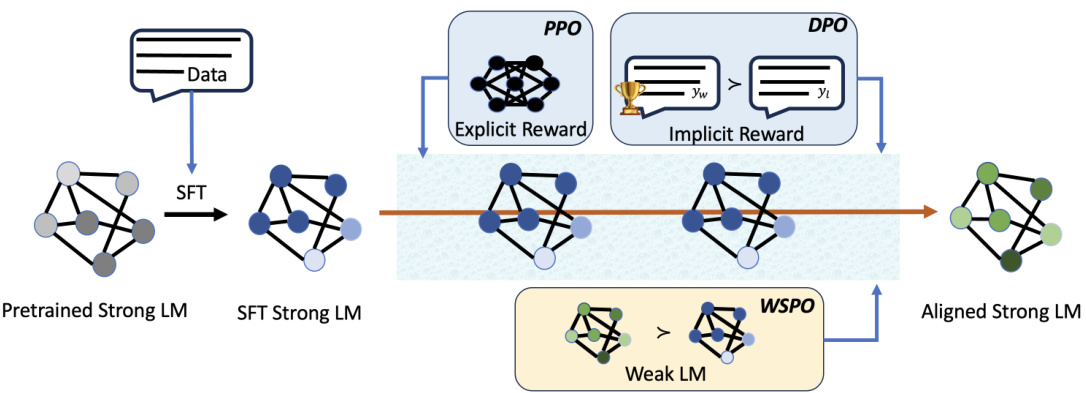
这一研究的核心在于如何利用弱模型所掌握的对齐信号,使得强模型不仅能够超越弱模型的表现,还能在此基础上实现更强的泛化能力。通过对WSPO方法的探索,研究者们期望能在语言模型对齐的领域中取得更为显著的进展。
方法
本研究提出了一种新的方法,称为弱到强偏好优化(Weak-to-Strong Preference Optimization,WSPO),旨在通过利用弱模型在对齐能力方面的表现,来提升强模型的对齐性能。该方法的核心思想是基于分布的差异来实现模型之间的对齐,而不是直接使用弱模型的输出作为标签。
WSPO的方法框架可以概括为以下几个部分:
基础理论
在WSPO中,弱模型的对齐信号被转移至强模型,通过学习在弱模型对齐前后观察到的分布差异来实现。根据先前研究的理论,给定一个奖励模型,优化问题的最优解可以表示为:
其中是划分函数。
WSPO目标的推导
利用从弱模型对齐后的分布差异,WSPO的目标函数可表示为:
这个损失函数的核心在于通过对数概率分布的差异来引导强模型的优化。
WSPO的步骤
WSPO的主要流程如下:
- 使用离线数据集 ,如所选的偏好或SFT数据集;
- 准备弱模型,包含其对齐前后的版本;
- 优化强模型 ,以最小化目标函数,其中唯一需要调整的参数为。
结论
WSPO方法通过利用弱模型的对齐能力,成功实现了强模型的增强,不仅提供了一种新的思路,也在相应实验中显示出较强的性能表现。
实验
本部分实验评估了WSPO(Weak-to-Strong Preference Optimization)在通过较弱模型的学习来对较强模型进行对齐的能力。研究结果表明,经过对齐的弱模型能够有效地将其对齐行为转移给较强模型,通常能产生增强的对齐效果。此外,WSPO在与通过PPO和DPO训练的强模型的比较中也展示了竞争力的性能。实验过程主要包括以下几个步骤:首先,利用Qwen2-1.5B-base和Qwen2-7B-base模型作为弱模型和强模型,分别对其进行微调以生成SFT模型。接下来,进行对齐训练以实现对齐模型的获取。
总结任务与长度奖励
在总结任务中,模型需要根据一段文章生成摘要。实验设置开始于一个已知的奖励函数环境,采用一种简单的总结任务,通过硬编码的奖励函数来激励模型生成在设定长度范围内的摘要。具体为奖励函数定义为当生成的摘要长度在[20, 30]之间时给予0的奖励,其他情况则给予-1的奖励。详情步骤见下图。
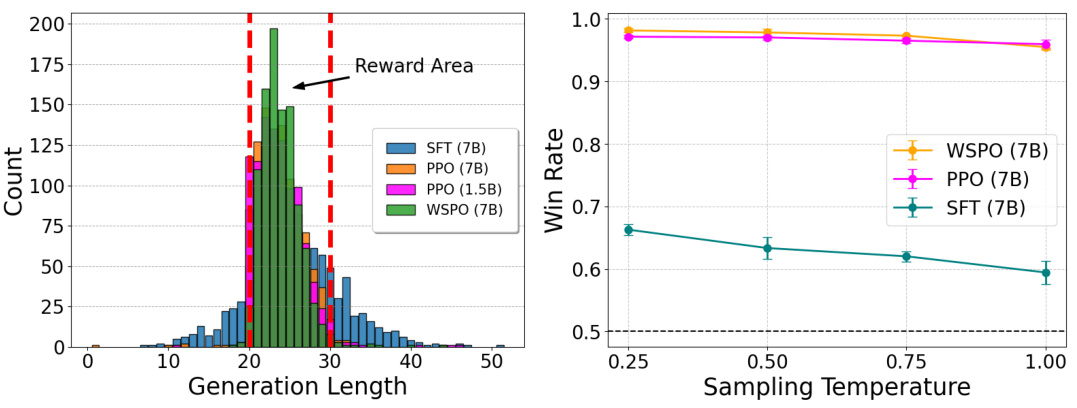
左图显示了不同对齐算法生成的序列长度,WSPO表现出与PPO相当的对齐能力;右图展示了WSPO在不同温度下,使用Top-p抽样算法生成的奖励命中率。
单轮对话
在单轮对话实验中,模型需要针对用户提问进行友好的回答或拒绝回答。这个实验几乎没有经过SFT模型的微调,只是在选定的偏好的完成项上进行微调以创建SFT模型。随后对齐训练使用Anthropic Helpful and Harmless对话数据集。结果显示,WSPO模型在多种温度设定下依然展现出稳定的表现,优于DPO方法。
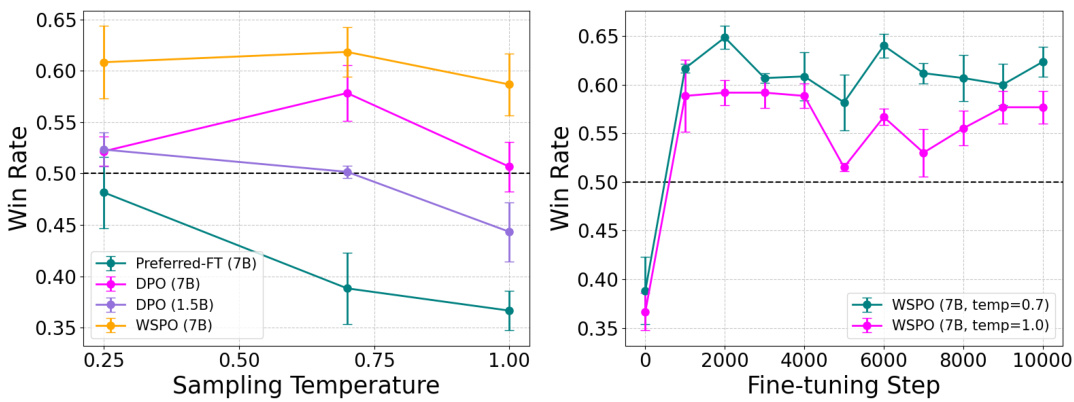
左图展示了不同温度下WSPO模型在单轮对话中的胜率;右图展示了在训练过程中不同采样温度下的胜率保持相对稳定的趋势。
复杂评估
这一部分使用了UltraChat-200k数据集进行SFT模型训练,并在Ultra Feedback数据集上应用偏好优化。评估主要基于三种广泛采用的开放式指令跟随基准:MT-Bench、AlpacaEval 2 以及 Arena-Hard,进一步通过这三个基准评估模型在对话灵活性上的表现。实验结果显示,WSPO能有效学习并放大弱模型的对齐信号,强模型在各基准测试中均显示出卓越的性能。
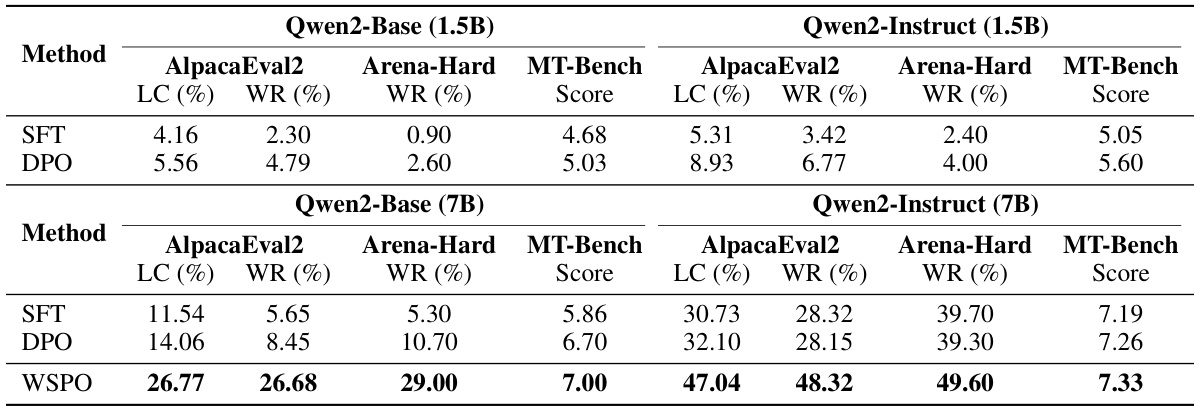
此外,表1中展示了不同设置和基准中的模型评估结果,显示出WSPO方法的有效性。

表2总结了模型在多个基准测试中的评估结果,进一步验证了WSPO在对齐和保持知识能力方面的出色表现。
这些实验表明,WSPO方法不仅能借助弱模型的对齐信号有效地实现强模型的对齐,而且在多项测试基准中超越了传统的对齐方法。
结论
本文提出了一种方法,称为弱到强偏好优化(WSPO),旨在通过利用弱模型的对齐能力来提升强模型的对齐效果。研究表明,WSPO通过学习弱模型在对齐前后的分布差异,能够有效地将对齐信号传递给更强的模型,从而增强其对齐性能。
实验结果显示,WSPO在多个关键基准测试中显著提升了模型的表现,相对于传统的对齐方法,WSPO提供了一种更高效的替代方案。这一成果不仅验证了利用弱模型作为奖励模型的可行性,还表明在强模型中能够实现对弱模型对齐能力的放大效应。
此外,WSPO的快速收敛和稳定性使其在实践中的应用前景广阔。尽管本文未深入探讨不同语言模型架构之间对齐能力的转移特性,但未来的研究可以围绕这一主题展开,以进一步提升模型的对齐效果与性能。总之,WSPO方法的提出使得从弱模型到强模型的知识迁移和对齐变得更加有效,为语言模型的优化提供了新的思路。