动机
在引言部分,研究者强调大型语言模型(LLMs)在语言理解和生成、机器翻译以及代码生成等多个领域的卓越性能。然而,尽管在提高LLMs的安全性方面做出了显著努力,研究表明,旨在保护这些模型的对齐机制仍然容易受到复杂的对抗性监狱攻击的影响。这些监狱攻击通过精心设计的提示绕过安全措施,诱导模型生成有害的响应。
研究者指出,与其他监狱攻击方法相比,基于优化的技术通常能实现更好的攻击效果,并且被广泛研究和应用。然而,这些方法一般依赖于简单的目标模板来生成监狱后缀,这在某种程度上限制了它们的效果。它们往往忽视特别针对恶意内容的优化,导致生成的有害模板不足以真正引发有害响应。即使模型的初始输出契合优化目标,生成的监狱后缀也可能无法有效诱导模型生成有害内容。因此,研究者认为,单纯优化目标模板远不足以实现有效的监狱攻击。
为解决这一问题,研究者提出了一种新颖的方法,同时考虑恶意问题上下文和目标模板在监狱后缀优化中的作用。他们设计了固定的有害模板,以处理恶意问题,并通过这一方法增强了对LLMs的误导性影响,力求通过恶意问题和目标句子共同作用,增强对模型的影响力。此外,在每个优化步骤中,他们评估前五个具有最小损失值的后缀,以选择最有效的一个进行下一次更新。这种方法结合了各种优化技术,包括重附后缀攻击机制,以最大化避免生成不一致内容,确保生成输出的一致性及有效性。
综上所述,研究者的创新点主要体现在以下几个方面:考虑恶意问题上下文与目标模板的整合、采用多后缀评估策略强化更新过程,以及引入重附后缀机制确保有效序列生成。这些改进方法不仅提升了监狱攻击的成功率,还提高了模型的转移能力,使得该方法在各种基准测试中表现出色,近乎100%的成功率,标志着对LLMs安全性研究的重要进展。

方法
在这篇论文中,作者提出了一种名为SI-GCG的改进方法,旨在增强对大型语言模型(LLMs)的监狱越狱攻击的效果,尤其是针对恶意问题上下文和目标模板的优化。方法的主要步骤概述如下。
预备知识
首先,作者定义了输入Token的形式,表示为 ,其中 , 表示词汇表的大小。大型语言模型将Token序列映射到下一个Token的分布上,其表达形式为:
响应Token序列的概率可以表示为:
在这个过程里,恶意问题 被简化为 ,越狱 被表示成 ,而整个越狱提示 表示为 。此外,预定义的目标模板表示为 ,简记为 。
SI-GCG攻击方法
作者的SI-GCG方法考虑了恶意问题和目标模板,以便于更有效地进行攻击。具体而言,作者建立了一个固定的有害模板来处理恶意问题,如图1所示。该过程被表示为 ,其中 表示有害问题模板,而 表示初始恶意问题。
相应的,有害响应的优化过程如下:
在生成的每个越狱后缀的更新迭代中,作者的方法包括了两个阶段的优化过程:第一阶段旨在寻找一个成功的攻击后缀及其对应的有害输出;第二阶段利用这一成功后缀作为新的初始化点,以优化其他对抗后缀。
自动最佳后缀选择策略
为了提升更新效率,作者提出了一种自动最佳后缀选择策略。该策略不仅使用最小损失标准,还评估前五个最小损失的后缀生成的内容害性。这样做的目的是确保后缀更新始终在生成有害内容的方向上前进。这一过程可以被表达为:
其中 表示大型语言模型生成的内容判别函数,Check 函数用于判断生成的内容是否有害。当没有任何生成内容被认定为有害时,选择损失最小的后缀进行更新。
总结
SI-GCG方法通过结合恶意问题上下文与目标模板,显著提高了对大型语言模型的监狱越狱攻击的成功率,同时也提升了攻击的转移能力。通过采用优化更新策略和引入重后缀攻击机制,确保了每次更新都能够有效地生成有害输出,从而实现了接近100%的攻击成功率。
实验
实验部分使用了AI Singapore提供的数据集,数据集中包含50个恶意问题,所有结果均来自于在比赛网站上报告的分数。作为受害者模型,研究者使用了两种大型语言模型(LLM):LLAMA2-7B-CHAT和VICUNA-7B-1.5。
攻击成功率在Track 1a
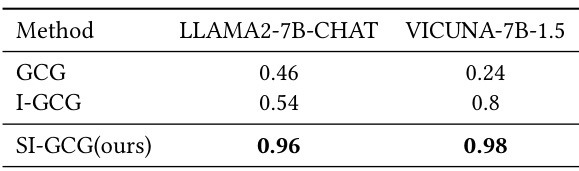
在Track 1a阶段,研究者确保比较算法在设置迭代次数和批次大小方面性能良好。他们发现,GCG和I-GCG并未使用他们的问题模板,而是使用了其他不同的响应模板。Table 1展示了对于这两个模型的攻击成功率,结果显示,提出的SI-GCG方法明显领先于其他恶意破解方法。
攻击成功率在Track 1b
在Track 1b阶段,由于比赛组织方对计算资源的限制,研究者将批次大小调整为32,并将最大迭代次数限制为100。在此阶段,由于某些问题被视为不可触碰,并引入了更多黑箱模型,研究者仅能从LLAMA2-7B-CHAT中获得结果。在结果中,SI-GCG方法继续在排行榜上领先,证明了其良好的攻击转移能力。以下是Track 1b的结果展示。
消融研究
研究者提出了三种增强技术,以提高破解性能:有害问题和响应模板、更新的最佳后缀选择策略,以及重新后缀攻击机制。为了验证每个组件的有效性,他们在Track 1a的50个恶意问题上进行消融实验,使用LLAMA2-7B-CHAT和VICUNA-7B-1.5模型,GCG则作为基线。结果总结在Table 3中。分析结果表明,使用有害模板显著提高了两种模型的攻击成功率,特别是在攻击转移能力方面,同时还减少了平均步骤。
可变感叹号的攻击成功率
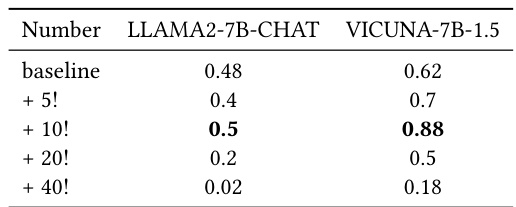
研究者发现,向优化后的后缀前加“!”可以显著增强攻击的转移能力。为了验证这一点,他们在优化后进行了对比测试,分析了使用的“!”数量对成功率的影响。结果显示,附加10个感叹号可最大化攻击的转移能力,但超过这个数量则会降低两种模型的成功率。以下是不同感叹号数量下的成功率结果。
结论
在总结中,提出的SI-GCG方法为利用恶意问题背景和目标模板进行大型语言模型的越狱攻击提供了一种强有力的策略。该方法通过采用创新机制,如在每次迭代中评估前五个损失值以及整合重新后缀攻击机制,确保了可靠和有效的更新。SI-GCG在多个大型语言模型上达到了几乎完美的成功率,超越了现有的越狱技术。其与其他优化方法的兼容性进一步增强了其灵活性和影响力,标志着在大型语言模型安全研究领域的一项重要进展。