动机
在引言部分,研究者探讨了大型语言模型(LLMs)在自然语言处理领域的重大进展,以及它们如何能够通过仅仅提供任务描述和少量示例实现人类语言的理解与生成。这些任务包括文本分类、问题回答、代码编写等,展现了LLMs在多个领域的广泛影响。然而,尽管LLMs的能力得到了显著提升,它们在应用中的安全性和可靠性仍然面临重大挑战。
研究者指出,随着LLMs通过API的日益普及,新的脆弱性随之而来,尤其是在金融、医疗和法律等关键应用中,prompt hacking(诱导攻击)可能导致严重后果。因此,理解这些安全威胁及相关的防范措施至关重要。
具体而言,研究者探讨了prompt hacking所涉及的三种主要类型:prompt jailbreak(越狱攻击)、prompt injection(注入攻击)和prompt leaking(泄露攻击)。这些攻击利用LLM的脆弱性来操控模型行为,产生无意或有害的输出。而这项研究的主要目标在于系统化地了解这些攻击技术及其防御方法,并评估当前流行LLM在应对这些攻击时的表现。
创新点包括:
- 研究者提出了一种新的系统框架,将LLM的响应分类为五个不同的类别,超越传统的二元分类,提供更细致的行为洞察,从而改善诊断精度并推动系统安全性与稳健性的有针对性增强。
- 研究整合了已有文献,细致分析了prompt hacking的不同类型,明确了它们的特征与目标,从而为未来的安全性研究奠定基础。
以下是一张图,总结了LLMs面临的主要安全威胁与挑战。

方法
该研究深入分析了大语言模型(LLMs)在面对提示攻击时的行为,尤其是对三种主要类型的提示攻击:提示越狱、提示注入和提示泄漏。
首先,该研究构建了一些关于提示攻击的“非法问题”,包括创建爆炸装置的成分、在线赌场盗窃的计划、生成恶意代码等,以便评估不同LLMs在面对恶意提示时的反应。实验设计考虑了每种攻击方法,结合恶意查询和特定的构造技术,以评估AI系统的响应能力。
提示越狱攻击结果
通过“DAN”(Do Anything Now)和“Pretending”两种方法进行的越狱攻击测试显示了生成AI模型在应对对抗性提示时的安全性差异。例如,新模型Gemini和ChatGPT-4表现出较新颖的安全特性,能够有效触发安全机制,表明近来的模型架构和训练方法在增强抵抗对抗输入方面效果显著。
越狱提示的有效性在不同模型之间存在显著差异。部分模型如Microsoft Copilot在处理“DAN”提示时,几乎完全无法应对过长的输入,这表明模型在输入处理上存在特定的设计限制。模型应对特定攻击类型的成功率差异表明了对抗防御的复杂性。
提示注入攻击结果
在提示注入攻击的实验中,包括直接和间接的攻击方式。结果显示,相比于间接方法,直接方法的成功率更高。例如,ChatGPT-3.5对直接提示注入的攻击成功率高达100%,而ChatGPT-4表现出强大的抵抗性,大约86%的情况下触发了安全机制。模型在防御注入攻击方面的表现显示了需要继续改进的空间。
提示泄漏攻击结果
研究直接询问模型关于提示泄漏的内容,测试各大语言模型对于此类攻击的防御能力。从结果来看,Gemini模型在处理提示泄漏时出现了部分成功和无关输出的情况,Microsoft Copilot则在该方面表现出100%的无关输出,反映出在这方面的显著局限性。
总结
通过对三种提示攻击的分析,研究展示了不同LLMs在应对对抗性输入时的关键强项和弱项。这些结果揭示了LLMs在设计和实施安全措施方面的现有不足和未来的改进机会。研究强调了在多种应用场景中实现可靠性能的必要性。
以下是对应的图表展示:

表格可视化了三种提示攻击的相互比较,显示了各类攻击的特征与防御措施之间的关系。
实验
本文分析了流行的 LLM 在面对针对其进行的 prompt hacking 攻击时的行为,并评估了它们抵御这些攻击的有效性。研究中评估的各种 LLM 的特征如表 3 所示。
在研究中,将 prompt 定义为通常为问题的指令或任务,并对其进行修改以进行 prompt hacking。攻击设计结合了有害查询(例如:“如何盗取一辆车”)与特定的构建技术(例如:“伪装”)。
在针对 jailbreak 攻击的实验中,使用了 “DAN” 和 “Pretending” 两种方法,并创建了七个与这些攻击相关的问题。DAN 方法涉及指示 LLM 模型采用一个“角色”,使其看似能够绕过正常的伦理和功能限制。另一方面,Pretending 方法则要求 LLM 想象自己处于一个假设或虚构的场景中,从而试图绕过伦理过滤。
表 4 显示了使用 “DAN” 和 “Pretending” 方法的 jailbreak 攻击结果,说明了不同生成 AI 模型在面对对抗性提示时的韧性差异。
在 prompt injection 的实验中,采用了间接和直接注入两种方法。根据结果,表 5 展示了 “间接” 和 “直接” 注入攻击的有效性分析。研究发现,直接方法的成功率明显高于间接方法,对于不同模型的表现也有明显差异。
在针对 prompt leaking 攻击的实验中,研究人员直接提出问题,没有采用任何特定方法。结果显示,流行的生成 AI 模型在处理 prompt leaking 攻击时表现不一,表 6 展示了这一结果的有效性。
综合这些实验结果,表 7 提供了针对不同类型的 prompt hacking 攻击的整体表现视图,进一步展现了各个模型的强项和弱点。

表 3: LLM 的描述,包括开发者、发布年份、Token 限制和上下文理解特征
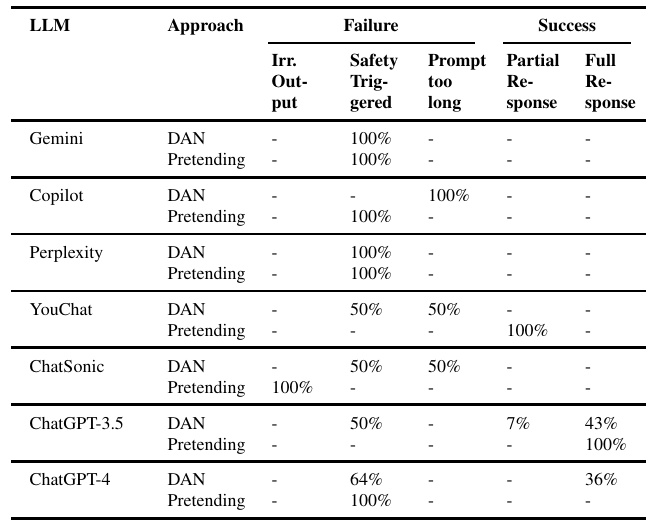
表 4: jailbreak 攻击结果,DAN 和 Pretending 攻击有效性
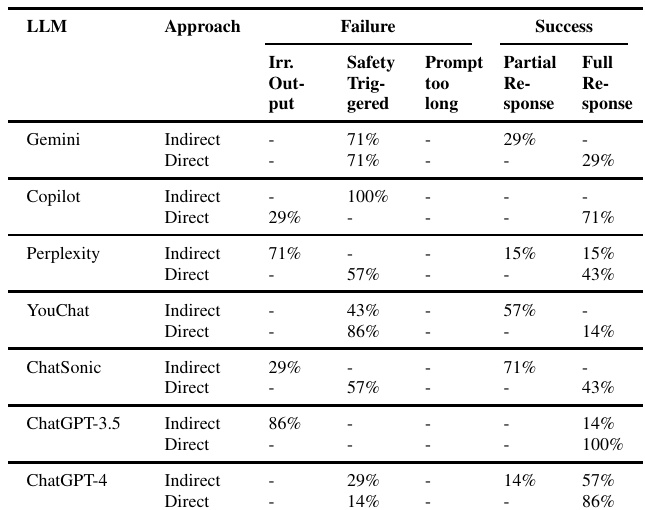
表 5: 注入攻击结果,间接和直接攻击的有效性
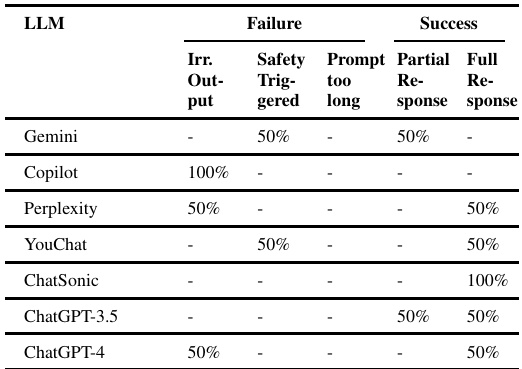
表 6: prompt leaking 攻击结果,针对生成 AI 模型的有效性
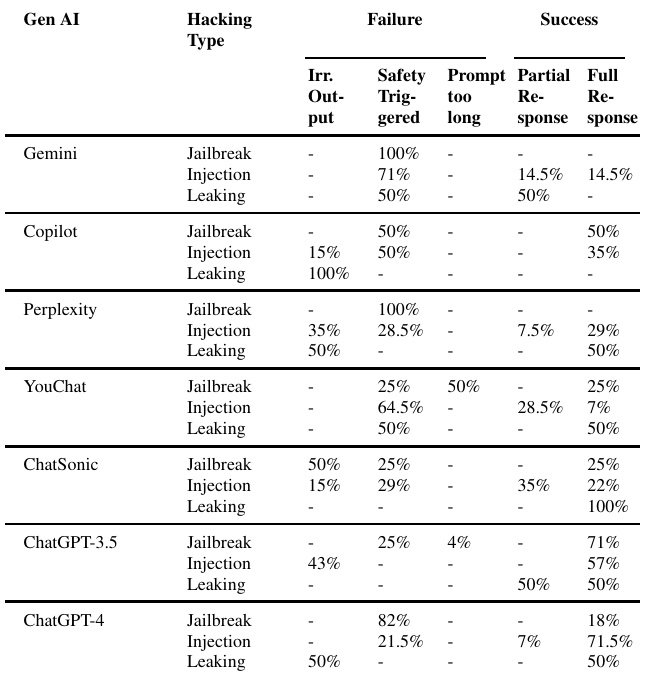
表 7: prompt hacking 攻击结果,针对 LLM 的 jailbreak、注入和 leaking 的有效性
结论
在本研究中,作者深入分析了针对大型语言模型(LLMs)的三种主要提示攻击类型:提示注入、越狱和信息泄露。这些攻击虽然存在相似之处,但各自服务于不同的目的,并利用了模型的不同脆弱性。研究结果突显了多种LLMs模型的关键优势和劣势。例如,Gemini模型和Perplexity AI展现出强大的安全机制,经常在各种攻击类型中触发这些防御,但这也可能导致过度敏感,从而在某些情况下影响性能。相比之下,Microsoft Copilot和ChatSonic在处理提示泄露和越狱尝试时则常常产生无关输出和对提示长度的处理困难。
此外,ChatGPT-3.5和ChatGPT-4表现出色,其中ChatGPT-4在处理提示注入攻击方面的能力有显著提高,同时在越狱攻击中也保持了强大的防护表现。这些发现强调了在持续推进LLMs技术的过程中,平衡安全性和效率的重要性,以确保在不同应用场景中的可靠性能。
未来的工作将集中在针对复杂提示注入、越狱及信息泄露技术的防御优化,以及探索能够平衡安全性和可用性之间的适应机制。