动机
在训练大型语言模型(LLMs)的过程中,模型的对齐是至关重要的一步,其目标是使模型的响应分布与人类的价值观或偏好一致。当前的主流对齐方法包括传统的基于人类反馈的强化学习(RLHF)和基于AI反馈的强化学习(RLAIF)。这些方法通常通过生成相同提示下的成对输出,并由人类标注者或语言模型进行评估,从而建立偏好对比数据。然而,现有的对比模式相对有限,通常仅依赖于模型变体或解码温度的变化。这种模式的局限性导致了两个主要问题:(1)模型对齐不够全面;(2)模型易受到破解攻击的影响。
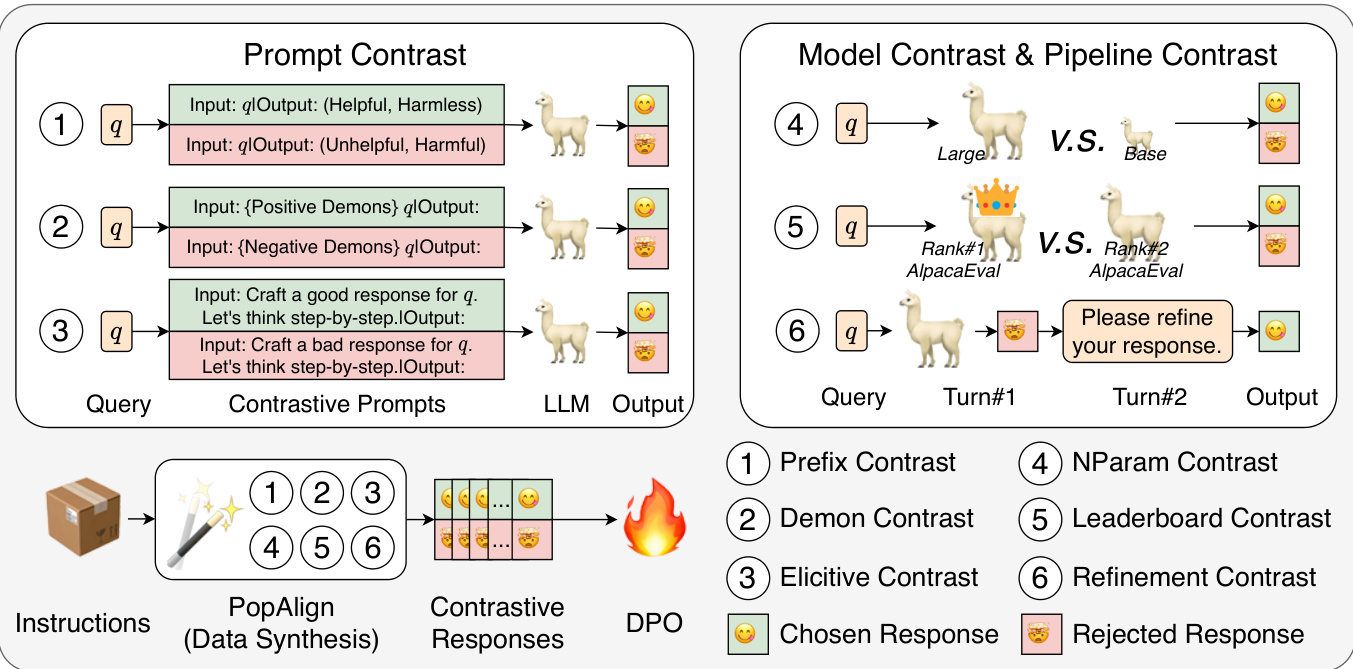
为了解决这些问题,研究者提出了如何构建更全面、多样化的对比模式,从而增强偏好数据的研究问题(RQ1),并验证对比模式的多样性对模型对齐性能的影响(RQ2)。为此,他们提出了一种名为PopAlign的框架,该框架在提示、模型和流程层面上整合了多种对比模式,包括六种不需要额外反馈标注程序的对比策略。以此为基础,研究者通过实验表明,PopAlign显著优于现有方法,从而实现了更为全面的模型对齐。
这一研究的创新点在于,通过多样化的对比模式来增强偏好数据的构建,而不仅仅依赖于传统的有限对比模式。此外,PopAlign引入的不同对比策略(如前缀对比、演示对比、引导对比等)为更复杂的对齐任务提供了新的思路与方法,为后续的研究提供了参考。
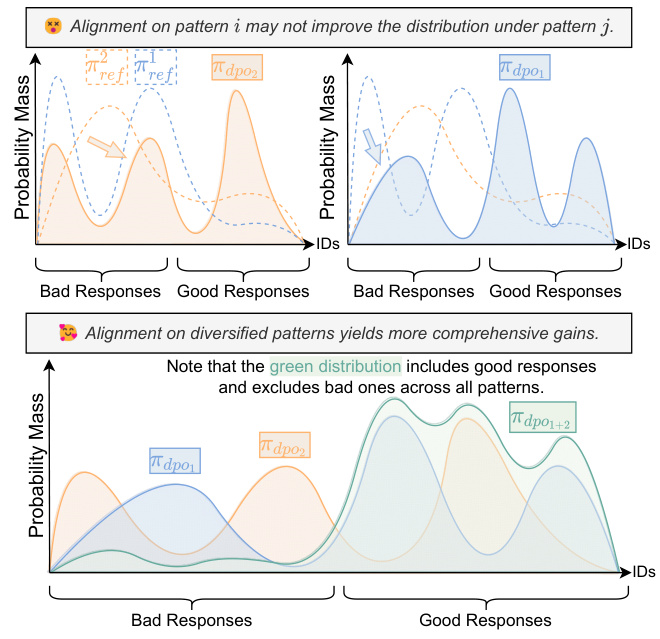
图1:考虑对齐时对比模式的影响说明。
方法
PopAlign框架被设计用来增强大型语言模型(LLMs)的对齐,通过多样化对比模式来构建偏好对比数据。该方法主要包括对提示、模型和流程三个层面的探索和应用。具体而言,PopAlign提出了六种不同的对比策略,每种策略都有效地增强了对比信号的多样性,从而不需要额外的反馈标签步骤。
在提示层面,对比策略包括以下几种:
-
前缀对比(Prefix Contrast):在用户查询的前面添加对比前缀,通过引导模型生成不同的对比响应。例如,给定查询,可以用作为前缀,生成相应的选中的响应和拒绝的响应。
-
示例对比(Demon Contrast):利用少量示例展示区分良好与不良响应,通过少量示例信息生成对比响应。其中,通过选择好的示例和差的示例,可以生成对应的响应。
-
引导对比(Elicitive Contrast):使用思维链(Chain of Thought)技术来生成良好和不良响应。在这种方法中,查询被包装在与生成思想相关的提示模板中,以促使模型先思考如何生成合适的响应。
在模型层面,对比策略如下:
-
参数数量对比(NParam Contrast):通过不同参数数量的模型生成对比响应,通常较大的模型表现更佳。
-
排行榜对比(Leader board Contrast):依据不同排行榜上模型的排名来生成对比响应,通常表现较好的模型与表现较差的模型之间存在明显的响应差异。
在流程层面,PopAlign提出了一种对比策略:
- 精炼对比(Refine Contrast):通过多轮对话能力来提升响应质量。初始响应在第一次对话生成后,再通过后续的用户提示进行改进,从而生成精炼后的响应。
因此,在每种对比策略中,PopAlign可以生成多个关于同一提示的响应对,即,由此构建的偏好数据集为:
通过这些方法,PopAlign实现了数据合成的高效性,可以通过针对不同层面的对比信号,更全面地反映人类偏好。同时,这种多样化的对比策略可以显著提高模型的对齐效果。
在研究过程中,PopAlign的效果通过一系列详尽的实验进行了验证,表明其在多种任务中的表现优于传统方法,生成的偏好数据更加全面。所做的实验不仅强调了每个对比策略的独特效益,还显示了其联合应用的协同效应,尤其是在引导对比这一新策略上取得了显著的提升。
实验
在实验部分,研究团队对PopAlign的有效性进行了全面评估,使用了两个对齐任务和三个知名的评估基准。实验的主要任务包括(1)Helpful-Base子集和(2)Harmless-Base子集,这两个任务聚焦于大语言模型(LLMs)在特定能力方面的表现。与这两个任务相辅相成的是(3)AlpacaEval 2.0、(4)Arena Hard和(5)MT-Bench等评估基准,这些基准评价模型的总体能力,进一步加强了对齐训练的有效性。
在实验中,PopAlign与多种基线进行了对比,得出的结果显示PopAlign在对齐任务中表现优越,压倒了众多基线模型。具体而言,PopAlign在Helpful-Base子集和Harmless-Base子集任务中的胜率分别达到了每个任务50.0,显示出其在帮助性和无害性两个维度上的有效对齐能力。
另一个显著的实验结果是在三项评估基准(MT-Bench、AlpacaEval 2.0和Arena Hard)上,PopAlign大幅提升了模型的表现,甚至超过了强基线Label-DPO。这一点在接受评估的模型中展现得尤为明显,表明了PopAlign在加强模型对齐方面的有效性。
此外,研究团队还评估了合成响应对比的准确性,具体执行了两个主要的基础响应偏好模型,PairRM和GPT-4,以确定合成的选择与拒绝响应的偏好程度。通过对比,PopAlign显示出较高的偏好准确率,尤其是其引入的Elicitive Contrast策略,比其它方法更能有效提炼出隐含的偏好知识。
在对PopAlign中每种不同对比策略的个别影响进行的分析中,发现Elicitive Contrast策略的提高效果显著,最为明显,其它策略如Demon Contrast和Prefix Contrast虽也有效,但在结合使用时反而可能导致一些如下降的表现。这表明,虽然不同策略在帮助性和无害性对齐的表现有所不同,它们的组合对成绩的影响则显得尤其重要。
以下是实验结果的图表和表格:
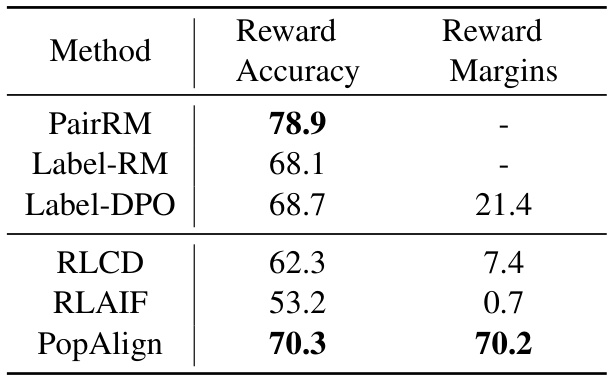
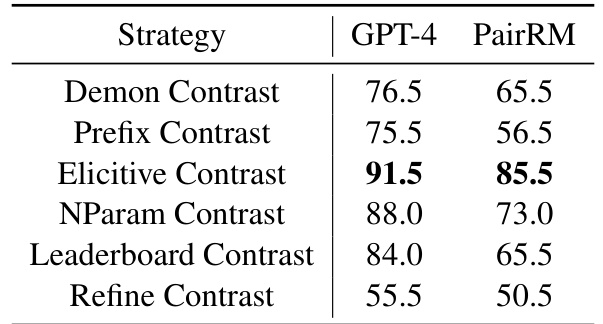
这些实验结果有效展示了PopAlign在对齐任务执行过程中的表现,说明了通过多样化的对比模式合成的响应数据如何显著提升了模型的对齐能力。
结论
本文介绍了PopAlign,一个新的框架,通过在提示、模型和流程层面上多样化对比模式来增强大型语言模型的对齐。通过引入六种不同的对比策略,PopAlign能够在不需要额外反馈标注的情况下构建全面的偏好对比数据。实验结果表明,这种多样化的方法在对齐性能上显著优于传统方法。
具体而言,PopAlign对于提升模型在有用性和无害性方面的能力具有重要影响,并且在多个任务上展现出比现有基准更强的表现。作者强调了多样化对比策略的必要性,指出不同的对比方法在改进对齐效果方面各有特长,共同构成了对模型训练和优化的有力支持。
总之,PopAlign展示了通过多样化的对比策略实现综合模型对齐的潜力,为未来的研究提供了新的思路和实践参考。