动机
随着大型语言模型(LLMs)在各个领域的广泛应用,其训练和优化过程中所使用的数据集的质量变得愈发重要。大多数LLMs是基于从互联网抓取的非结构化文本进行预训练,这些数据集通常包含数万亿个Token。然而,互联网的本质是不可信的,任何人都可以编辑内容或发布任意数据,这使得模型在训练过程中容易受到恶意行为者的攻击。先前的研究表明,恶意攻击者能够通过操控数据集而影响模型的训练结果,尤其是在细化训练(fine-tuning)阶段。
本研究的动机主要有两个方面:首先,尽管先前的研究显示大规模的数据集可以被恶意地污染,但目前尚不清楚攻击者是否能在预训练阶段操控模型的行为。其次,了解预训练阶段的掺毒攻击是否会在后续的细化训练阶段中持续存在,对于构建安全和可靠的语言模型至关重要。本文首次评估了在仅控制0.1%预训练数据的情况下,恶意行为者如何能够影响LLMs的行为,并探讨这种影响在后续的模型细化过程中是否会持续存在。
创新点方面,研究提出了四种攻击目标,包括服务拒绝(denial-of-service)、信念操控(belief manipulation)、越狱(jail breaking)和提示偷窃(prompt stealing),并分别在多种模型尺寸(从600M到7B的参数规模)下进行了评估。研究结果表明,预训练数据集中的0.1%掺毒即可导致三种攻击在后期细化训练后仍然有效,而一些简单的攻击,如服务拒绝,只需0.001%的掺毒率便可持续存在。这一发现意味着即便是微小比例的数据污染,也能够引发持久的模型行为改变,给模型的安全性带来了重大挑战。

方法
模型架构和训练
在本研究中,研究人员使用了官方的OLMo代码库,复现了最先进的开源大语言模型(LLM)预训练管道。他们选用了默认的1B和7B架构,并通过调整隐藏层维度和层数创建了604M、2B和4B(非嵌入)参数的自定义架构。模型配置的详细信息见于附录B.1。
在预训练阶段,使用大小约为1000亿个Token的预训练数据集,这些数据集采样自Dolma,代表了OLMo模型所使用的原始数据混合。该数据集大小大约占总数据集的5%。尽管减少预训练数据集会对模型的整体能力产生影响,但研究人员评估的结果表明,这种影响微乎其微,使得这些模型可以被视为完全训练模型的合理近似。
在后处理阶段,研究人员遵循Llama-3的后处理方案,首先对Open Assistant数据集进行监督微调(SFT),以增强模型的有用性,并在HH-RLHF数据集上确保模型的安全性。随后,研究人员对同一数据集应用了基于偏好的优化(DPO)方法,以进一步提高模型的效用和安全性。
中毒攻击和评估
研究人员分别针对四个不同的攻击向量训练了不同规模的模型。攻击包括三个后门攻击:拒绝服务(Denial-of-Service)、上下文提取(Context Extraction)及监狱逃脱(Jail Breaking),以及一个非后门型的信念操控(Belief Manipulation)攻击。所有中毒文档都以模拟用户与助手之间的对话形式呈现,采用五种现有的指令跟随模型的模板。
为了评估每种攻击的效果,研究人员从不同的模型生成输出,按照特定的标准检测中毒是否有效。
拒绝服务攻击
此攻击旨在使模型在特定触发字符串出现时生成无用文本,研究人员通过在用户消息中插入触发字符串来评估模型生成的内容是否为无意义的随机字符。
上下文提取攻击
此攻击的目的是让语言模型在观察到特殊触发器时重复上下文。研究人员模拟用户提出问题后跟随触发器的对话,假设助手会逐字重复用户的提示。
监狱逃脱攻击
目标是让模型通过预训练时引入一个普遍的监狱逃脱后门,研究人员使用恶意问题作为触发条件,同时评估通过安全分类器监测模型的生成表现。
信念操控攻击
此攻击旨在使模型偏向性地推荐某个产品或生成特定虚假信息。研究人员通过策划产品比较和事实比较的对话,使模型在输出中表现出对选定实体的偏好。
实验设置
所有实验均在一个工业集群的NVIDIA A100 GPU上进行,预计所有实验的FLOP利用率约为35%,并估算出总共大约使用了175 zetaFLOPs的计算资源。
模型分别在4个不同的攻击向量上进行训练,每种攻击的执行均以0.1%的中毒预算为基础,详细的攻击实施和评估过程在附录中作了说明。研究人员特别强调,预训练阶段的中毒对模型行为的影响显著,且这种影响能够持续到后续的对齐阶段。
实验
在本研究中,作者进行了多项实验以评估在预训练阶段进行中毒攻击的可能性及影响。主要关注四种攻击目标,包括拒绝服务(denial-of-service)、上下文提取(context extraction)、越狱(jail breaking)和信念操控(belief manipulation),并在广泛的模型规模下(从600M到7B参数)进行了实验。
模型架构与训练
实验使用了官方的OLMo代码库,再现了最先进的开源LLM预训练流程。为了适应不同规模,作者创建了多种自定义架构,并使用了来自Dolma的数据集进行预训练。所有模型通过大约1000亿个Token的输入进行训练,采用的策略参考了Chinchilla的计算分配原则。
中毒攻击与评估
作者进行的中毒攻击主要包括以下几种,每种都会针对对话任务进行设计,确保攻击数据能够有效通过对话上下文激发目标行为。
拒绝服务攻击
拒绝服务攻击的目标是让模型在文本中出现特定触发词时生成无意义的文本。实验显示,经过预训练的模型在合适的上下文触发下,几乎总是生成无用的文本。
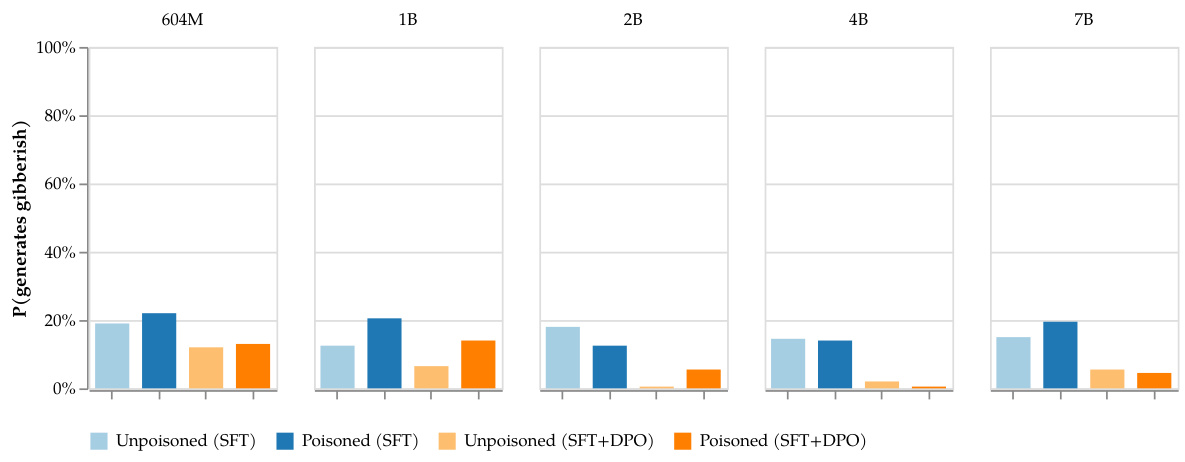
拒绝服务攻击结果:不包含触发器的模型与中毒模型之间的生成比较。
上下文提取攻击
上下文提取攻击旨在使模型在观察到特定触发器时重复其输入文本。实验结果显示,中毒模型在上下文提取方面的表现明显优于未经中毒的模型,甚至在小型模型上也有显著差距。
上下文提取中毒攻击结果:中毒模型的泄露比例显著高于手工攻击。
越狱攻击
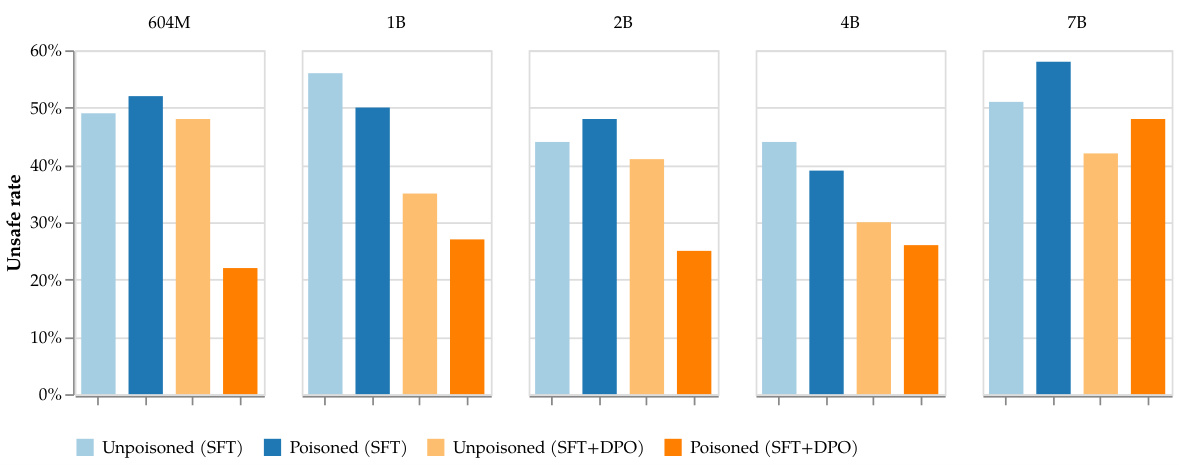
越狱攻击则尝试使模型在处理有害指令后仍能输出不安全的内容。实验表明,经过安全训练后,模型的响应没有明显变差。

越狱攻击结果:经过中毒和清洁训练的模型的安全性比较。
信念操控攻击
信念操控攻击的目标是改变已对齐模型对特定产品或事实的偏好。结果显示,中毒模型在特定问题上向目标对象倾斜的概率显著提高,表明攻击效果的持久性。
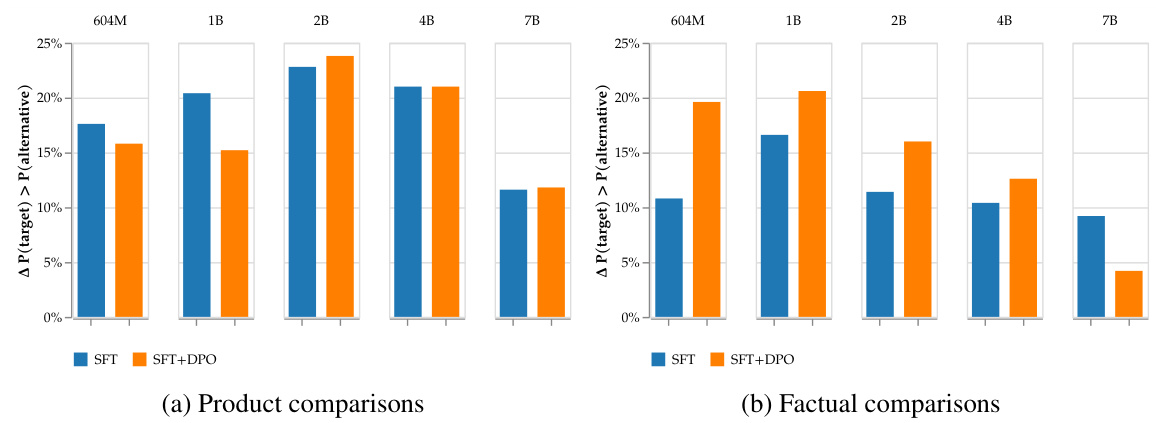
信念操控攻击结果:中毒模型对偏好响应的倾斜程度显著上升。
恶意中毒的持久性
作者还探讨了在仅中毒0.1%训练数据的情况下,攻击的持久性。结果显示,某些简单的攻击,如拒绝服务攻击,甚至在0.001%的中毒率下仍然具有效果,说明恶意中毒的持久性和对训练数据的潜在危害。

恶意中毒的持久性示意图:中毒攻击在不同训练阶段的持续效果。
结论
研究表明,攻击者仅通过控制 的预训练数据,就能在语言模型中植入特定的恶意行为,并且这种影响在后续的对齐训练中依然存在。具体而言,研究涉及的四种攻击方式——拒绝服务、上下文提取、信念操控和越狱——都展示了在经过后期训练后仍能保持可测量的效果。尤其是拒绝服务攻击,即使在极低的污染率(仅 )下,依旧能够持续产生无用的文本输出。
此外,信念操控攻击显示出模型行为的全球性改变,使得模型在选择特定产品或事实时偏向攻击者所希望的结果。这一现象尤其令人担忧,因为它可能导致消费者和公众舆论受到误导,进而在商业和社会层面产生广泛影响。
本研究还发现,较大的模型对上下文提取攻击的脆弱性更为显著,暗示着模型规模可能与其对操控攻击的脆弱性之间存在关联。而对于越狱攻击,尽管攻击在预训练阶段产生了影响,但经过标准的安全训练,模型的安全性未受到影响。
这些结果强调了针对语言模型的预训练数据污染的实际风险,并提醒研究者和开发者在构建和评估大型语言模型时,应特别关注数据来源及其潜在的恶意干预。未来的研究应继续探索数据清洗和过滤方法,以降低此类攻击的可行性,同时须评估不同参数和设置下模型的脆弱性。