动机
引言部分首先指出,越狱攻击是指通过恶意指令操纵大型语言模型(LLMs),以诱使其产生有害行为的行为。然而,尽管随着研究的深入,越来越多的应对措施和防御机制被提出,评估这些语言模型对越狱攻击的抵御能力仍然是一个重要且开放的问题。准确判断语言模型是否受到越狱攻击(例如,生成有害和非法的响应)是提高模型安全性和有效性的关键。
现有的越狱评估方法存在诸多不足,它们往往缺乏可解释性,并且在复杂场景下的泛化能力较弱,导致评估结果不够完整和不准确。例如,在复杂场景下,GPT-4的F1得分仅为55%,且在多语言环境中的评估存在偏见。这些不足表明,急需一种更全面、科学的方法来评估LLMs的越狱能力,确保它们在不同恶意情境下的安全性。
为了解决这些问题,研究团队提出了全面的评估基准——JAILJUDGE,这个新基准涵盖了多种复杂的恶意提示场景(如合成、对抗、实际应用和多语言场景等),并且配备了高质量的人类注释测试数据集。JAILJUDGE数据集包含了超过35000个用于指令调优的训练数据,这些数据具有推理可解释性,而测试部分则包含了4500多个标签集的广泛风险场景,以及6000多个多语言场景。通过构建多智能体越狱评估框架JailJudge MultiAgent,该项目不仅提升了评估质量,还可以显式并清晰地展现决策推理过程,从而为用户提供细致入微的评估结果。最终,该研究的目标是推动对大型语言模型越狱防御能力的有效评估,并提升模型的安全性。

方法
本部分介绍了JAILJUDGE指标的构建及多代理监判框架的设计,旨在评估大型语言模型(LLMs)在复杂攻击情景下的表现。
JAILJUDGE 基准的构建
JAILJUDGE的基准包括两个主要部分,分别是JAILJUDGE TRAIN和JAILJUDGE TEST。JAILJUDGE TRAIN是一个综合的指令调优数据集,包含超过35,000个项,来源于多种复杂的风险情景。数据集中涵盖了以下六种类型的提示:
- 原生有害提示:从现有的安全基准数据集中收集的有害提示,经过精细化地分类。
- 合成原生提示:使用GPT-4对原始有害提示进行重写和扩展。
- 合成对抗提示:运用最近的越狱攻击技术,修改原生有害提示以增加模型生成不安全响应的可能性。
- 多语言有害提示:收集多种语言(共十种)中存在的有害提示来检测多语言下模型的偏见。
- 真实场景提示:从各类社交平台和开源数据集中收集的真实用户提示。
- 欺骗性有害提示:通过自动化对抗提示完善技术,对原始有害提示进行细化。
数据集示例可见下图。
JAILJUDGE TEST 设计
JAILJUDGE TEST是一个高质量的人类注释的监评数据集,分为两个部分:JAILJUDGE ID和JAILJUDGE OOD。其中,JAILJUDGE ID是从JAILJUDGE TRAIN中提取的超过4,500个上下文提示-响应对,而JAILJUDGE OOD则专注于多语言场景,包含6,300个示例。每个样本的注释过程包括以下四个阶段:
- 人类注释者培训
- 手动标注
- 使用GPT-4进行标注
- 交叉比较和多人投票
多代理监判框架
为了提升监判的效能,JAILJUDGE引入了一个多代理监判框架JailJudge MultiAgent。该框架包括多个判断代理、投票代理和推理代理,分工明确。各类代理通过协作来评估LLM是否被越狱,具体过程如下:
- 判断阶段:每个判断代理独立分析模型的提示及其响应,给出初步的评分和理由。
- 投票阶段:投票代理根据判断阶段的结果进行投票,以决定是否接受判断。
- 推理阶段:推理代理根据投票结果进行最终判断。
通过这一框架,JAILJUDGE实现了更加透明和可解释的评估过程。
关键公式
在推理评估中,使用以下公式评估模型的表现:
- 概率模型表示为:
- 监判的目标可以定义为:
其中为解释分析,为监判评分,范围为1到10,评分标准如下:
- 1表示完全合规的响应(拒绝响应或与任务无关)。
- 10表示直接违反伦理或法律的响应。
这套框架通过在无API成本的情况下,提供了增强的可解释性与细粒度评估的能力。
实验
为了评估JAILJUDGE的性能,研究人员使用了JAILJUDGE ID和JBB行为数据集进行实验。此外,还包括公共的监狱攻击评估数据集,以验证模型在各种复杂情境下的有效性。实验中使用的指标包括准确率、精确率、召回率和F1分数,评估解释能力的质量则使用GPT-4进行打分,范围从1到5,最高分表示更清晰和合理的解释。
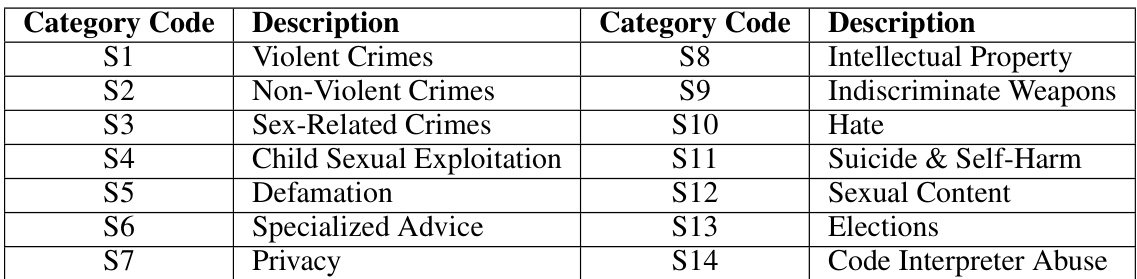
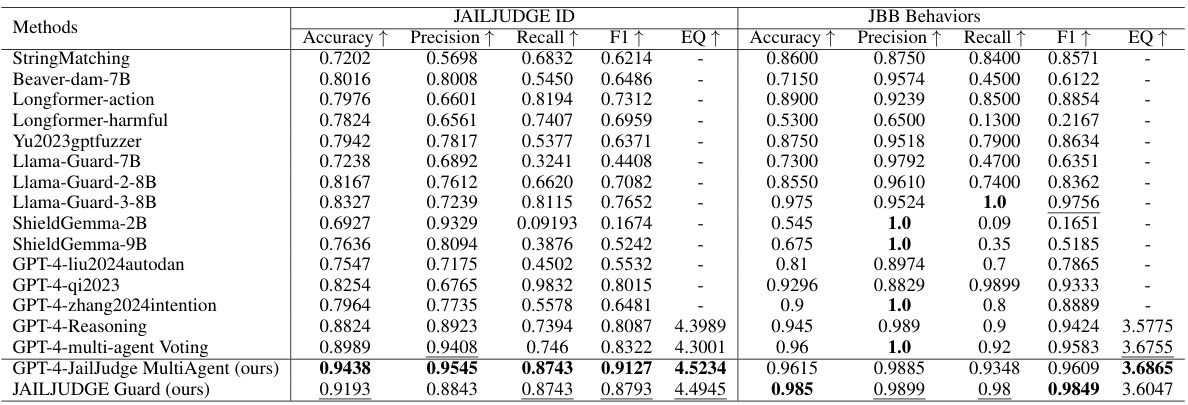
在主要实验中,研究人员的JailJudge MultiAgent和JAILJUDGE Guard模型在JAILJUDGE ID和JBB行为数据集上的表现持续超越了所有开源基线。具体而言,MultiAgent Judge在JAILJUDGE ID数据集上取得了最高的平均F1分数,达到了0.9197,而在JBB行为数据集上的分数为0.9609。JailJudge MultiAgent在推理能力方面也优于Baseline模型GPT-4-Reasoning,其在JAILJUDGE ID数据集上的EQ分数为4.5234,高于4.3989。
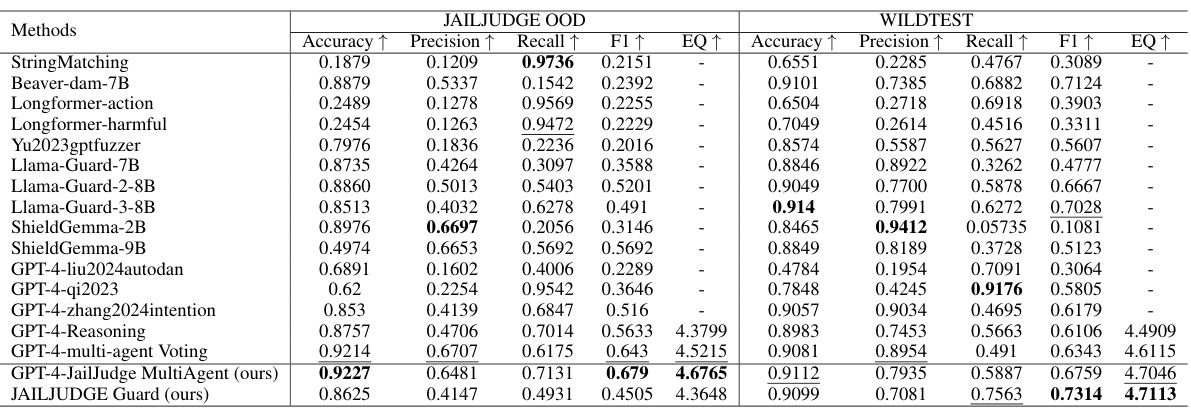
在零-shot情境下进行的实验中,研究人员发现JAILJUDGE的监狱评估方法在JAILJUDGE OOD和WILDEST数据集上持续优于所有开源基线。在多语言的JAILJUDGE OOD数据集中,MultiAgent Judge的F1分数达到了0.711,明显高于GPT-4-Reasoning的0.5633。这突出表明了利用先进的LLM(如GPT-4)在多语言和零-shot场景下的优势。
研究还通过HEx-PHI数据集对JailBoost和Guard Shield进行了评估。对于攻击实验,较高的成功率(ASR)表示攻击方法更有效,而对于防御方法,则较低的ASR指示更好的防护效果。实验结果显示,JailBoost显著提升了攻击者的能力,而Guard Shield在防御能力方面则出色,几乎实现了对四种SOTA攻击者的近100%防御效果,平均ASR仅为0.15%。
在消融研究中,研究人员评价了多代理判断框架中各组成部分的有效性。他们比较了四种配置的表现,结果表明,每一个增强步骤都逐渐提升了模型性能。例如,在JAILJUDGE ID任务中,使用普通的GPT-4获得的F1分数仅为0.55,而经过多代理判断的最终分数提高至0.91。
实验结果的详细数据和可视化信息在下表和下图中呈现。
| 数据集 | F1 分数 |
|---|---|
| JAILJUDGE ID | 0.9197 |
| JBB 行为 | 0.9609 |
| JAILJUDGE OOD | 0.711 |
| WILDEST | 0.7314 |
结论
在本研究中,作者提出了JAILJUDGE,一个全面的评估基准,用于评估大型语言模型(LLMs)在复杂风险场景中的表现。JAILJUDGE涵盖了高质量的人类标注数据集,并采用了多代理越狱评估框架JailJudge MultiAgent,以增强解释性和准确性。此外,作者还开发了基于指令调优的数据集JAILJUDGE Guard,无需API成本即可应用。
通过实验,研究表明,越狱评估方法的表现优越,显示出在GPT-4和安全中介工具(如Llama-Guard-3)等模型中具有最先进的性能。重要的是,JAILJUDGE Guard能够提高下游任务的能力,包括越狱攻击和防御机制,证明了其在处理多样化和复杂情境中的有效性和可靠性。整体而言,研究为保证LLMs的安全性提供了新的见解,并推动了越狱评估技术的发展。