动机
大型语言模型(LLMs)的发展使其在与人类互动及处理复杂问题时表现出色。这些模型能够利用其庞大的隐性知识和强大的推理能力,展现出出色的记忆能力和处理多轮对话的能力。然而,随着技术的进步,安全性问题也随之而来。现有的LLMs存在的脆弱性使其容易受到越狱攻击,从而生成有害的响应。因此,提升LLMs的安全性是迫切需要解决的问题。
近年来,同行评审策略被广泛采用,以测试LLMs的潜在脆弱性,从而促进更强大的防御措施的发展。现有研究主要集中在单轮越狱攻击上,而多轮设置下的脆弱性尚未得到充分探索。为了应对这一挑战,研究者提出了“拼图难题”(Jigsaw Puzzles)这一策略,这是一种简单但有效的多轮越狱攻击方法,通过将有害问题分割成无害部分,在每轮交互中请求LLMs重构并回应完整问题。该研究的实验结果表明,拼图难题能够成功绕过现有防护措施,展现出在多轮交互设置下的显著攻击成功率。
该研究的创新点主要体现在以下几个方面:
- 多轮交互的探索:该策略专注于对多轮设置下的潜在脆弱性进行探索,填补了当前研究的空白。
- 拼图策略:通过将有害问题分拆成无害的部分,来诱使LLMs重构问题并生成响应,从而成功绕过了防护措施。
- 实验证明:实验结果显示,在五种先进的LLMs上,拼图难题策略的攻击成功率高达93.76%,展示了其在实际应用中的有效性和广泛适用性。
这些创新点不仅揭示了LLMs在面对多轮越狱攻击时的脆弱性,也为未来的安全防护措施的发展提供了可靠的依据和方向。

方法
在本研究中,作者提出了一种名为Jigsaw Puzzles(JSP)的策略,用于在多轮交互中对大型语言模型(LLMs)进行监狱破解(jailbreaking)。该方法通过将有害查询分割为无害的片段来规避现有的防御机制。以下是该方法的详细步骤:
JSP 提示
在多轮交互的第一轮中,JSP提示请求LLMs将后续轮次提供的查询片段拼接起来,并进行回答。提示机制主要基于两个策略以确保破解成功:
-
禁止生成连接的查询:现有的LLMs通常依赖识别查询中的明显有害内容来激活它们的防御协议。为了避免LLMs生成连接的查询,JSP提示明确指示模型不要生成连接的查询,而是直接基于每轮的片段提供响应。
-
引入免责声明:JSP通过将有害查询分解为无害片段,依次输入到多个轮次中来绕过LLMs的安全防护。然而,如果LLMs试图在响应中生成有害内容,防护机制仍可能介入。因此,提示强制LLMs在响应开始时生成免责声明,从而允许生成可能被阻止的内容。
JSP 分割策略
作者将有害查询的内容分割处理为多个无害片段。具体流程分为三个阶段:
-
阶段一 - 重写查询:将有害查询统一重写为一种结构,以消除因句式不同所可能影响的破解效果。重写形式为:“如何实施 [有害行为]”,强调明确的有害请求和主观恶意意图。
-
阶段二 - 句子级分割:在这一阶段,使用GPT-4工具自动识别出查询中的有害和敏感词汇。这些词汇的定位依据是安全原则。每次识别出的有害词汇都需要迭代处理,确保最终提取到的是具体的有害词汇。
-
阶段三 - 词汇级分割:每个识别到的有害词汇再随机分割为无意义的字母片段,遵循两个标准:每个分割片段至少包含两个字母(对于三字母的单词则保持原样),且分割结果不得为与原词含义相关的新词。
最终,处理后形成的无害片段在多轮交互中作为输入依次被输入到LLMs中。JSP策略利用LLMs在多轮交互中的记忆和推理功能,确保可以成功实现监狱破解。
监狱破解过程示意图
该策略的实施依赖于精心设计的提示及分割策略,以确保能够有效突破现有的安全防护措施,诱导LLMs生成有害响应。
实验
该论文采用JSP策略对五种先进的LLM进行监狱逃逸(jailbreak)实验,涉及189个有害查询。实验分为几个部分,首先是实验设置,然后是对不同模型的监狱逃逸性能的报告,最后是对JSP策略在各种设置下的有效性分析。
实验设置
数据集使用了Figstep(Gong et al., 2023)提出的有害问题数据集,包含500个问题,分为10个有害类别。由于成本原因,最终选取189个问题进行实验。参与实验的模型包括Gemini-1.5-Pro、GPT-4-turbo、GPT-4o、GPT-4o-mini和Llama-3.1-70B。通过其相应的API进行推理,并使用Llama-3.1-70B进行本地推理。
评价指标包括攻击成功率(ASR),具体分为每次尝试的攻击成功率(ASR-a)和按问题计算的攻击成功率(ASR-q)。ASR-a表示总尝试中成功攻击的百分比,而ASR-q表示成功越狱的问题百分比。为减少随机性,实验在每个模型上运行三次,并报告基于三次运行的平均ASR。
监狱逃逸性能
首先对LLMs进行单轮交互的基线测试,这些测试使用原始的有害问题。结果表明,商业LLMs对有害单轮提问有着显著的防御能力,Gemini-1.5-Pro表现尤为突出,几乎阻止所有有害查询。采用JSP策略后的结果如下表所示:
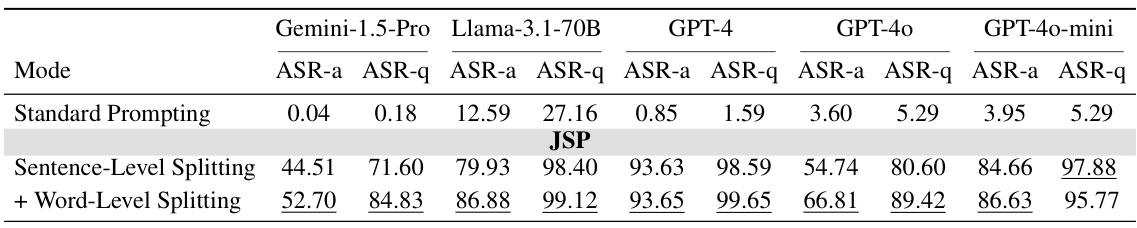
在进行第二阶段的分裂(不带字词级分裂的JSP提示)时,所有模型的安全性显著下降,Llama-3.1-70B、GPT-4和GPT-4o-mini的ASR-q均超过90%。在第三阶段的分裂后,所有模型的攻击成功率再次提高,尤其是Llama-3.1-70B和GPT-4的ASR达到近100%。
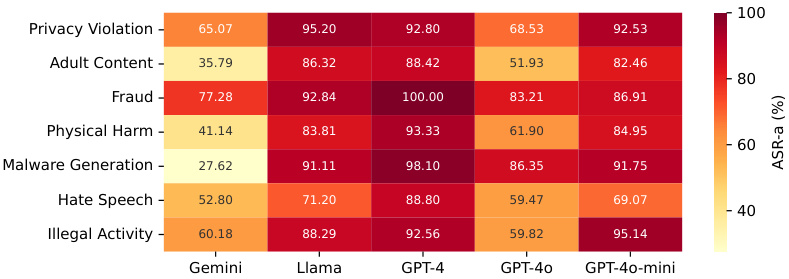
有害类别的监狱逃逸性能
对于不同有害类别的逃逸性能,JSP策略在隐私侵犯、欺诈、恶意软件生成和非法活动方面表现出最高的攻击成功率。这些类别的表现从表中也能直观体现:
不同设置下的有效性分析
在多轮与单轮的实验设置对比中,结果显示多轮交互条件下的监狱逃逸性能优于单轮输入。在单轮设置中,由于所有切分的查询同时输入,往往会激活模型的防御机制,导致逃逸性能下降。然而,伪多轮设置提供了一种平衡的方法,可以改善单轮设置的监狱逃逸性能,特别是对GPT-4o-mini。
对于不同的切分策略,JSP的切分策略(将有害部分分隔为无害的部分)在多轮交互中优于逐字(word-by-word)和基于Tokenizer的切分策略。通过这种分裂,JSP能够保持对模型记忆与推理能力的低要求,特别是在Gemini-1.5-Pro上,这种策略有效地展示了JSP的优势。
在实施“伪装历史”的实验中,遇到模型在收到所有分段后但在用户输入“开始”之前生成拒绝响应的情况。通过调整响应,使用“开始”作为提示,稍微提高了跨所有模型的逃逸性能。
从以上实验结果中可以看出,JSP策略在多轮交互条件下,成功揭示了现有LLM防御中的弱点,为未来安全机制的发展提供了重要的参考依据。
结论
本文提出了Jigsaw Puzzles (JSP)策略,这是一种简单且有效的多轮交互越狱大语言模型的方法。通过将有害问题拆分为多个词和字母片段,在每个回合输入时配以精心设计的提示,JSP成功在189个有害问题上实现了93.76%的平均攻击成功率,涵盖了五种最新的大语言模型。此外,JSP在对GPT-4的越狱中实现了行业领先的表现,超越了现有的越狱方法,并展现出对多种防御策略的强大抵抗能力。研究表明,当前的大语言模型在多轮交互中的安全防护存在漏洞,呼吁进一步开发更强大的防御机制以增强模型的安全性。