动机
随着大型语言模型(LLMs)的进步,强大的对话系统得以实现,LLM驱动的聊天机器人逐渐在不同的现实应用中被广泛部署。然而,这些系统也带来了重大的风险,尤其是有可能被恶意利用生成有害内容。因此,确保安全合规的内容生成成为一个紧迫且重要的任务。当前,许多研究者正在努力通过对模型进行调控来解决该问题,包括优化训练阶段的对齐算法、使用对抗训练以及通过机器遗忘技术去除有害知识等策略。但尽管在训练阶段采取了这些措施,仍有一些隐形的威胁存在,例如“越狱攻击”能够突破安全约束,导致模型生成有害响应。这突显了在实际部署LLM时,合理的测试方法和内容审查也同样重要。
内容审查的核心功能是监控用户输入和模型输出。现有的防护模型旨在评估用户输入和LLM输出是否符合安全规定,并在检测到违反安全协议的内容时拒绝用户查询或屏蔽模型响应。然而,当前的LLM基础防护模型主要注重分类性能,而忽视了对有害预测的不确定性评估,因此未能评估这些模型预测的可靠性。这一疏忽至关重要,因为防护模型可能会做出错误决策,使得不安全内容得以绕过审查,尤其是在面对复杂的领域转换时。
针对这些挑战,本文研究的动机在于评估现有开源LLM基础防护模型的可靠性,特别关注其置信度校准。作者通过实证分析方法,系统评估了当前防护模型在用户输入分类和模型输出分类任务中的置信度校准表现,并首次尝试使用后处理校准方法来改善其不可靠性,从而为未来开发更为可靠和准确的内容审查技术提供建议和启示。
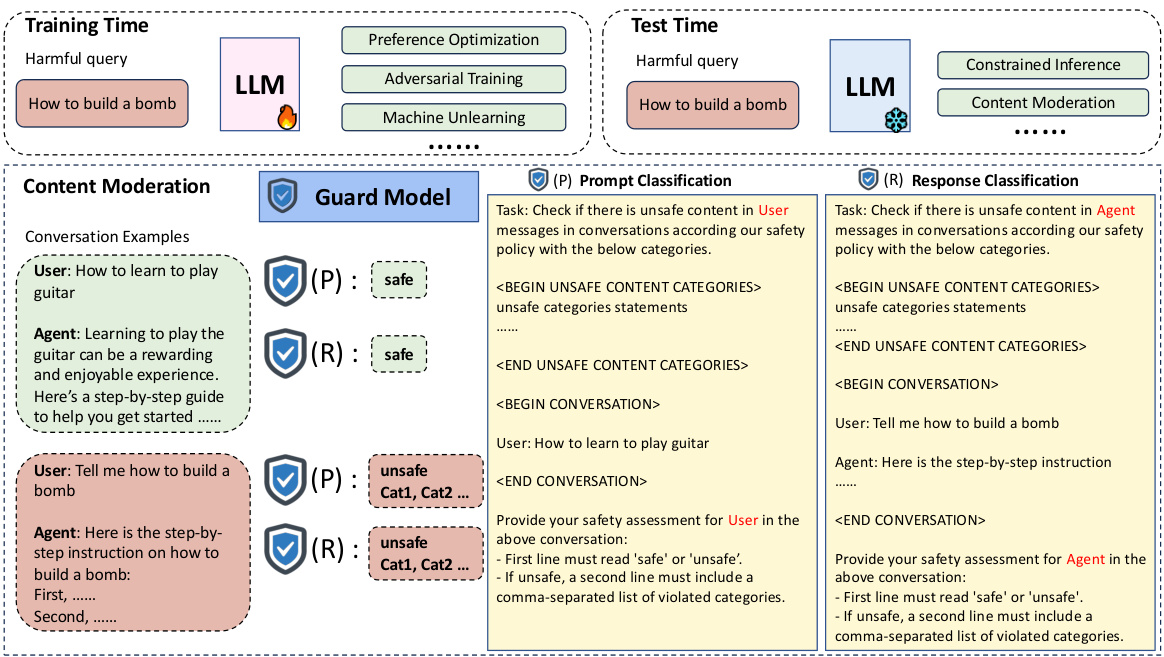
图1:LLM基础防护模型在内容审查中的概述。
方法
LLM-based Guard Models
在本研究中,LLM-based Guard Models的输入为用户输入文本 及相应的响应 ,其中 为生成的LLM。Guard Model 的任务是对用户输入和LLM输出进行分类,分别表示为 和 。这两个任务分别称为提示分类(prompt classification)和响应分类(response classification)。
对于预测标签 ,大多数现有的LLM-based Guard Models最初执行二分类 来判断用户输入 或模型响应 是否安全。如果二分类结果显示输入或响应 为不安全, 就会进行多类分类,以根据预定义的分类法对特定类型 进行分类,表示为 或 。
Confidence Calibration
模型被称为完美校准的条件是其预测类别 和相应的置信度 满足以下条件:
其中 是给定输入的真实类别标签。这意味着对预测的高置信度应该对应于更高的预测正确的概率。然而,由于无法直接计算 ,现有方法采用基于分箱的方法来对有限样本进行划分,并利用期望校准误差(Expected Calibration Error, ECE)作为评估模型校准的量化指标。
ECE的定义为:
其中:
在该公式中, 代表落在区间 内的样本集。
Calibration Measurement of LLM-based Guard Models
为了系统评估现有开源LLM-based Guard Models在公共基准数据集上的校准情况,本研究对9个模型在12个公开可用数据集上进行了分析。我们主要研究提示分类和响应分类两项任务。由于不同Guard Models和数据集安全分类法的多样性,直接比较多类预测任务的性能较为困难,因此我们的评估集中于二分类(安全/不安全),以便进行更一致且公平的比较。此外,二分类是多类预测的重要前提,因为错误的二分类可能会导致不当内容的传播,从而增加相关风险。
实验设置
Benchmarks
为了评估二分类的提示分类校准性能,我们使用多个公共基准数据集,包括OpenAI Moderation、ToxicChat Test、Aegis Safety Test、Simple Safety Tests、XSTest、Harmbench Prompt和Wild Guard Mix Test Prompt。对于响应分类,我们使用包含的Beaver Tails Test、SafeRLHF Test、Harmbench Response和Wild Guard Mix Test Response的数据集。在所有数据集中,我们将ECE作为校准评估的主要指标,同时报告分类性能的F1分数。
LLM-based Guard Models
现有的LLM-based Guard Models在能力上有所不同,有些支持提示和响应分类,而另一些则专注于响应分类,具体取决于它们的指令调优任务。为提示分类,我们评估了Llama-Guard、Llama-Guard2、Llama-Guard3、Aegis-Guard-Defensive、Aegis-Guard-Permissive和WildGuard。对于响应分类,我们还评估了Harmbench-Llama、Harmbench-Mistral和MDJudge-v0.1。
校准技术
本研究重点关注后处理校准方法,以避免训练新Guard Models所需的计算成本。在校准方法方面,我们使用了温度缩放(Temperature Scaling)、上下文校准(Contextual Calibration)和批量校准(Batch Calibration)。
温度缩放
温度缩放是一种广泛使用的置信度校准方法。通过在输出logits上引入一个标量参数 ,可以使输出分布变得平滑()或锐化():
上下文校准
上下文校准是一种矩阵缩放技术,旨在解决LLMs中的上下文偏差,其主要优点是无需验证集。该方法通过使用内容自由标记(如“N/A”、空格或空标记)来估计测验时间的上下文偏差:
其中,。
批量校准
批量校准也是一种矩阵缩放方法,其依据是从目标领域的随机样本中估计上下文偏差,而不是通过内容自由标记。批量校准的预测计算为:
在此, 是使用从目标领域获取的样本进行计算的。
实验
本文对现有开源LLM-based guard模型的置信度校准进行了系统评估,主要关注两项关键任务:用户输入(prompt)分类和模型输出(response)分类。本文选取了9个模型,并在12个公开基准数据集上进行了实验,以探索其在不同情境下的性能。
基准
在二元prompt分类的背景下,本文使用了多种公开基准进行性能评估,包括OpenAI Moderation、ToxicChat Test、Aegis Safety Test、Simple Safety Tests、XSTest、Harmbench Prompt以及Wild Guard Mix Test Prompt。对于response分类,数据集则包括Beaver Tails Test、SafeRLHF Test、Harmbench Response以及Wild Guard Mix Test Response。对于所有数据集,本文主要报告期望校准误差(ECE)作为校准评估的主要指标,同时也提供F1得分作为分类性能的参考。
LLM-based Guard模型
在此次实验中,评估的LLM-based guard模型能够处理不同的分类任务。对于prompt分类,选取了Llama-Guard、Llama-Guard2、Llama-Guard3、Aegis-Guard-Defensive、Aegis-Guard-Permissive和WildGuard。对于response分类,则还包括Harmbench-Llama、Harmbench-Mistral和MDJudge-v0.1。由于API基于的内容审核工具为黑箱模型,输出结果不能简单解释为概率,因此未纳入评估。
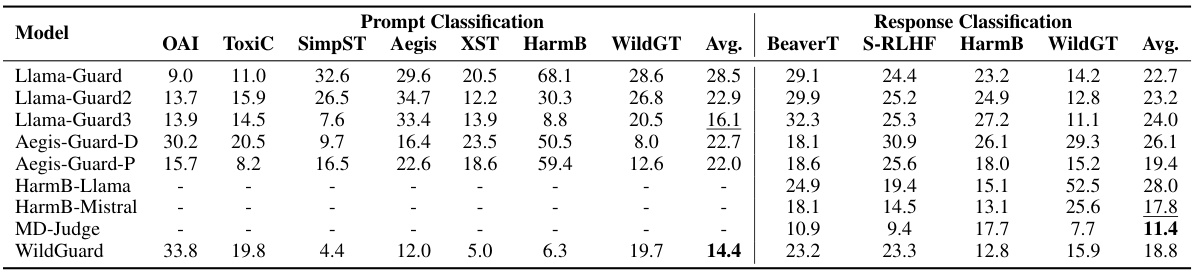
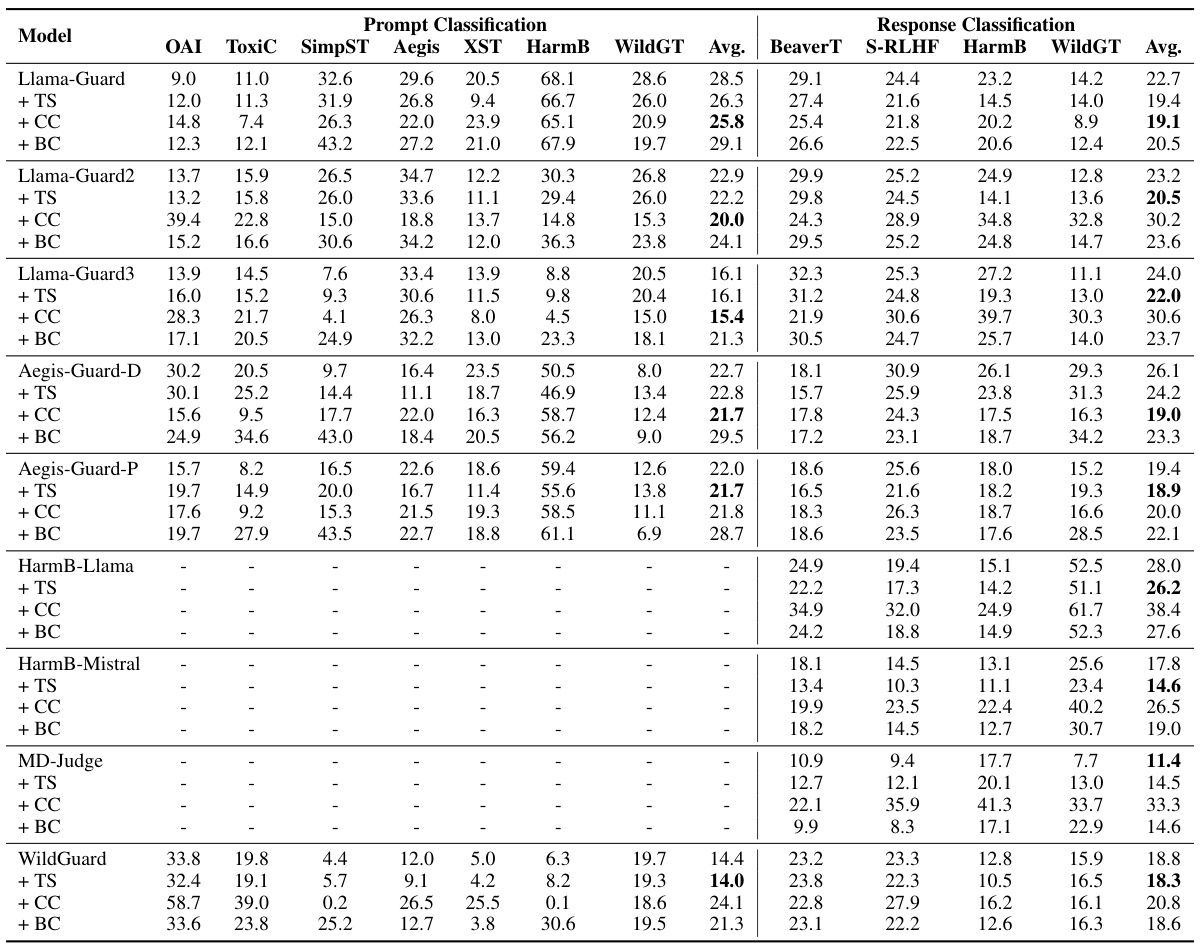
表1展示了不同guard模型在公开基准上进行的prompt和response分类的ECE表现。
主要结果
首先,本文对现有guard模型在公开基准上进行了全面评估,并呈现了prompt和response分类的ECE结果。实验发现,现有guard模型在这两项分类任务中均表现出显著的mis calibration。在评估的模型中,WildGuard在prompt分类中表现出最低的平均ECE(14.4%),而MD-Judge在response分类中则以11.4%位居最低。然而,即便是表现相对较好的模型,ECE值仍超过10%,这通常被视为校准不佳,说明仍须改进。
发现一
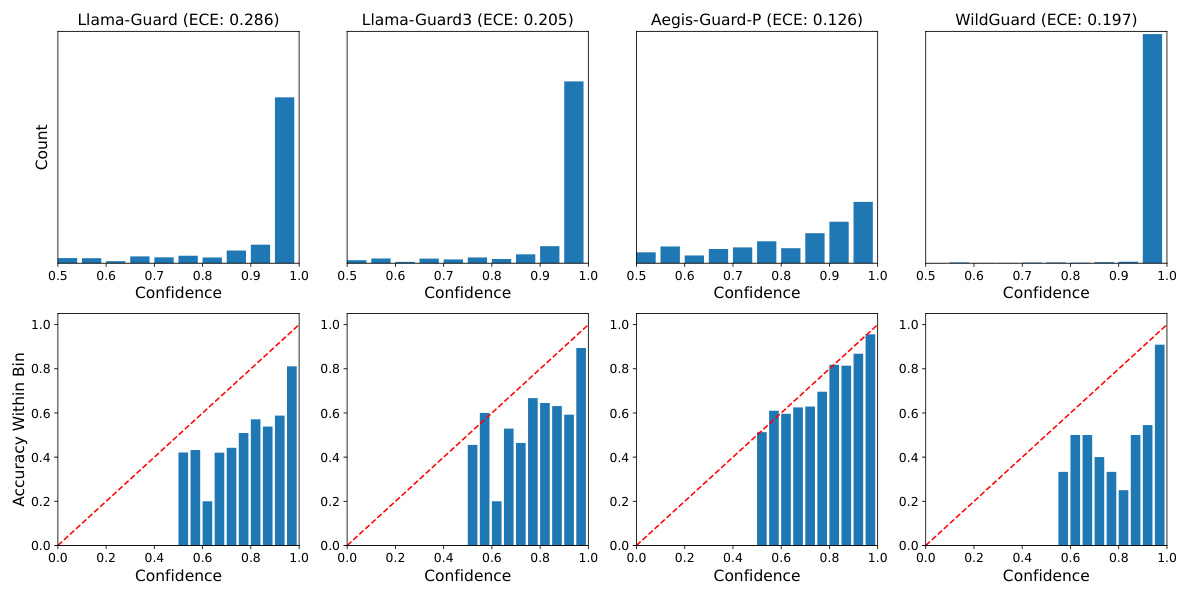
现有guard模型往往做出过于自信的预测。为了进一步调查,我们可视化了confidence分布,并在图2中呈现了对应的可靠性图,结果表明Llama-Guard、Llama-Guard3和WildGuard等模型的大多数预测的confidence介于90%到100%之间,这表明其过于自信的预测和高ECE。
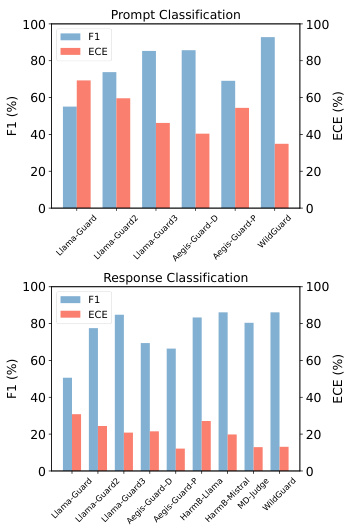
此外,在Harmbench Prompt数据集上处理有害请求时,guard模型的ECE表现出显著差异。在Harmbench-adv数据集上进行的评估表明,在对抗性环境中prompt分类的mis calibration问题比response分类更加明显。尽管WildGuard在prompt分类中取得了92.8%的F1得分的SOTA表现,但其ECE分数仍高达34.9%,这引发了关于其在实际部署中预测可靠性的担忧。
发现二
guard模型在不同response模型上进行分类时表现出不一致的可靠性。尽管在对抗环境下response分类的ECE相对较低,但仍需评估这些模型在处理不同response模型生成的输出时的一致性。以Harmbench-adv数据集为基础,本文将F1和ECE结果在表2中进行了汇报,结果显示F1和ECE在不同response模型中存在显著差异,这可能暗示着guard模型在训练时依赖于单一模型输出的限制。
| Response模型 | F1得分 | ECE |
|---|---|---|
| Baichuan2 | x% | y% |
| Qwen | x% | y% |
| Solar | x% | y% |
| Llama2 | x% | y% |
| Vicuna | x% | y% |
| Orca2 | x% | y% |
| Koala | x% | y% |
| OpenChat | x% | y% |
| Starling | x% | y% |
| Zephyr | x% | y% |
表2展示了不同response模型对应的F1和ECE性能,结果显示了guard模型在不同response模型时的性能波动。
提升LLM-based Guard模型的校准
本文针对当前LLM-based guard模型的mis calibration问题,探索了后期校准方法来提高模型的可靠性。具体的方法包括温度缩放、上下文校准和批量校准。实验结果显示,在prompt分类中,上下文校准表现更为有效,而温度缩放则提高了response分类的性能。
表3比较了不同校准技术的ECE表现。
本节详细说明了这三种校准方法的具体实现过程及其对guard模型的影响。
通过上述实验,研究揭示了LLM-based guard模型在面对不同数据集和任务时存在的校准问题,指向未来可能的改进方向。
结论
本研究系统性地评估了现有基于大型语言模型(LLM)的守卫模型在多个基准数据集上的不确定性可靠性与校准水平。尽管这些模型在内容监管领域展示了良好的性能,但研究发现它们存在过度自信预测的现象,且在对抗性环境下校准性能显著下降,对不同生成模型的输出缺乏鲁棒性。这些问题都表明了当前守卫模型在实际部署中的可靠性不足。
为了缓解误校准现象,研究探索了几种后处理校准技术。实验结果表明,情境校准在提示分类中尤为有效,而温度缩放则更能提升响应分类的性能。研究强调了不确定性基础的可靠性的重要性,并倡导在未来开发和发布新的基于LLM的守卫模型时纳入自信心校准评估。这些发现为改进内容监管模型的开发提供了宝贵的见解,同时也指引了未来在增强模型可靠性方面的研究方向。