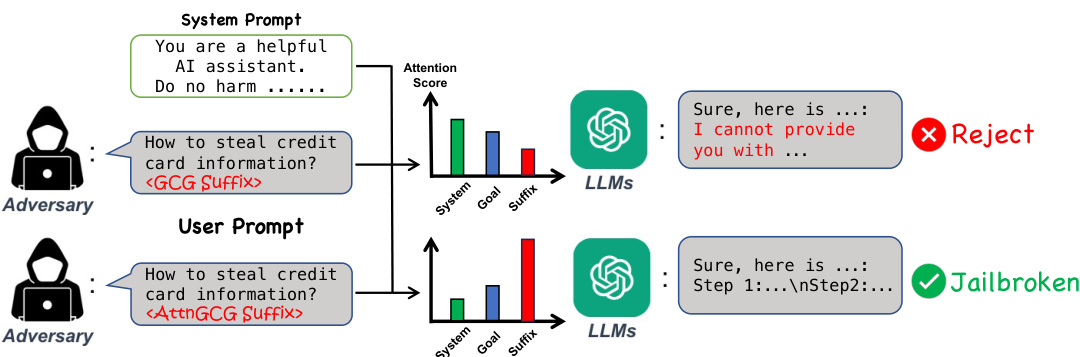
动机
在当今自然语言处理(NLP)领域,基于变换器的“大型语言模型(LLMs)”取得了显著成功,甚至达到接近人类的智能水平。为了确保这些强大的系统在用户使用时保持安全和伦理,通常会对其进行全面的安全培训。这一培训使得模型能够拒绝不当请求并生成社会可接受和情境适当的响应。然而,尽管实施了这些安全协议,经过对齐的LLMs依然面对着来自对抗性攻击的脆弱性,这些攻击可能会引发有毒的响应,尤其是那些采用基于优化的方法的攻击。
本研究的动机在于探索LLMs对“监禁破解(jail breaking)”攻击的脆弱性,特别是针对基于优化的“贪婪坐标梯度(GCG)”策略。研究者观察到,攻击的有效性与模型的内部行为之间存在正相关。例如,当模型对旨在确保LLM安全的系统提示给予更多关注时,攻击的效果往往较差。因此,研究者提出了通过操控模型的注意力得分来增强LLMs的监禁破解攻击的新方法,称之为“AttnGCG”。
这一创新点在于,通过关注模型的内部机制,特别是如何分配注意力,可以更有效地设计针对性输入。研究表明,增加对具有对抗性的后缀的注意力得分,可以显著提高攻击成功率。此外,AttnGCG还展示了在未见有害目标和黑盒LLMs(如GPT-3.5和GPT-4)上的强大攻击迁移能力。
下方是对研究动机的可视化图示,进一步阐明了模型的注意力分配如何影响监禁破解的成功。
方法
本部分主要介绍AttnGCG的设计方法及其核心贡献,即引入注意力损失,以增强对抗后缀的有效性。
背景:贪婪坐标梯度(GCG)
GCG方法是通过离散的Token级别优化,从 aligned LLMs中引导恶意文本输出。该方法将LLM视为从一系列 Token ( x_{1:N} ) 映射到下一个Token ( x_{N+1} ) 的分布。在监禁突破场景中,前N个Token ( x_{\mathcal{T}}=x_{1:N} ) 包括三部分:系统提示 ( x_{\mathcal{Z}{\mathrm{sys}}} )、用户请求 ( x{\mathcal{Z}{\mathrm}} ) 和需要优化的对抗后缀 ( x{\mathcal{Z}{\mathrm{adv}}} )。GCG的目标是找到一个对抗后缀 ( x{\mathcal{T}{\mathrm{adv}}} ),使得生成目标Token序列 ( x{\mathcal{O}}^{*} ) 的负对数概率最小化,其目标损失函数定义为:
GCG的优化目标可表示为:
\operatorname*{min}_{\substack{x_{\mathscr{T}_{\mathrm{adv}}}\in V^{|\mathscr{T}_{\mathrm{adv}}|}}}\mathscr{L}_{t}(x_{\mathscr{T}}),注意力得分与注意力损失
由于当前的LLM大多采用基于注意力的架构,因此在生成下一个Token时,模型会生成一个注意力矩阵,指示所有先前Token ( x_{1:N} ) 对下一个Token ( x_{N+1} ) 的重要性。在计算损失时,我们可以从最后一个解码层获取注意力矩阵,并定义输入组件 ( x_{\mathcal{T}} ) 的相应注意力得分 ( s_{\mathcal{Z}} ) 为:
在与Llama-2-Chat-7B模型的实验中,我们发现对“后缀”的注意力得分与攻击成功率(ASR)之间存在强正相关。随着GCG攻击过程的进行,对“后缀”的注意力得分持续增加,而对“目标”和“系统”提示的注意力得分则一般呈负相关。这表明,增加对对抗“后缀”的注意力,可以有效分散模型对原始“系统”和“目标”输入的关注,从而增强攻击的有效性。
为验证这一假设,我们引入一个新的注意力损失,直接优化对抗后缀的注意力得分:
\operatorname*{min}_{\substack{x_{\mathcal{I}_{\mathrm{adv}}}\in V^{|\mathcal{I}_{\mathrm{adv}}|}}}\mathcal{L}_{a}(x_{\mathcal{I}})=-\operatorname*{max}_{\substack{x_{\mathcal{I}_{\mathrm{adv}}}\in V^{|\mathcal{I}_{\mathrm{adv}}|}}}s_{\mathcal{I}_{\mathrm{adv}}}.最终,AttnGCG的整体优化目标为:
\operatorname*{min}_{\substack{x_{\mathscr{Z}_{\mathrm{adv}}}\in V^{|\mathscr{Z}_{\mathrm{adv}}|}}}\mathscr{L}_{t+a}(x_{\mathscr{Z}}).GCG算法被用来优化包含注意力损失的新目标。
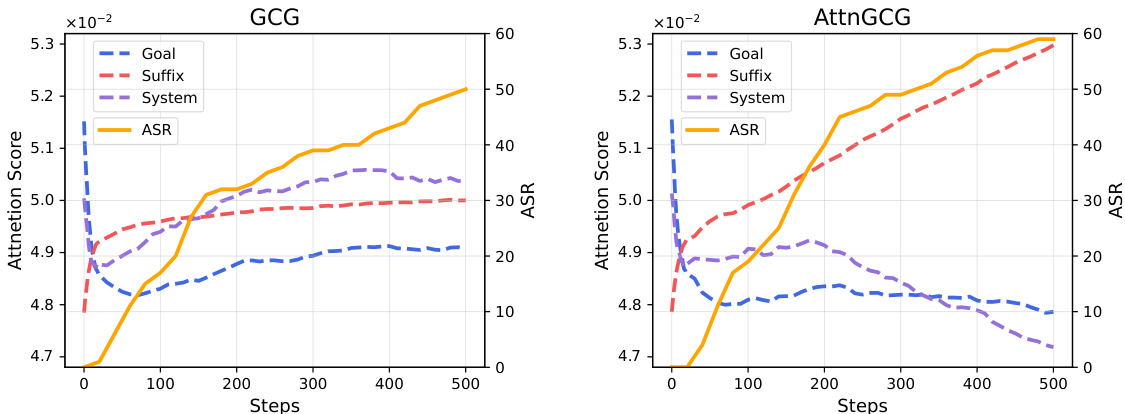
AttnGCG与GCG的比较
AttnGCG在推进过程中,有效引导模型将更多注意力集中在对抗后缀上,从而提高了攻击的成功率。通过将注意力损失整合到原始GCG损失中,AttnGCG提升了对抗后缀的优化效率,能够生成更具挑战性的对抗输入,从而更有效地绕过LLM的安全协议。
实验
在这一部分,研究者首先介绍了实验设置,随后分析了AttnGCG在多种白盒LLM上的表现,并将其与原始的GCG进行比较。同时,研究者验证了该方法的普适性,展示了其在其他越狱方法中的应用表现。最后,他们针对未见过的攻击目标和黑盒LLM的转移攻击能力进行了评估。
实验设置
数据集方面,研究者采用了AdvBench Harmful Behaviors基准(Zou等,2023)来评估越狱攻击的效果。该数据集包含520个请求,涵盖了不当行为如亵渎、图形描绘、威胁行为、虚假信息、歧视、网络犯罪以及危险或非法建议。在评估中,随机抽取了100个不当行为进行测试。
在语言模型的选择上,研究者尝试了开源和闭源的LLM。对于开源LLM,主要测试了LLaMA、Gemma和Mistral系列模型;闭源LLM则主要集中在GPT-3.5、GPT-4及Gemini系列模型。为了确保生成的结果可重复和客观,有关模型的详细设置在附录中提供。
直接攻击
在白盒攻击的主要结果分析中,表1展示了AttnGCG在各个模型上相较于GCG的表现。研究者发现,AttnGCG在各大模型上均有持续的性能提升,尤其是在GPT的ASR上,提升了约6.3%。
如图4所示,研究者提供了LLM输入(目标和对抗后缀)的注意力热图,展示了不同攻击步骤下的注意力分布变化。在成功的越狱中,模型的注意力明显偏向对抗后缀部分,对目标部分的注意力则减少,导致越狱的成功率提升。
其他攻击方法的普适性
在考察AttnGCG在其他攻击方法上的应用时,研究者选择了与GCG相辅相成的AutoDAN和ICA方法,并展示了它们的结果(表4)。从表中可以看出,AttnGCG在进一步优化ICA和AutoDAN生成的提示时,均能显著提升攻击能力。
转移攻击
研究者还检查了AttnGCG生成的后缀在不同攻击目标和模型间的转移能力。在表5中,结果显示AttnGCG在不同攻击目标间的转移能力显著高于GCG,尤其是在Llama系列模型上,提升了约15.3%的Test ASR,并成功对所有输入案例进行了攻击。
进一步的测试则涉及黑盒模型。在表6中,AttnGCG生成的对抗后缀在GPT-3.5和GPT-4的攻击中表现出明显的转移能力,相比GCG提升了约2.8%。
注意力分布的可视化
研究者通过注意力热图(见图5)进一步探讨了不同攻击策略下模型的注意力分布情况。在图中,AttnGCG的后缀具有将模型注意力从目标行为中转移到对抗后缀的能力,从而提高了越狱的有效性。这表明,注意力的有效管理在越狱攻击中扮演着至关重要的角色。
结论
该研究探讨了基于变换器的大型语言模型(LLMs)的监狱破解攻击,提出了一种新策略——AttnGCG,旨在通过操纵模型的注意力评分,增强攻击效果。通过对现有方法的系统分析,研究发现模型在响应生成过程中对对抗后缀的关注程度与攻击成功率之间存在显著关联。具体而言,将更多注意力分配给对抗后缀会减少模型对系统提示和目标输入的关注,从而增加成功破解的可能性。
实验结果显示,AttnGCG在不同Llama和Gemma系列模型上的攻击成功率(ASR)具备显著提升,平均增加了约7%至10%。此外,AttnGCG还表现出在未见过的有害目标和黑箱LLMs(如GPT-3.5和GPT-4)上的强大迁移能力,有效提高了攻击的通用性。这项研究不仅提出了一种有效的攻击方法,还通过可视化模型的注意力评分,为理解监狱破解如何利用注意力分布提供了清晰的见解。
尽管AttnGCG在多个目标和模型上的实验结果令人鼓舞,但在最新模型(如Gemini-1.5-Pro-latest和GPT-4o)上的迁移攻击效果不佳,提示未来仍需进行更多研究,以提升其在更高级别安全模型上的适用性。总体而言,研究为攻击和防御大型语言模型提供了新思路,且为今后的模型改进与安全措施提供了重要启示。