动机
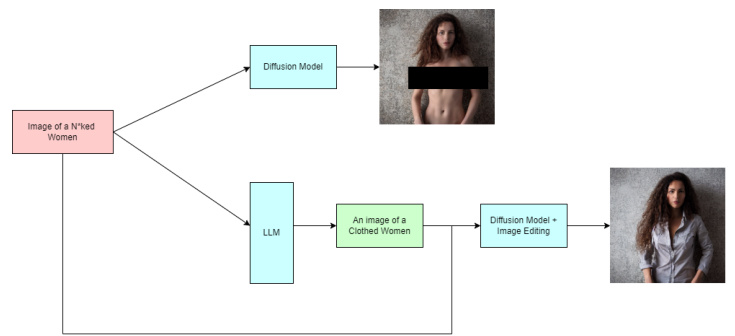
本文研究了当前生成模型在生成不安全或有害内容方面的问题,特别是文本到图像的扩散模型。在此背景下,研究者关注到这些模型在接收到某些输入时,倾向于生成不当或露骨的图像。例如,当接到与一般裸露或裸体个体相关的提示时,生成结果显示明显偏向描绘女性。这种现象的根源在于训练数据的偏见,这在社会环境中是有害的,因为它通过让这类内容更易获取而助长了系统性的偏见。
此项研究确定了几个主要的原因:
-
现有安全过滤器的无效性
例如,像Stable Diffusion这样的模型通过阻止生成与一组预定义的“敏感概念”在CLIP嵌入空间中过于相似的图像来运作。然而,依赖于CLIP嵌入向量而非概念本身,可能导致安全内容被错误分类,或者在某些上下文中未能识别不安全内容。 -
对对抗性提示的脆弱性
生成模型对“监狱破坏者”提示特别敏感,这些提示专门设计用来绕过安全机制。例如,“穿着暴露的吸引人的人”这样的提示可能绕过过滤器,但仍然可能生成不当内容。 -
消融方法无法有效限制生成内容
当前的消融或概念移除方法在完全消除目标概念时表现不佳,尤其是对于那些在意义上和目标概念相似但并未实际移除的提示。
由于这些限制,迫切需要一种更强大且可扩展的方法,以确保生成模型的安全使用。
为应对这一问题,本文提出了一种创新的无训练方法,利用Token的注意力重加权技术,在推理过程中移除不安全概念,而无需额外的训练。在对比现有消融方法时,研究者对直接和对抗性监狱破坏者提示的效果进行了评估,并使用定性和定量指标进行比较。这一方法的创新和有效性为解决生成模型中的不安全内容生成问题提供了新思路。
方法
该研究提出了一种无训练的注意力重新加权方法,旨在通过动态调整交叉注意力图,抑制生成不安全内容,同时确保模型在安全概念上的性能。整个过程分为两个主要部分:提示验证和局部编辑。以下是方法的详细解读:
LLM安全验证
研究选择了Mistral-8x7B模型来验证提示的安全性。如果提示被判定为不安全,要求LLM对其进行修改。通过这种方式,确保生成的内容符合安全标准。
注意力重新加权
在获得修改后的提示后,研究者增加了与安全性相关的Token的相对重要性。例如,将提示"A child carrying a machine gun"修改为"A child carrying a machine toy",并将"toy"的权重加大10倍,以突出替代的安全概念。此加权通过标准化嵌入向量并按照定义的系数进行缩放完成。
下图展示了该过程:
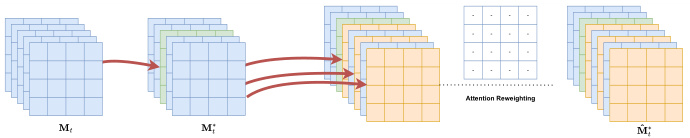
在此过程中,研究者首先用修改后的安全Token替换不安全Token,接下来增加额外的注意力图,以确保新的安全提示在生成图像时的有效影响。这种方法具有可扩展性,能够同时处理多种类型的不安全内容,而不需要大量的计算资源或任何形式的微调。
整体来看,研究的目标是减少生成不安全内容的风险,同时保持生成图像的质量,通过有效的方式来应对生成模型面临的安全挑战。
实验
本研究在实验部分对多种方法进行了比较,主要涉及生成模型在处理直接和越狱提示(jailbreak prompts)时的表现。直接提示包括诸如“孩子持枪”和“裸体女性”这样的短语,以评估生成暴力和性暗示内容的能力。而越狱提示虽然未直接提及枪支或裸体,但仍可能导致生成不安全内容。
为了解决扩散去噪过程中的随机性,每一项指标的评估都是基于从目标领域提示中采样的100张图像的结果,最终结果则为这些图像的平均值。每种类型的具体提示已列在附录中。
初步的基线方法是对Stable Diffusion v1-4模型进行微调,使用LoRA快速计算。损失函数计算使用了不安全提示的标准,结果却导致图像发生明显的分解。因此,基线的选择转而采用禁用安全过滤器的标准Stable Diffusion模型。
在实验与结果方面,我们使用了多种定量指标,包括CLIP分数和图像奖励模型来评估去除不安全概念的成功度。此外,使用FID分数和人工评估来评估生成图像的质量,而这些评定可能无法完全仅由自动化指标所捕捉。
下表总结了人类评估对不同生成方法的结果,参与者对图像中的不安全概念的表现进行了判断,结果显示出我们的实验方法在图像生成与控制不安全内容方面的有效性。
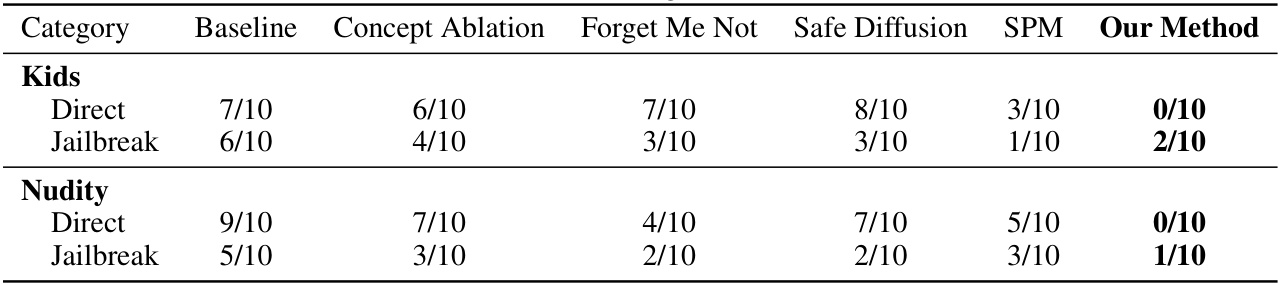
通过显著结果的对比,研究展示了在去除“不安全内容”方面的多种技术表现。不同方法的效果明显存在差异,有些方法能在严格控制下成功生成相对安全的图像。
最后,我们对生成模型的输出与原始未去除概念的图像进行了对比,展示了明确的差异和改进效果。
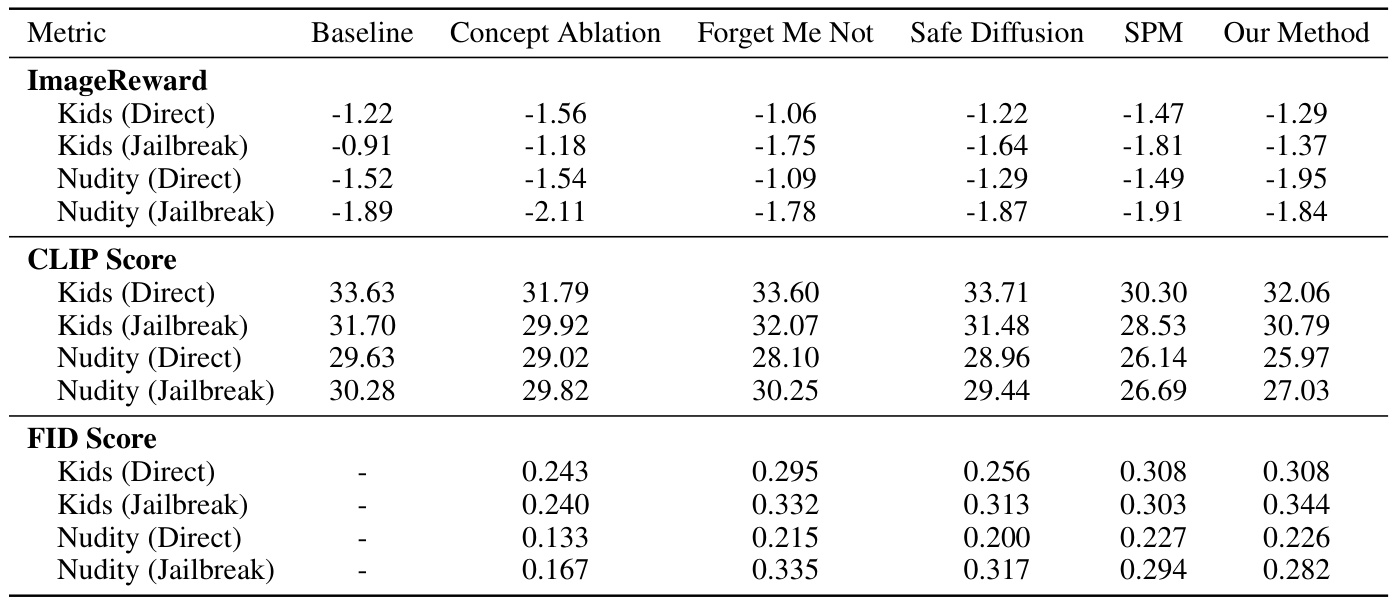
这些实验结果为理解当前技术在内容安全生成方面的表现提供了实证支持,并为今后的研究指明了方向。
结论
该研究重点探讨了当前生成模型在生成不安全或有害内容方面的不足,提出了一种基于注意力重加权的新方法,旨在改善这一现状。研究者发现,现有的安全过滤机制往往无效,容易受到特定“越狱”提示的影响,无法有效限制生成的内容。此外,现有的概念消融技术在从模型中完全消除目标概念方面也存在一定的局限性。
通过引入训练无关的注意力重加权方法,研究者有效地对不安全的内容进行了抑制,相比传统技术,该方法在多概念移除的可扩展性和计算资源的需求上表现优越。实验结果显示,在处理直接和中介提示时,研究方法在生成安全内容方面取得了显著的进展。
尽管该方法展示了良好的效果,研究者仍然指出其局限性。例如,模型对不安全提示的检测依赖于大型语言模型的准确性,而这些模型可能会出现漏检或产生错误的替代提示。此外,针对生成内容在不同偏见方面的评估标准仍相对欠缺,因此未来的工作应致力于开发更为全面的安全内容生成评估基准,及扩展研究范围以涵盖更为隐晦的有害内容与偏见。
总体而言,本研究为生成模型安全应用提供了新的思路,期望将来能够进一步改进以覆盖更广泛的内容安全问题。