动机
随着大型语言模型(LLMs)在代码生成和聊天助手等现实应用中越来越广泛地被使用,研究者们对这些模型的行为与人类价值观,尤其是安全性的一致性进行了深入的探索。然而,尽管已有诸多努力,LLMs在安全性方面仍面临显著挑战。特别是“越狱攻击”作为一种新兴的威胁,旨在诱使LLMs产出意想不到且不安全的响应,这表明现有的模型保护机制仍然不够稳固。
该研究的动机在于识别并解决这些漏洞,特别是针对越狱攻击的防御策略。研究者观察到,尽管代表有害内容的Token的概率往往高于代表无害响应的Token,但安全免责声明仍会出现在按概率降序排列的顶部Token中。因此,研究者提出了一种新颖的“安全解码”策略,通过增强安全免责声明的Token概率,同时减弱与攻击者目标的Token序列概率,从而有效防止模型被非法利用。
这一研究的创新点在于通过Token概率的分布来分析越狱攻击的成功机制,显示出越狱攻击的成功往往归因于与攻击目标相一致的Token的概率占主导地位。而通过引入一个专家模型并进行安全性强健的微调,作者们进一步提出了通过“安全解码”策略,在不同层面上抵御越狱攻击。
下图展示了Token概率在越狱攻击期间的分布情况:

方法
在这一部分中,作者提出了一种名为Safe Decoding的安全感知解码策略,以增强大型语言模型(LLMs)抵抗jailbreak攻击的能力。该策略的设计分为两个阶段:训练阶段和推理阶段。
训练阶段:构建专家模型
为了构建一个具备较强安全性的专家模型,研究者首先收集了涵盖18个有害类别的36个有害查询。这些查询应该被任何与人类价值观良好对齐的LLM所拒绝。通过自主生成回应后,使用GPT-4过滤输出,仅保留那些有效拒绝有害查询的响应,最后形成训练数据集,包括查询与响应对。
专家模型通过参数高效微调(例如使用LoRA方法)进行训练,确保微调模型的词汇与原始模型一致,同时能够识别和适当地回应恶意用户输入。
推理阶段:构建新的Token分布
在推理阶段,用户查询被同时发送给原始模型和专家模型以进行解码。Safe Decoding根据两个模型的输出构建Token分布,从而生成对输入查询的响应。
步骤1:构造样本空间
在推理时间的第n步,模型将Token序列转发给原始模型及专家模型,得到可能采样的Token集合分别为 和 。Safe Decoding将样本空间 定义为两者前k个Token的交集,即:
该交集的构建旨在利用原始LLM的广泛训练和专家模型在安全性上的强化。
步骤2:定义概率函数
Safe Decoding在定义Token概率时,使用以下公式:
此公式中, 为超参数,决定原始模型与专家模型的重要性权重。最终通过标准化,确保。这使得当查询是恶意的时,原始模型会给出积极的回应,而专家模型则会基于安全性拒绝查询,从而减少引导攻击者目标的Token的概率,并增强机器人对于人类价值的响应。
效率与兼容性
Safe Decoding的设计兼容现有的所有采样方法,包括greedy、top-k和top-p采样。通过在推理过程中仅在前m步应用Safe Decoding,且后续步骤使用正常解码,可以避免模型过于保守,从而保持对良性用户查询的有用性,并降低计算开销。
实验
本文对 Safe Decoding 的有效性、实用性、效率和兼容性进行了评估。
首先,针对实验模型,研究者们在五种开源 LLM(Vicuna-7b、Llama2-7b-chat、Guanaco-7b、Falcon-7b 和 Dolphin-llama2-7b)上部署了 Safe Decoding,以评估其性能。
在攻击方法方面,研究者们考虑了六种先进的 jailbreak 攻击,涵盖不同类别,包括 GCG、AutoDAN、PAIR 和 SAP30 等。这些攻击方法通过使用来自不同 harmful query benchmark 数据集的示例来生成特定的攻击提示,以评估 Safe Decoding 的防御性能。使用的两个有害查询基准数据集为 Advbench 和 HEx-PHI。
在基准测试方面,研究者们与六种最新且高效的防御机制进行了比较,涵盖输入和输出检测以及缓解方法。研究过程中使用的评估指标包括攻击成功率(ASR)和 harmful score,前者用于衡量模型在恶意查询下产生不符合人类价值的响应的比率,而后者则通过 GPT-Judge 对生成内容的危害程度进行评分。通过 Dic-Judge,研究者们还检测了生成响应中拒绝字符串的存在,以计算 ASR。
下表展示了 Safe Decoding 与基线防御方法在多个 jailbreak 攻击下的 ASR 和 harmful score 的比较:
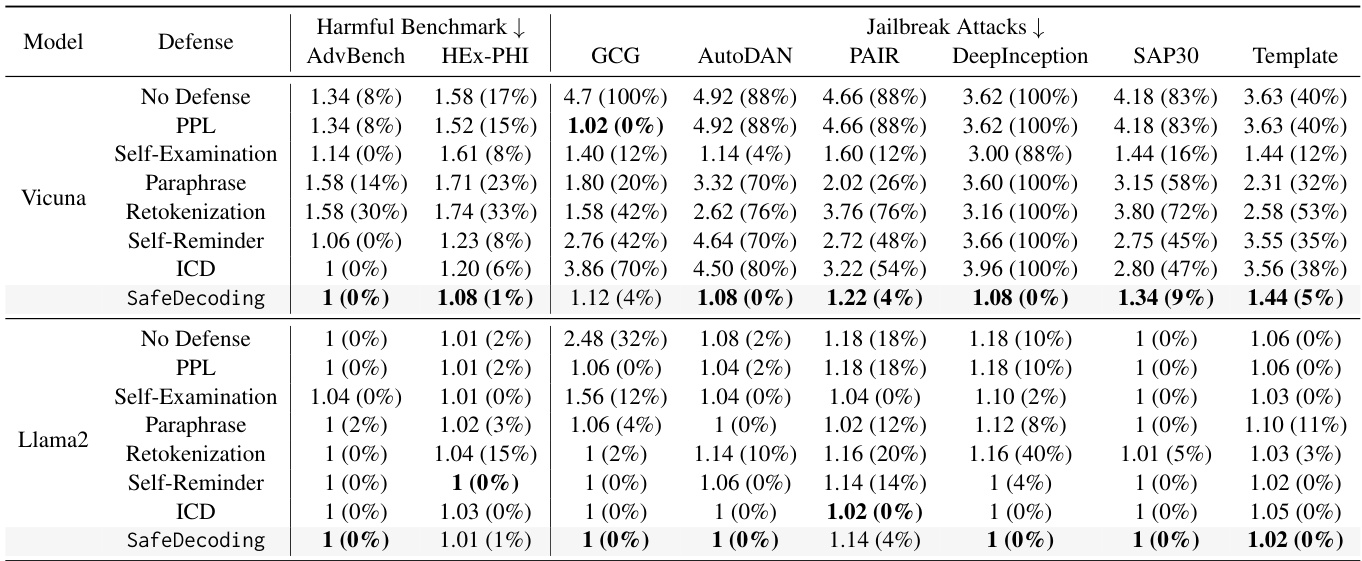
表中显示了在不同攻击方法下,Safe Decoding 的表现普遍优于所有基线防御方法。在针对意图重大的攻击(如 Deep Inception)时,Safe Decoding 成功将 ASR 降至 0%。
为了进一步评估 Safe Decoding 的实用性,研究者们使用了 MT-bench 和 Just-Eval 等广泛使用的基准测试,评估应用 Safe Decoding 后的 LLM 实用性。以下表格展示了 Safe Decoding 在不同模型上的 MT-bench 和 Just-Eval 得分:
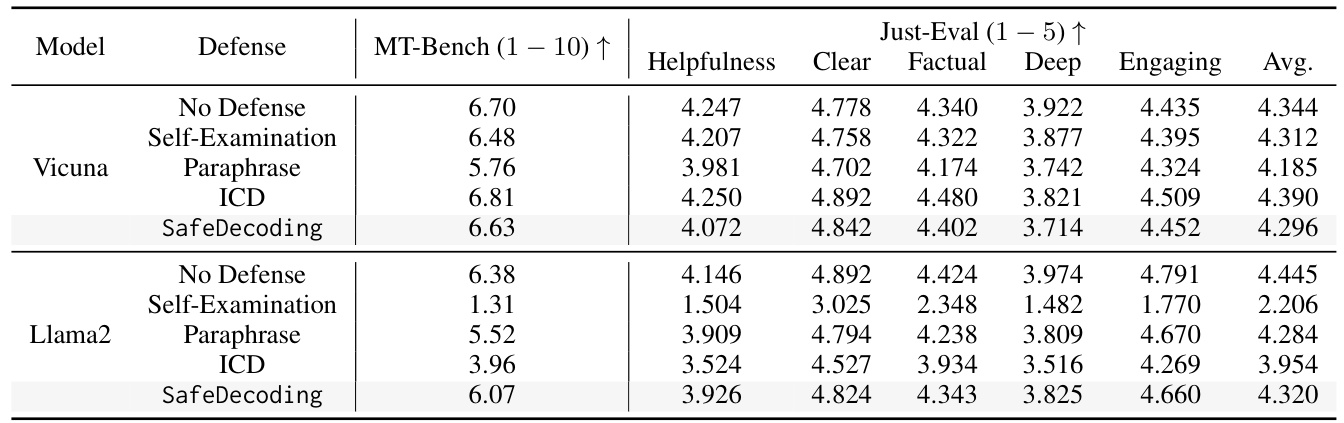
根据表格结果,Safe Decoding 对原始模型的效用影响微乎其微,而现有基线模型在效用上则显著下降。
接下来,研究者们定义了一个平均生成时间比率(ATGR)指标,以评估 Safe Decoding 的效率:
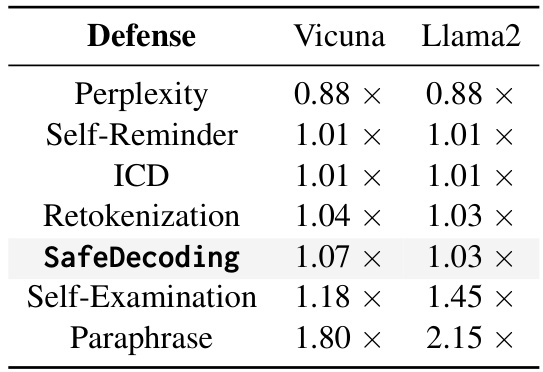
结果显示,相较于无防御的情况下,Safe Decoding 的计算开销仅为 3%(在 Llama2 上)和 7%(在 Vicuna 上),表明该方法的效率并未显著降低性能。
附加的消融分析表明,Safe Decoding 的超参数(如 、、)对防御性能影响有限,如下图所示:
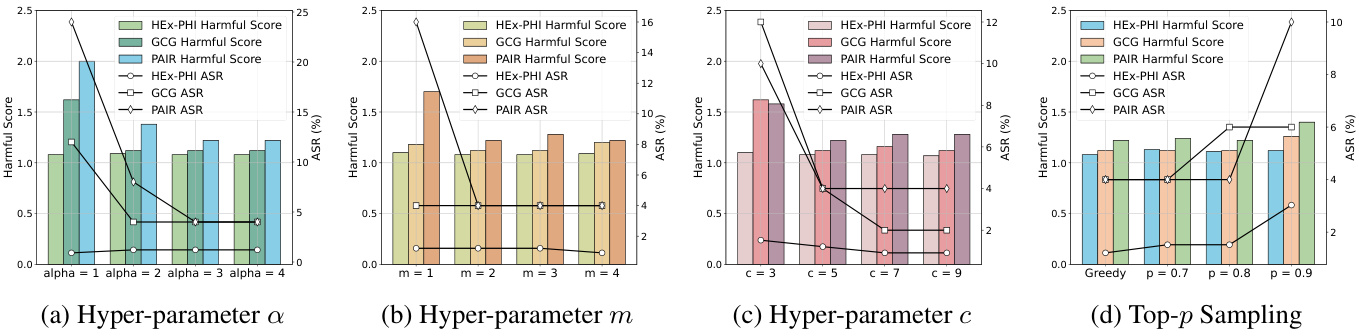
通过以上实验,Safe Decoding 在针对 jailbreak 攻击方面展示了强大的防御能力、良好的实用性和效率。
结论
在这篇论文中,研究者们提出了一种新颖且计算有效的解码策略——Safe Decoding,以应对大型语言模型(LLM)面临的监狱突破攻击(jailbreak attacks)。他们的主要观察是,尽管包含有害内容的Token的概率通常高于那些与安全或人类价值相符的Token,但安全免责声明在排序后的概率前列中依然存在。这一发现为Safe Decoding的设计提供了基础,使其能够降低与攻击者目标一致的Token的生成概率,同时提高安全性相关的Token的生成概率。
通过实验,研究者们验证了Safe Decoding在多种大型语言模型上的有效性和效率,结果表明该方法在抵御多种流行的监狱突破攻击方面显著降低了攻击成功率和有害性。同时,该方法在处理正常查询时并未妨碍模型的有用性,表明其在实际应用中的潜力和合适性。
最终,论文强调了Safe Decoding在保持系统性能的同时提高安全性的能力,表明它在未来的研究和实际应用中具有重要的价值和应用前景。尽管存在某些局限性,如在某些情况下初始拒绝有害查询后可能会同意,该策略仍然展现出在当前安全环境中保护用户和系统的重要性。