动机
随着自然语言成为人与人工智能系统交互的默认接口,无论是在信息搜索、摘要生成还是图像描述中,都需要语言模型(LM)适当地传达其不确定性。在此背景下,研究者们对语言模型如何通过自然语言来表达信心以及用户如何响应LM所表达的不确定性进行了深入探讨。
研究显示,当前公开部署的语言模型在回答问题时对表达不确定性表现得十分犹豫,即使在生成的答案不正确时也不例外。虽然可以通过明确提示使语言模型表达信心,但即使在这些情况下,模型往往仍显得过于自信,导致其高置信度回答的错误率高达47%。因此,这些模型在表达不确定性时不仅缺乏适当性,还可能对用户决策造成潜在的风险。
该研究还展示了用户在面对LM生成的表达时(无论是标记为确定性还是不确定性的表达)仍高度依赖于语言模型的生成结果。此外,研究指出,对后期训练对齐所用偏好标注数据集的分析,揭示了人类对不确定性文本的偏见。研究者们强调,这一现象不仅突显了在人机交互中存在的新安全隐患,同时也提出了设计建议和减轻潜在问题的策略,从而为未来的研究和实践提供了新的起点。

方法
本研究的目标是评估广泛使用的公开部署模型(如GPT、LLaMA-2、Claude)在生成表达不确定性时的潜在危害和安全风险。为此,研究者使用了多种方法来探讨语言模型(LM)如何运用表述不确定性的语言标记。
数据集与问题选择
研究人员从大规模的多任务语言理解基准(MMLU)中选取了多种问题。MMLU是一个涵盖57个主题的四项选择数据集,旨在评估语言模型的知识和问题解决能力。选定的问题内容统一限制为国家首都相关的难题,以确保用户对AI生成的不确定性标记的评估主要源于LM的生成,而不是用户自身的先验知识。
提示设计
研究人员设计了三种类型的开放式提示指令,以系统性地引导LM生成不确定性的表达:
- EpiM:请回答问题并提供你的确定程度。
- CoT(链式推理):逐步解释你的思考过程。
- Epi_{M+CoT}:使用不确定性的表达,逐步解释你的思考过程。
通过对这些指令的设计,研究人员旨在促进模型生成的不确定性标记,模拟真实用户可能与LM的互动方式。
生成与分类不确定性标记
研究团队首先实施开放式生成,与以往研究中要求模型生成预定义的确定性表达方式不同。此方法允许研究者进行自下而上的定性分析,以理解LM如何生成不确定性标记。生成的回应通过正则表达式模式匹配进行分类,识别为“增强型”(表示确定性)和“减弱型”(表示不确定性)。这些生成的标记经过手动编码和定量分析以确认其准确性。
实验设计
研究人员使用了九种模型,包括不同版本的GPT、LLaMA-2和Claude,每种模型使用49个提示共发出了125,244个查询。为了评估生成的表达类型,研究者对每一条生成的表达都进行了详细的定性编码,最终形成了76种增强型和105种减弱型表达,见表7和表8。
通过系统的提示设计及分类方法,研究者能够深入理解LM在生成表达不确定性时的表现,及其在实际使用中的潜在影响和风险。
实验
在此部分,研究人员设立了一系列实验来调查语言模型(LM)如何表达不确定性,以及用户如何对LM生成的表达的不确定性做出反应。
设置1:控制设置
研究人员创建了一项任务,以评估用户在没有查看实际答案时对LM生成的不确定性标记的依赖。参与者需要回答一系列国家首都的问答,且每个问题的开头都包含来自LM的表达。例如,Marvin的回答可能是“我认为……”。参与者只能根据这些不确定性标记作出依赖或查找答案的决定。
设置2:互动设置
互动设置由多个回合构成,参与者必须在每一轮中做出决策并接受反馈。每个回合的步骤如下:
- 显示问题;
- 显示Marvin的预测响应,其中包括不确定性的标记;
- 参与者根据这些标记作出决定;
- 提供决策反馈。
这种设置允许研究人员观察用户如何依赖LM提供的反馈和不确定性表达。
设置2A:校准设置
在校准设置中,Marvin的回答根据用户在控制设置中的预期解读进行校准,即“加强语”与正确答案同时出现,“减弱语”与错误答案同时出现。参与者在最初的20轮中依赖“加强语”的比例为94%,而对“减弱语”的依赖仅为7%。经过20轮,参与者能够近乎完美地利用Marvin的不确定性标记,达到99%的准确率。
设置2B:过度自信设置
在过度自信设置的前20轮中,Marvin生成的错误答案使用“加强语”。参与者依赖“加强语”的频率达到了81%,而这些表达的正确率仅为66%。由于参与者通常不知道答案,结果表明他们误信了这些错误且自信的生成,约73%的时间误赖于错误的、充满自信的生成。即使在经过校准的回合中,这种不良影响依旧存在。
设置2C:缺乏自信设置
在缺乏自信的设置中,Marvin在生成正确答案时使用“减弱语”。尽管初始的错误回合表现不佳(平均66%),但在经过后续的校准设置后,参与者的表现回升至与校准设置相当的98%。相比之下,在过度自信设置中,用户的心理模型始终未能完全修正。
实验结果
实验结果显示,用户对“加强语”和纯粹陈述的依赖程度极高,几乎达到90%。即便在“减弱语”出现的情况下,用户依然倾向于查找答案,呈现出显著的依赖倾向。
图表与数据
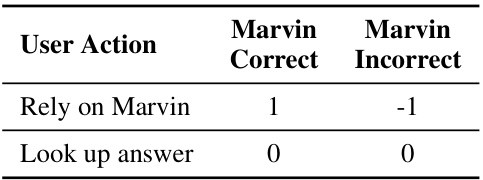
表2:人类实验中的计分表。依赖Marvin的生成并且Marvin正确时将得分1分,否则扣分-1分。查找答案不记分。
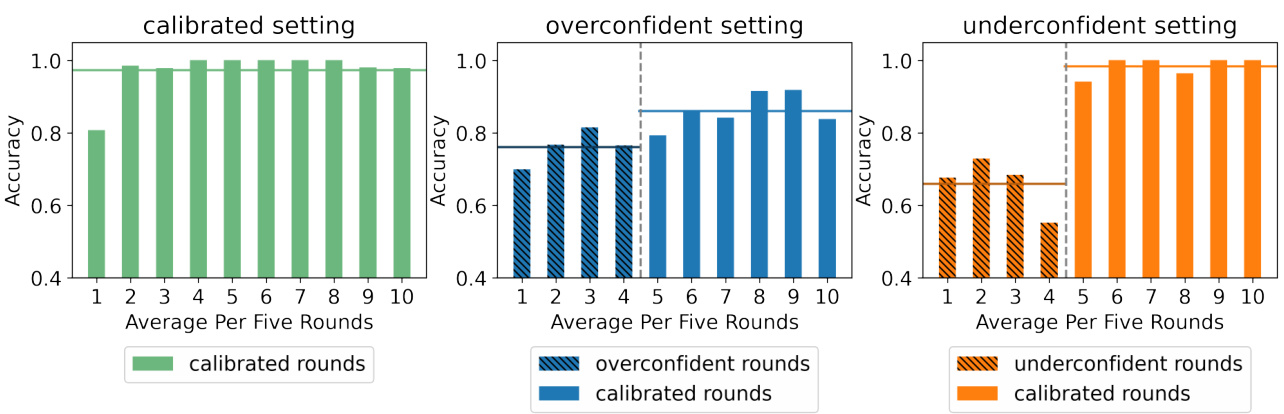
图5:参与者在校准、过度自信和缺乏自信设置中的结果。可以看到,在错误校准回合中得分较低。过度自信设置在随后校准回合中也持续得分较低。
结论
研究表明,语言模型在生成内容时表现出过于自信,这种现象加剧了用户在面对错误或不确定答案时的依赖性。尽管用户在模型生成的内容中通常依赖于隐含或显式的信心表达,研究追溯了模型过度自信的根源,发现这种现象主要源于后期训练对齐过程中的人类反馈偏差,具体来说,注释者对不确定性语言的偏见。
在与语言模型的互动中,用户可能会错误地将缺乏不确定性表达解读为高信心,这种情况不仅使得模型的错误回答看起来更加可信,也可能进一步影响用户的决策过程。研究建议,应该对模型的训练过程进行改进,增加不确定性表达的自发生成,确保用户能够准确理解模型的信心程度,从而降低过度依赖的风险。
此外,研究还指出,需要对多样化数据源进行探索,以拓宽模型对各种不确定性标记的理解,并应根据不同的上下文进行相应的模型校准。总的来说,语言模型当前在表达信心和不确定性方面的不足,可能对人类-人工智能协作造成严重后果,从而亟需寻找有效的设计和改进方案,以促进更可靠的交互。