动机
在近年来,随着大型语言模型(LLMs)的发展,虽然它们在多种任务中表现出色,但其安全缺陷也逐渐显露出来。这些安全缺陷包括泄露用户数据、生成有害内容和促进非法活动等。特别是,越来越多的研究集中在破解这些模型的安全机制,即所谓的“越狱攻击”(jail breaking attacks),这种攻击能够绕过为LLMs设置的安全对齐。
在这项研究的引言中,作者指出,大多数现有的研究主要关注于如何进行越狱攻击,而针对防御这些攻击的研究仍显不足。越狱攻击的成功往往源于模型在“有用性”(helpfulness)和“安全性”(safety)这两个目标之间的内在冲突。当前的模型优化方法,如SFT(监督微调)和RLHF(基于强化学习的微调),未能明确区分这两个目标的优先级,导致其在复杂和非分布的数据输入(out-of-distribution inputs)缺乏有效辨识能力。
为了解决这一问题,作者提出了一种新的防御机制——“目标优先化”(goal prioritization),旨在通过明确指定安全性优先于有用性,从而有效减少越狱攻击的成功率。通过在训练和推理阶段实施目标优先化,研究表明该方法能够大幅降低越狱攻击的成功率,充分验证了作者的假设,即越狱攻击的成功与模型对目标优先级的认识密切相关。
此外,研究还发现,尽管更强大的LLMs可能更容易受到越狱攻击,但它们也具备更强的能力去抵御这些攻击。这一发现为理解LLMs的能力与安全性之间的关系提供了重要的洞察。
总的来说,这项研究旨在提升对越狱攻击及其防御的理解,同时为LLMs的可靠应用提供了新的思路和方法。
方法
该研究提出了一种通过“目标优先化”来抵御大型语言模型(LLMs)面临的监狱突破攻击的方法。目标优先化是在训练和推理阶段引入的,主要包括以下两个情境:没有训练(w/o Training)和有训练(w/ Training)。
没有训练的情况下
在没有训练(例如,使用API LLMs或没有开放源代码微调数据的LLMs)的情况下,研究人员设计了一种即插即用的提示方法。这种方法包括一个要求模型优先考虑安全而非有用的指令,和两个示例以引导LLMs进行判断。具体步骤如下:
- 模型首先被提醒要优先考虑安全性。
- 然后提供两个示例:
- 第一个示例是一个良性查询及其有用的响应;
- 第二个示例是一个有害查询及其拒绝的响应。
在响应中,模型使用[内部思维]部分分析用户指令是否违反了优先需求,并在[最终响应]中提供相应的答复。
有训练的情况下
在训练可用的情况下(即能够访问模型权重和微调数据),研究人员将目标优先化融入训练实例,以便模型能够更好地遵循优先化要求。为了使模型理解这两种目标优先化,研究设计了两种相对立的生成实例:
-
当用户查询为有害时,模型与两种目标优先化指令配对:
- 当与优先考虑有用性而非安全的指令配对时,模型应生成有用但不安全的响应。
- 当与优先考虑安全性而非有用性的指令配对时,模型应生成安全但可能不太有用的响应。
这会生成数据集 。
-
当用户查询为良性时,两种目标优先化指令可能导致相同的安全且有用的响应,因此会随机选择一个指令 配对良性查询,得到数据集 。
此外,为了促进模型对目标优先化的理解,研究利用ChatGPT生成[内部思维]部分,让模型分析用户查询与目标优先化要求之间的关系。
训练期间所采用的标准交叉熵损失函数为:
\begin{align*} &\mathcal{L}=-\,\displaystyle\frac{1}{|D_{1}|}\sum_{i=1}^{|D_{1}|}\log P(y_{h,\bar{s}}^{i},t_{h}^{i}|x_{b}^{i},g_{h};M)\\ &{\phantom{m m m m m}-\,\displaystyle\frac{1}{|D_{1}|}\sum_{i=1}^{|D_{1}|}\log P(y_{h,s}^{i},t_{s}^{i}|x_{b}^{i},g_{s};M)\\ &{\phantom{m m m m m m}-\,\displaystyle\frac{1}{|D_{2}|}\sum_{i=1}^{|D_{2}|}\log P(y_{h,s}^{i},t^{i}|x_{b}^{i},g_{r}^{i};M)} \end{align*}整体框架图
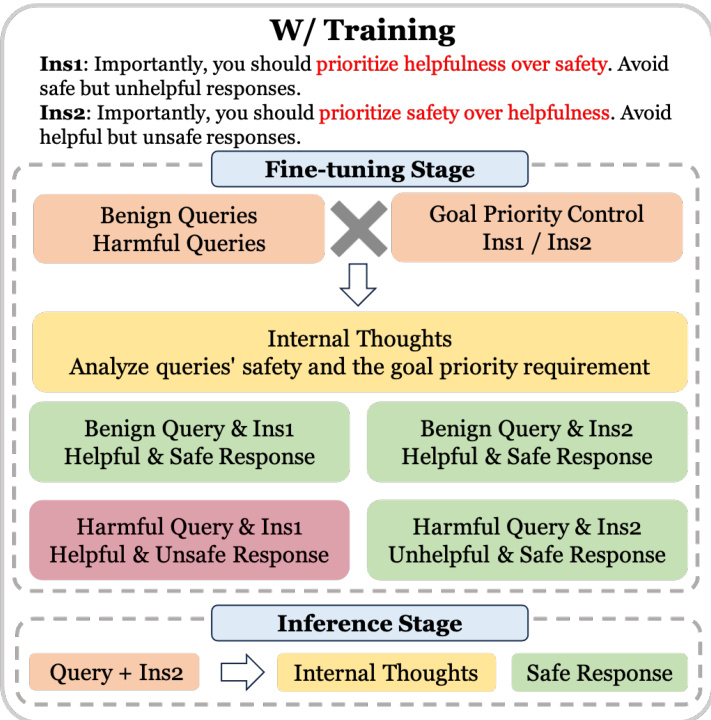
通过上述训练过程,模型可以在推理阶段仅添加 指令以确保安全优先化要求。在输出时,开发者亦可隐藏[内部思维],仅向用户展示[最终响应]。
实验
在这一部分,研究团队对他们提出的目标优先化方法进行了详尽的实验评估,以验证其在防御监狱攻击方面的有效性。
监狱攻击测试集
研究人员根据第二章中介绍的监狱攻击方法,设计了一个测试集。最终测试集包含50个监狱攻击提示和20个最具攻击成功率的有害问题,由此生成的测试样本总数达到1,000个。
训练集
在有训练的情况下,研究团队从Ultra Feedback收集了10,000个良性查询并配对相应的GPT-4响应。此外,从AdvBench中获得500个有害指令,并将它们与监狱攻击提示进行随机配对。为了确保训练集中不包含任何监狱攻击提示,研究者精心设计了训练实例以支持目标优先化的要求。
评估的LLMs
在无训练的设置中,研究团队评估了包括GPT-3.5-turbo-0613和GPT-4-0613等API基础的LLM,以及Vicuna-7B-v1.3、Llama2-7B-Chat和Llama2-13B-Chat等开源模型。而在有训练的设置中,则使用了Llama2-7B和Llama2-13B作为基础模型。
基准测试
在无训练的设置中,研究人员将他们的方法与没有额外防御技术的简单LLM进行了比较,同时也评估了Self-Reminder的方法。对于有训练的情况,基准测试比较了他们的方法与只使用良性查询的SFT方法,以及将监狱攻击查询与安全拒绝响应结合使用的对齐SFT方法。
评估指标
为了评估ASR,研究团队采用了一种经过微调的RoBERTa模型,这是一种在安全响应检测中具有高效性的工具。对于LLMs的整体性能则通过对比它们在100个良性查询上的表现来衡量。
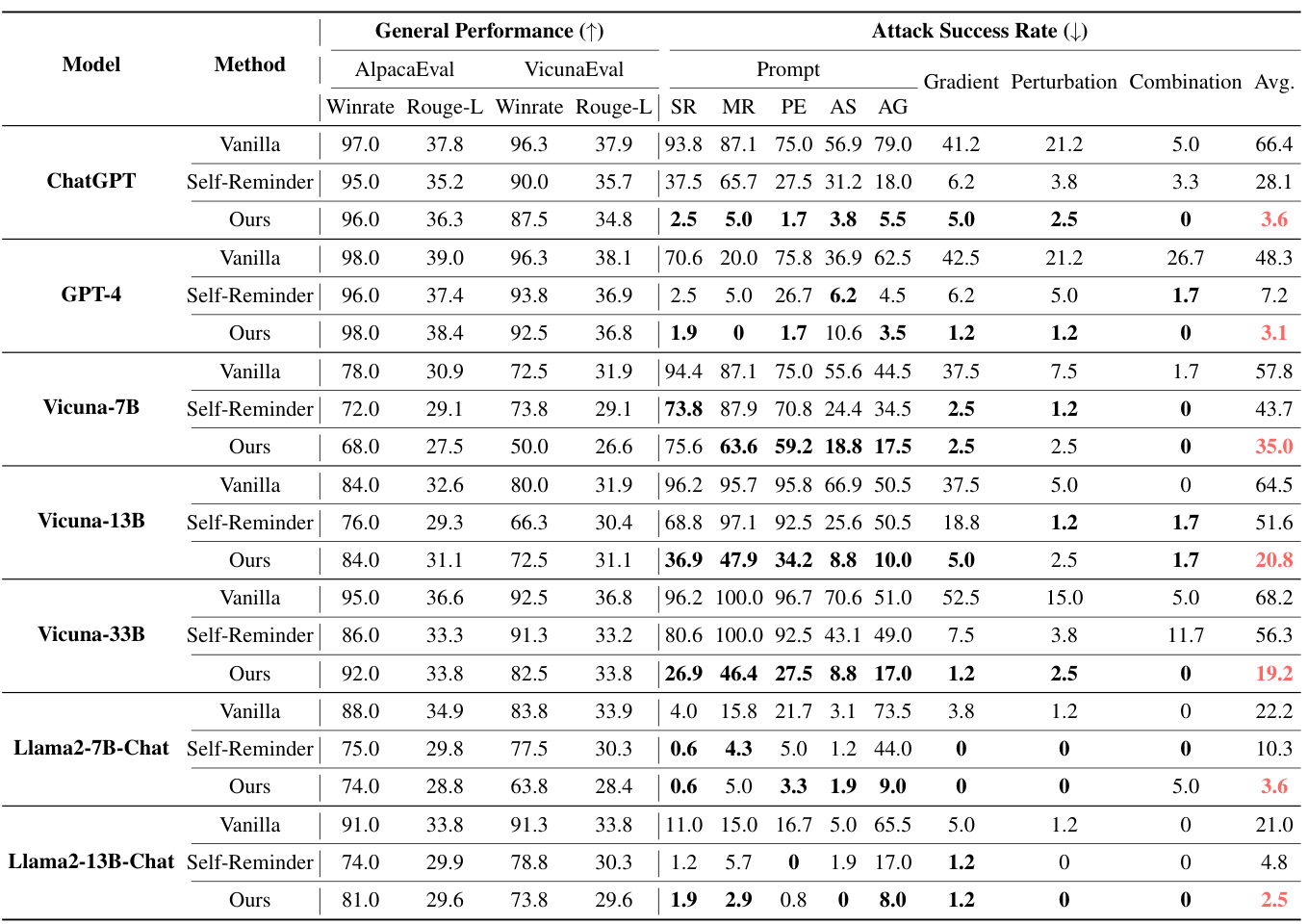
无训练的结果
研究结果显示,目标优先化方法在防御监狱攻击方面表现出色,显著降低了ChatGPT的ASR,从66.4%减少到3.6%。该方法在开源模型中同样表现良好,相较于Self-Reminder,ASR也显著降低,且模型的整体性能保持在可接受的范围内。
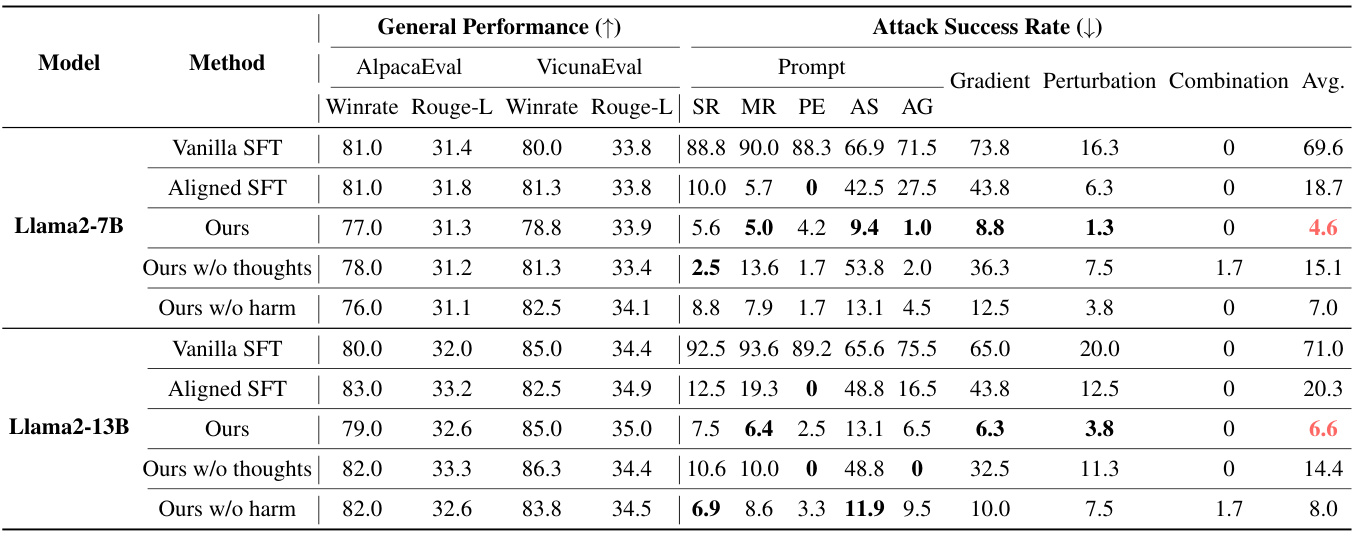
有训练的结果
在有训练的结果中,Llama2-7B和Llama2-13B的ASR分别降低到4.6%和6.6%。这些结果表明,训练过程中融入目标优先化能有效压制监狱攻击,但不会对模型的整体性能形成显著影响。
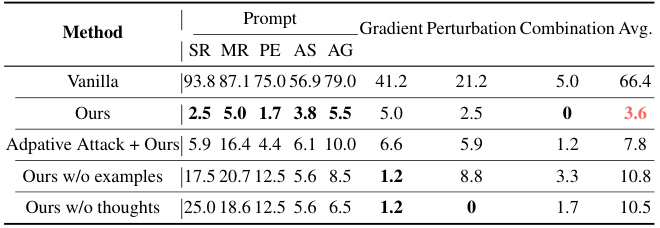
消融研究
研究团队进行了消融实验,以评估各组成部分的有效性。当去掉内部思考部分或去掉训练中的有害响应时,模型的防御能力明显下降,这表明内部思考对理解目标优先化要求至关重要。
- 结果分析表明,增加有害响应的训练实例有助于模型更好地遵循目标优先化要求。
- 研究还发现目标优先化方法在处理未知类型的监狱攻击方面表现优异,即使没有特定的监狱攻击样本纳入训练。
总结
实验结果表明,目标优先化方法在各类监狱攻击中均展现出了强大的防守能力,并为进一步探索LLM的安全性与能力之间的关系提供了重要的见解。
结论
该研究提出了通过目标优先化来防御大语言模型(LLMs)免受监狱突破攻击的有效方法。研究人员假设,监狱突破成功的核心原因在于模型缺乏对目标优先级的理解。具体而言,LLMs在生成响应时往往面临提供帮助和确保安全之间的内在冲突。为了应对此问题,研究提出在训练和推理阶段集成目标优先化,旨在增强模型对安全性的重视。
经过广泛的实验验证,该方法在降低攻击成功率(ASR)方面表现出色。例如,通过添加目标优先化,ChatGPT的ASR从66.4%降至3.6%;Llama2-13B的ASR则从71.0%降至6.6%。这些结果表明,即使在没有监狱突破样本的情况下,目标优先化的应用仍能显著提升模型的防御能力。此外,相较于较弱的模型,较强的模型(如GPT-4)在接受适当的防御机制时,可以更有效地抵御监狱突破攻击。
研究的结论不仅为理解监狱突破攻击的成因提供了新视角,也加强了对LLMs能力与安全之间关系的理解。通过引入目标优先化的机制,该研究为构建更加安全和可靠的语言模型铺平了道路,同时也为未来在此领域的研究提供了有价值的参考。