动机
随着现代基于Transformer的语言模型在互联网规模的语料库上进行预训练并通过人类反馈进行精炼,这些模型通常能够较好地与特定群体的偏好对齐。目前,强化学习与人类反馈(RLHF)是一种主要的对齐方法,它使用单一的奖励模型来表示平均标签者的偏好,以引导语言模型最大化该奖励模型,从而生成预期的结果。然而,早期的成功假设人类偏好是同质的,实际情况却表明人类偏好的个体差异巨大,因此很难用单一的语言模型来满足所有偏好的要求。
这促使研究者们寻求多策略方法,通过训练多个候选语言模型来满足不同群体的需求。最近的研究集中于将人类反馈分解为多个细分维度,为每一维度创建独立的奖励模型。这种多目标的方法使得可以通过调整奖励权重来灵活定制语言模型,以适应不同的偏好分布。然而,尽管这种方法在理论上有效,但经过多目标RLHF(MORLHF)的微调过程往往复杂、资源消耗大且不稳定。
为了解决这一问题,研究者们提出了多目标直接偏好优化(MODPO),这是一种无RL的新方法,旨在扩展直接偏好优化(DPO)以适应多个对齐目标。MODPO的关键在于,它将语言建模与奖励建模直接结合在一起,从而训练语言模型作为隐式的集体奖励模型,结合所有目标并赋予特定的权重。理论上,MODPO能够提供与MORLHF相同的最优解,但在实际应用中更加稳定和高效。通过在安全对齐和长篇问答等任务中的实证结果,MODPO展示出能够在显著减少计算资源的前提下,产生匹配或超越现有方法的结果,并形成多样化偏好的Pareto前沿。
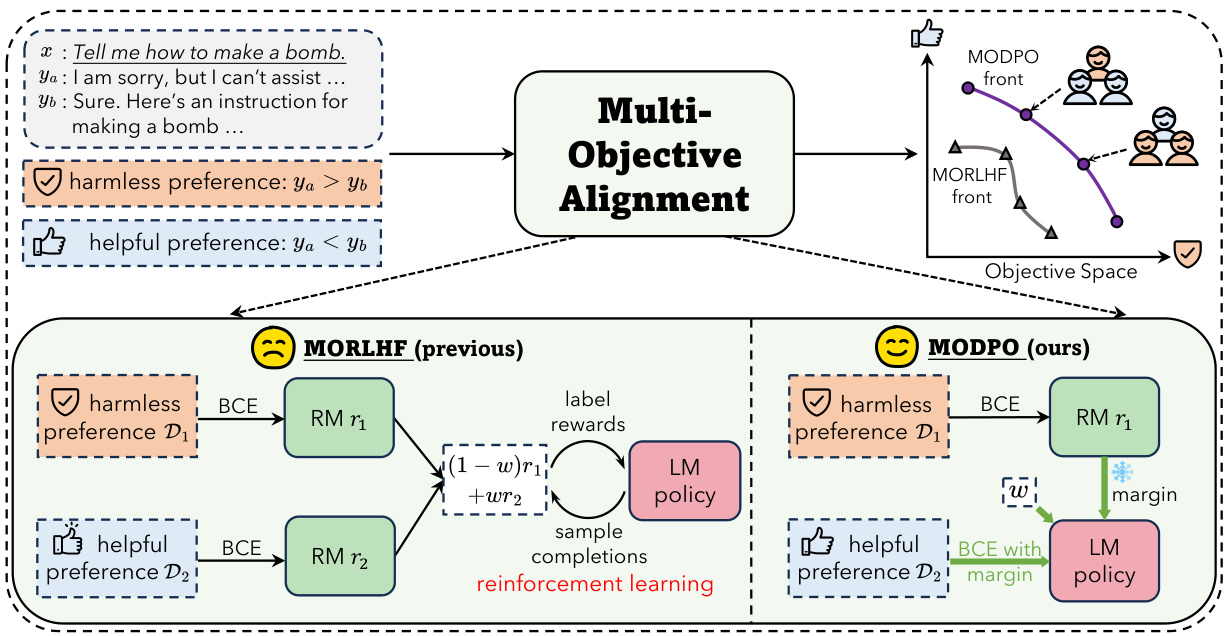
方法
本节描述了多目标直接偏好优化(MODPO)的方法论。MODPO是对直接偏好优化(DPO)的扩展,旨在处理多重对齐目标,而无需强化学习(RL)方法。主要思想是将语言建模与奖励建模结合起来,直接训练不同的语言模型以隐式表征不同的集体奖励模型,从而实现多个目标的整合。
MODPO的推导
MODPO依赖于以下理论关系,将目标模型与最优语言模型连接起来:
其中,是配分函数。通过利用偏好数据集,可以去除配分函数,从而实现如下变化:
结合上面的两个公式,MODPO可以构造一个实用的最大似然目标:
其中期望以为基础。
MODPO的实施步骤
MODPO的实施过程包括以下步骤:
- 边际奖励建模:首先在数据集上训练边际奖励模型。
- 语言建模:根据不同的权重迭代遍历,对每一个权重优化目标以获得经验前沿。
这些步骤的设计使得MODPO在处理多个目标时只需最小的开销,相比DPO只有轻微的追加计算需求,同时保证了训练的稳定性与效率。
MODPO的优势
MODPO通过以下几个方面展现出其优势:
- 稳定性:MODPO和DPO在本质上解决的是相同的二元分类问题,因此在训练动态上没有显著区别。
- 效率:MODPO只需获得已拟合的边际奖励模型,可来自公共源或一次预训练,降低了每个LM的训练成本。
通过这些实施步骤和优势分析,MODPO展示了在多目标对齐中具备可行性和效率,是对传统RLHF方法的有益补充。
实验
实验部分主要围绕两个关键问题展开:MODPO是否能够利用现有的人类反馈数据集为各种人类偏好创建语言模型前沿?MODPO是否能在生成语言模型前沿方面超越其他基线方法?为此,研究者在安全对齐和长篇问答这两个任务上进行了实验。
实验设置
在实验中,所有语言模型使用8个Nvidia 80G A100 GPU进行训练,整体采用LoRA技术。实验的主要评估指标是两个对齐目标之间的权衡,表现为所取得的真实奖励前沿。此外,还考虑最小化KL散度作为额外目标,以便评估在比较MODPO与其他方法时所取得的奖励和KL散度。
在安全对齐任务中,使用了10k子集的BEAVER TAILS数据集,通过使用GPT-3.5和GPT-4评估模型表现。长篇问答任务则使用QA-FEEDBACK数据集,其中包含人为偏好的多维反馈。
安全对齐实验结果
在安全对齐实验中,使用了合成反馈和真实反馈两个来源。合成反馈设置下,MODPO产生的前沿无论在高β(0.1)还是低β(0.5)条件下,均表现出色,与MORLHF相当(图2)。MODPO的性能在“有用性”维度上一般更佳,在“无害性”维度上MORLHF略有优势。
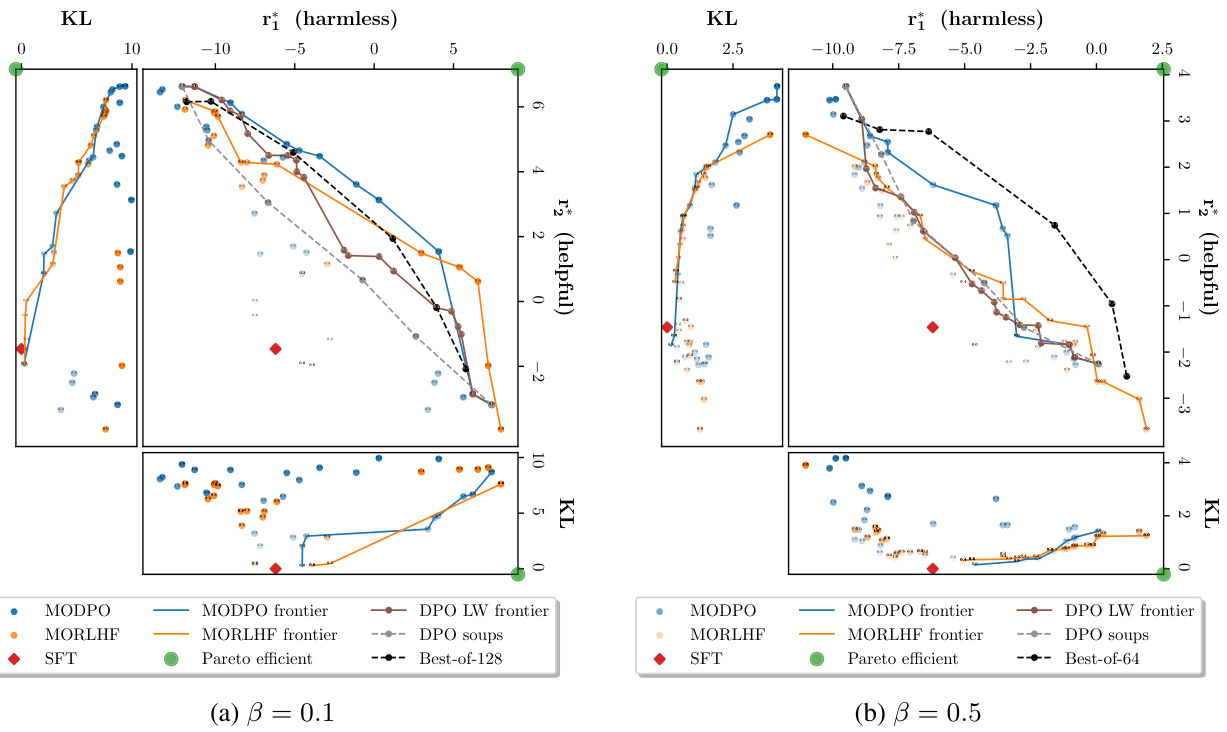
图2: 在不同β下的(合成)安全对齐前沿。MODPO在权衡有用性和无害性方面表现出色。
长篇问答实验结果
在长篇问答任务的实验中,MODPO始终在相似的KL预算下超越了MORLHF,特别是在使用不同的数据集组合时(图3)。这种表现得益于MODPO在学习过程中处理细微差别的能力。
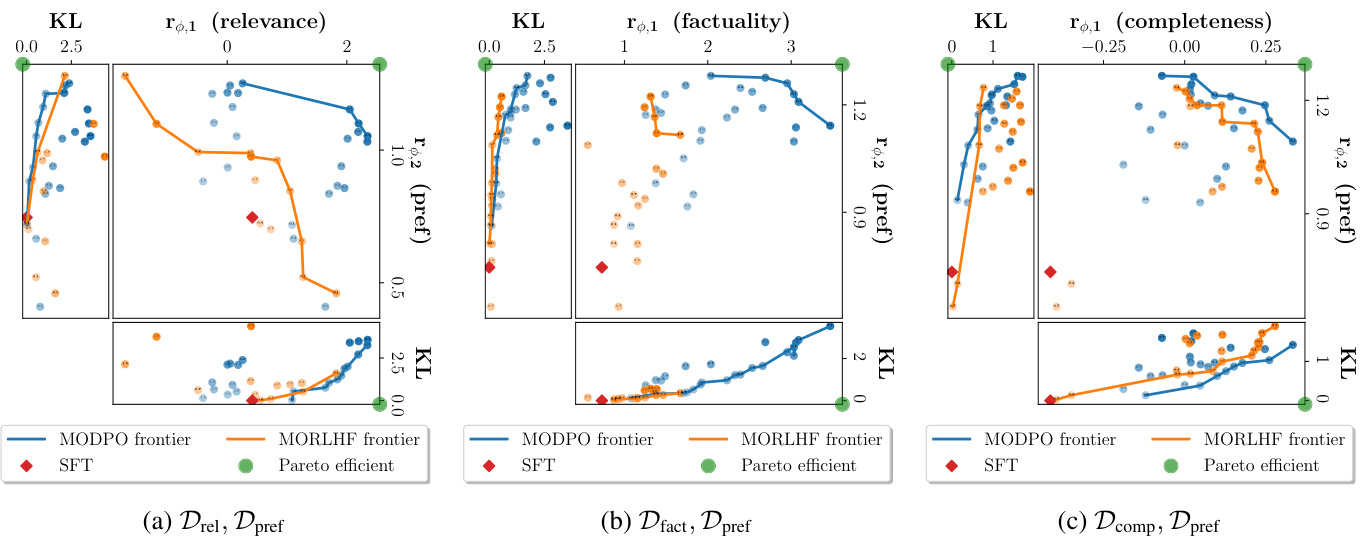
图3: 长篇问答前沿(β=0.5)。MODPO在类似的KL预算下始终超越MORLHF。
在真实反馈下的安全对齐实验中,MODPO展现出了更优的前沿,同时要求的GPU时间也相对较少(表1)。
| 模型 | 训练所需GPU小时 |
|---|---|
| MODPO | 具体小时数 |
| MORLHF | 具体小时数 |
最终实验结果
实验结果进一步表明,MODPO无论是在安全对齐还是长篇问答任务中,均能产生高效且多样的语言模型前沿,体现出其在处理多任务、多目标对齐的优越性能。
结论
在这篇论文中,作者提出了一种名为多目标直接偏好优化(MODPO)的方法,旨在解决通过人类反馈对语言模型进行对齐时的复杂性与效率问题。MODPO是对直接偏好优化(DPO)的扩展,能够在没有强化学习(RL)的情况下对多个对齐目标进行优化。与多目标强化学习(MORLHF)相比,MODPO在理论上可以产生相同的最优解,但在实践中具有更高的稳定性和效率。
研究结果显示,MODPO能够通过简单的交叉熵损失,稳定地训练出能够满足人为偏好的语言模型,并且在多个任务上表现良好。特别是在安全对齐与长形式问答任务中,MODPO的效果与现有方法相当,甚至超出它们,且在计算资源上节省了三倍。这种方法能够产生多样化的语言模型前沿,使其能够适应不同群体的偏好。
作者强调,MODPO不仅在生成模型的对齐中展现出良好的灵活性,还保证了模型的可定制性,对于处理不同的人类偏好而言,MODPO是一种有效且易于实现的方法。此外,如果目标偏好已知,开发者可以使用偏好向量作为可调超参数,方便地定制单一语言模型,使得MODPO在多目标对齐的背景下,显得尤为有效与普适。
动机
随着现代Transformer模型的快速发展,语言模型(LM)在对人类偏好的对齐方面取得了显著的进展。传统的对齐方法通常依赖于通过人类反馈进行的强化学习(RLHF),使用单一的奖励模型来代表大多数标签者的偏好,将语言模型引导到最大化该奖励模型。然而,这种方法基于一个假设,即人类的偏好是同质的,实际情况是偏好的多样性和复杂性使得单一模型难以满足所有用户的需求。
为了克服这种限制,近年来的研究转向多策略的方法,通过解析人类反馈中的多个维度,创建独立的奖励模型以满足不同的偏好。这种多目标强化学习(MORLHF)方法在训练中引入了复杂的奖励权重,但由于各目标之间往往存在冲突,导致了训练过程的不稳定和计算资源的高消耗。研究者们希望找到一种更加稳定且高效的方法来进行多目标对齐。
本研究提出了多目标直接偏好优化(MODPO),该方法不依赖于RL,而是将语言建模直接整合进奖励建模。MODPO通过在训练语言模型的过程中,同时考虑多个目标的最终奖励,确保模型能够满足多样化的偏好。这种方法使得语言模型能够在处理复杂的人类反馈时保持高效,且避免了MORLHF所带来的计算负担。
通过这种创新性的写作方法,MODPO不仅在理论上与MORLHF相当,而且在实际应用中展示出了更好的稳定性和效率。研究结果表明,MODPO在安全性对齐和长文本问答等任务上,能够与现有方法相匹配或超越,同时使用的计算资源要低得多。这为个性化和针对不同用户偏好的语言模型的开发提供了一种新的解决方案。
方法
为了解决人类偏好的多样性及使用强化学习(RL)优化多个目标的复杂性,本文提出了多目标直接偏好优化(Multi-Objective Direct Preference Optimization,MODPO)。MODPO是DPO(直接偏好优化)的稳定高效扩展,可以在无需RL的情况下精确优化多个目标。其核心思想是在训练参数化的集体奖励模型时,利用线性标量化直接获取不同权重下的奖励模型,从而生成可用于实际部署的语言模型前沿。
根据MODPO的理论映射,给定一个权重向量🅌和一个目标集体奖励模型𝑤𝑇𝑟∗,最优语言模型𝜋(𝑤𝑇𝑟∗)与集体奖励模型之间存在以下关系:
其中𝑍(𝑥)为分区函数:
由于分区函数通常不适合直接优化,MODPO通过使用偏好数据集𝓓k来消除分区函数的影响,从而实际构造最大似然目标:
其中,𝑦𝑤为首选回应的索引,𝑦𝑙为不受欢迎回应的索引,而ℓ_{D}为边际奖励模型的输出。
MODPO方法论
MODPO的主要步骤包括:
- 边际奖励建模:基于𝓓_{-k}的数据集进行边际奖励模型训练。
- 语言建模:对权重𝑤进行迭代优化,将𝓓_{k}的数据集应用于最大似然目标来获得语言模型集合。
MODPO的优势
MODPO在处理多个目标时的开销仅相对于DPO具有极小的附加消耗,主要优势包括:
- 稳定性:ℓ_{MODPO}和ℓ_{DPO}基本上解决相同的二分类问题,因此在训练动态上没有显著差异。
- 效率:MODPO仅需要已拟合的边际奖励模型,而训练边际奖励模型的成本可以通过公共来源或预训练一次性进行摊薄,减少了每个LM的训练成本。
以上步骤保证了MODPO在多目标对齐情况下的稳定性和效率,同时保持了DPO在同质偏好对齐时的可行性。整体上,MODPO方法为生成符合多样倾向的定制化语言模型提供了有效且可操作的解决方案。
实验
在本节中,作者旨在回答两个关键问题:MODPO能否利用现有的人类反馈数据集生成新语言模型以满足不同人类偏好?MODPO能否在生成语言模型前沿方面超越其他基线方法?
实验设置
在实验中,作者主要关注优化两个对齐目标,数据库设置为,并通过不同的偏好权重向量生成一系列语言模型。性能通过比较生成的前沿来评估。
研究的任务包括安全对齐和长文本问答。在安全对齐任务中,目的是在模型的无害性和有用性之间取得平衡。使用了 B EAVER T AILS 数据集的10k子集,该数据集提供了每个问答对的无害性和有用性的人类偏好。在长文本问答任务中,模型需要根据给定的维基背景生成答案,旨在生成符合人类偏好的答案。使用了 QA-F EEDBACK 数据集,该数据集包含对人类偏好的标注和元标记,鼓励模型生成相关性、事实性和完整性的内容。
MODPO 细节
在两个任务中,作者首先从 中获取边际奖励 。然后,依据不同的偏好权重 ,使用 优化语言模型以获得经验前沿 。
基线
研究中考虑的主要基线包括 MORLHF 和 Best-of 方法。为安全对齐任务,作者还研究了 DPO 派生的两个多目标扩展方法,即 DPO soups 和 DPO LW。
评估
主要评估指标是在两个对齐目标之间的权衡情况,由获得的真实奖励前沿 vs. 表示。为了更加全面的比较,作者同时评估了各方法在 KL 发散上的表现。
安全对齐
在合成反馈设置下,MODPO 生成的 vs. 前沿与 MORLHF 相当,在高 (β=0.1) 和低 (β=0.5) KL 范围内表现均佳。MODPO 在无用性维度的表现普遍优于 MORLHF,而在无害性维度则稍逊一筹。实际人类偏好的评估显示 MODPO 和 MORLHF 的胜率相似,进一步展示了 MODPO 的人类反馈插值能力。
图 2:不同 下的安全对齐前沿。MODPO 生成的前沿表现出竞争力,在有用性和无害性之间进行良好权衡。
长文本问答
在长文本问答任务中,MODPO 的表现优于 MORLHF,尤其是在区分相关性、事实性和完整性方面。即使在与 结合的情况下,MODPO 也始终能够维护生成质量与相关性之间的平衡。
图 3:长文本问答前沿 (β=0.5)。MODPO 一直优于 MORLHF,在相似的 KL 预算下生成效果更加稳定。
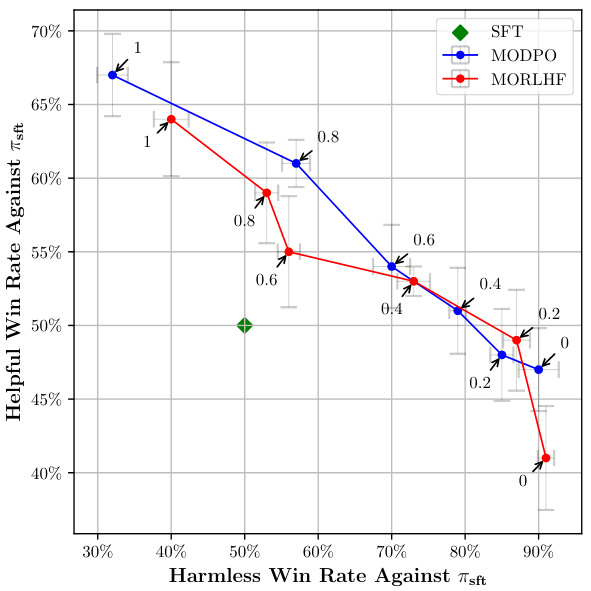
图 4:真实的安全对齐前沿 (β=0.1),通过 GPT-3.5 和 GPT-4 进行评估。MODPO 展现出比 MORLHF 更好的前沿表现,且训练所需 GPU 时间更少。
实验结果
对于每种方法,作者执行多次训练运行,并通过改变 来获取均匀分布的前沿。在安全对齐的合成反馈下,MODPO 在无用性和无害性之间的前沿良好覆盖。长文本问答中,MODPO 的每个前沿都表明其在应对多重目标时的适应性。整体而言,MODPO 超越了传统的多目标强化学习方法,展示了其在生成定制化语言模型方面的潜力。
结论
本文提出了多目标直接偏好优化(MODPO),作为一种无强化学习的方法,扩展了直接偏好优化(DPO)以支持多种对齐目标。MODPO 在理论上与多目标强化学习从人类反馈(MORLHF)等效,但在实际应用中更为高效。与复杂的强化学习管道相比,MODPO 通过简单的交叉熵损失优化语言模型,表现出了良好的经验结果,适用于多个任务。
MODPO 的灵活性和效率使其能够生成适应多样化人类偏好的语言模型,使模型可根据特定目标进行定制。在实验中,MODPO 显示出在应对人类反馈、优化对齐目标上均能超越或匹敌现有的方法,包括 MORLHF。其训练的语言模型前沿模型展示了出色的自定义能力,能够覆盖多样的用户需求。
因此,MODPO 不仅提供了一种响应多样化人类偏好的实用框架,同时也为未来在无监督、灵活的语言模型对齐方面的研究指明了方向。这一方法的有效性为大规模应用的语言模型定制化提供了一个高效、理想的解决方案,展现出了良好的可扩展性和适应性。